





1.文本分布式表示
1.1 为什么要表示成分布式
1.1.1 词向量的one-hot表示
我们拿英文举例。
英语中大约有1300万个词组(token,自定义字符串,译作词组),不过他们全部是独立的吗?并不是
哦,比如有一些词组,“Feline猫科动物”和“Cat猫”,“Hotel宾馆“和”Motel汽车旅馆”,其实有一定的关联
或者相似性在。因此,我们希望用词向量编码词组,使它代表在词组的N维空间中的一个点(而点与点
之间有距离的远近等关系,可以体现深层一点的信息)。每一个词向量的维度都可能会表征一些意义
(物理含义)。例如,语义维度可以用来表明时态(过去与现在与未来),计数(单数与复数),和性
别(男性与女性)。
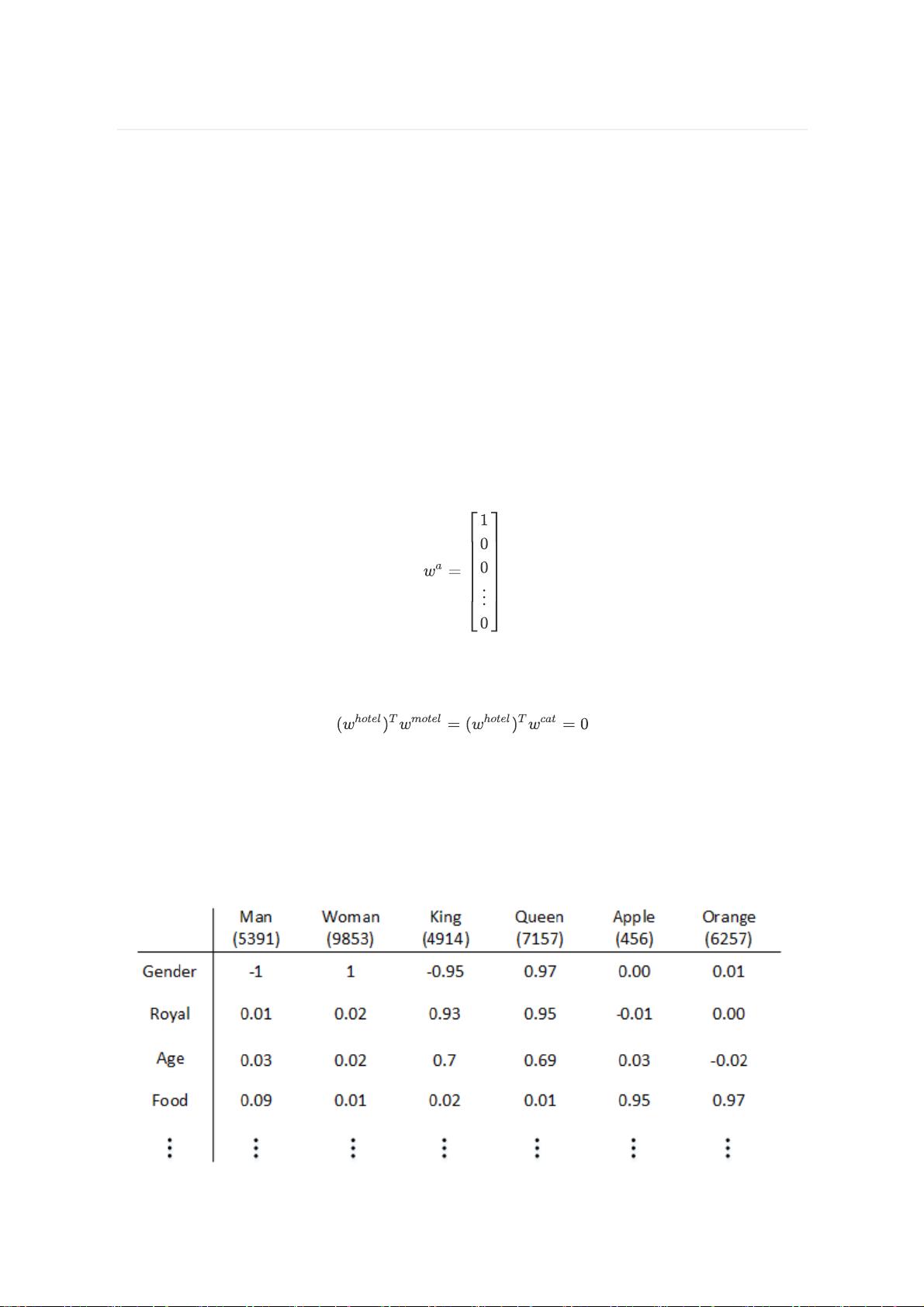
说起来,词向量的编码方式其实挺有讲究的。咱们从最简单的看起,最简单的编码方式叫做one-hot
vector:假设我们的词表(vocabulary)总共有n个词,那我们开一个1*n的高维向量,而每个词都会在
某个索引index下取到1,其余位置全部都取值为0.词向量在这种类型的编码中如下图所示:
这种词向量编码方式简单粗暴,我们将每一个词作为一个完全独立的个体来表达。遗憾的是,这种方式
下,我们的词向量没办法给我们任何形式的词组相似性权衡。例如:
究其根本你会发现,是你开了一个极高维度的空间,然后每个词语都会占据一个维度,因此没有办法在
空间中关联起来。因此我们可能可以把词向量的维度降低一些,在这样一个子空间中,可能原本没有关
联的词就关联起来了。
1.1.2 词的分布式表示
man - woman ≈ [-2,0,0,0,...]
Apple - Orange ≈ [0,0,0,0,...]














