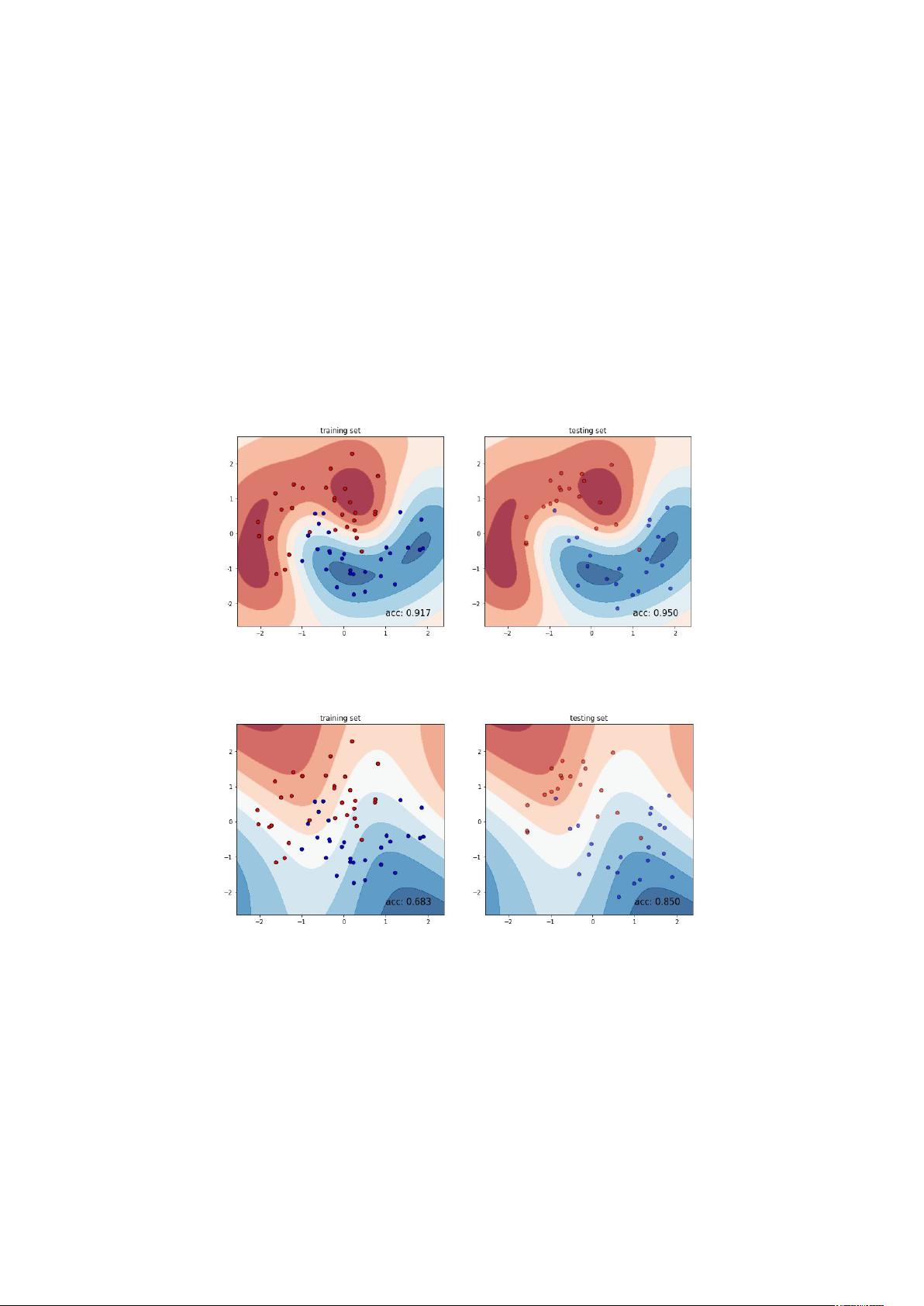
引进核函数的原因:解决线性不可分问题时,需要把样本值映射到高维空
间,在这个高维空间内使用分类问题的方法时,要计算向量内积,核函数可将
求高维向量内积转为求低维向量内积,降低运算复杂度。
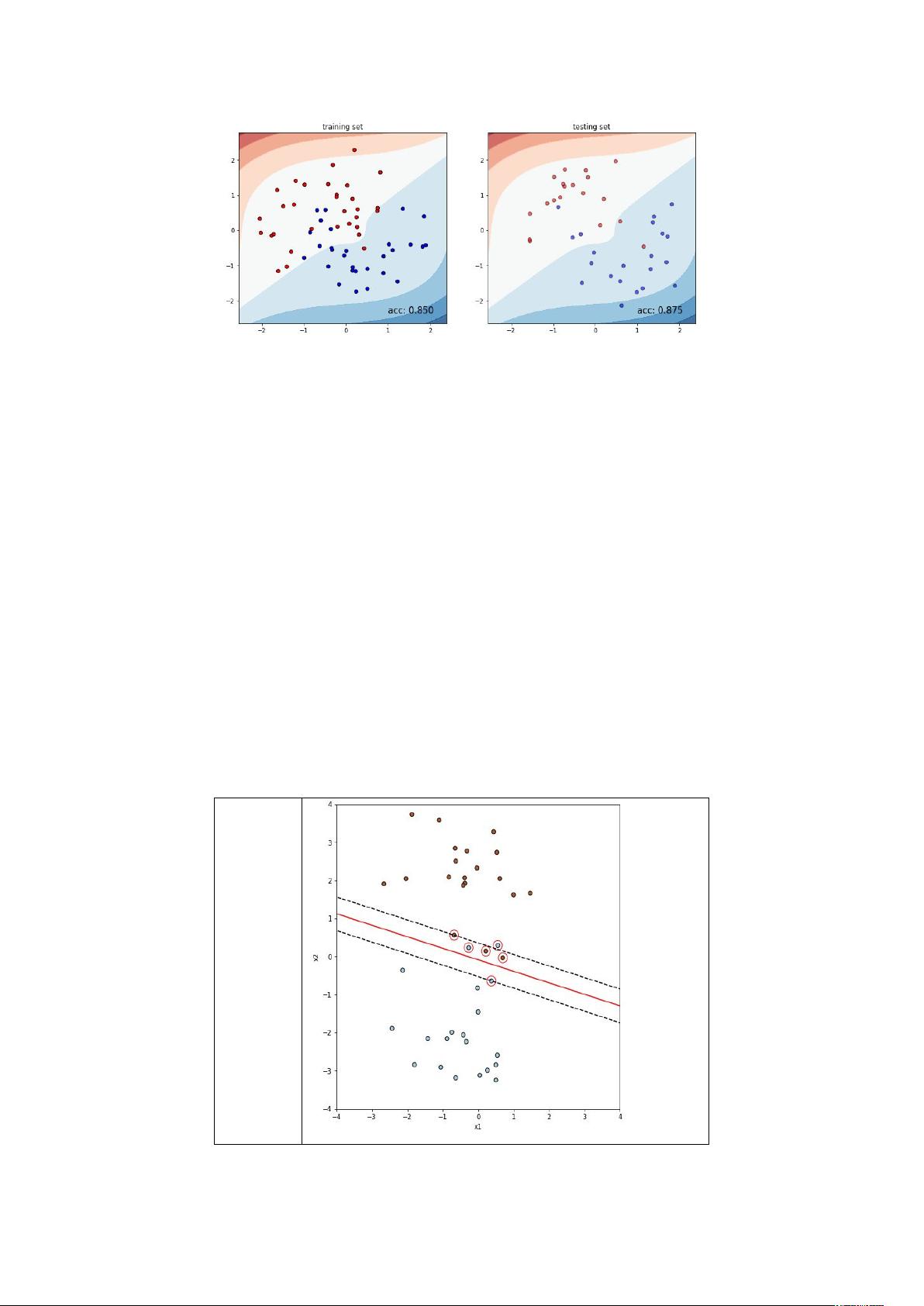
实验 2:使用线性核,调整 C 的值,绘制数据集,SVM 分离超平面,间
隔超平面以及支持向量。阐述软间隔的作用。
软间隔的作用:核函数使样本在更高维可分,但有出现过拟合的风险,为
避免这一风险,引入软间隔,允许少量的样本分类出错,但这些样本又需尽可
能的少。 C 是正则化常数,当 C 越大时其支持向量机的容错范围越小。
调整 C 的值,绘制 SVM 分离超平面如下:
C=10