Java 多线程与并发(13-26)-JUC集合- ConcurrentHashMap详解.pdf
106 浏览量
2023-07-26
18:25:21
上传
评论
收藏 553KB PDF 举报


Java
多
线
程
与
并
发
(13/26)-JUC
集
合
:
ConcurrentHashMap
详
解
JUC
集
合
:ConcurrentHashMap
详
解
JDK1.7
之
前
的
ConcurrentHashMap
使
⽤
分
段
锁
机
制
实
现
,
JDK1.8
则
使
⽤
数
组
+
链
表
+
红
⿊
树
数
据
结
构
和
CAS
原
⼦
操
作
实
现
ConcurrentHashMap
;
本
⽂
将
分别
介
绍
这
两
种
⽅
式
的
实
现
⽅
案
及
其
区
别
。
带
着
BAT
⼤
⼚
的
⾯
试
问
题
去
理
解
提
⽰
请
带
着
这
些
问
题
继续
后
⽂
,
会
很
⼤
程
度
上
帮
助
你
更
好
的
理
解
相
关
知
识
点
。
•
为什么
HashTable
慢
?
它
的
并
发
度
是
什么
?
那
么
ConcurrentHashMap
并
发
度
是
什么
?
•
ConcurrentHashMap
在
JDK1.7
和
JDK1.8
中
实
现
有
什么
差
别
?JDK1.8
解
決
了
JDK1.7
中什么
问
题
•
ConcurrentHashMapJDK1.7
实
现
的
原
理
是
什么
?
分
段
锁
机
制
•
ConcurrentHashMapJDK1.8
实
现
的
原
理
是
什么
?
数
组
+
链
表
+
红
⿊
树
,
CAS
•
ConcurrentHashMapJDK1.7
中
Segment
数
(concurrencyLevel)
默
认
值
是
多
少
?
为
何
⼀
旦
初
始
化
就
不
可
再
扩
容
?
•
ConcurrentHashMapJDK1.7
说说
其
put
的
机
制
?
•
ConcurrentHashMapJDK1.7
是
如
何
扩
容
的
?rehash(
注
:
segment
数
组
不
能
扩
容
,
扩
容
是
segment
数
组
某
个
位
置
内
部
的
数
组
HashEntry<K,V>[]
进
⾏
扩
容
)
•
ConcurrentHashMapJDK1.8
是
如
何
扩
容
的
?tryPresize
•
ConcurrentHashMapJDK1.8
链
表
转
红
⿊
树
的
时
机
是
什么
?
临
界
值
为什么
是
8?
•
ConcurrentHashMapJDK1.8
是
如
何
进
⾏
数
据
迁
移
的
?transfer
为什么
HashTable
慢
Hashtable
之
所
以
效
率
低
下主
要
是
因
为
其
实
现
使
⽤
了
synchronized
关
键
字
对
put
等
操
作
进
⾏
加
锁
,
⽽
synchronized
关
键
字
加
锁
是
对
整
个
对
象
进
⾏
加
锁
,
也
就
是
说
在
进
⾏
put
等
修
改
Hash
表
的
操
作
时
,
锁
住
了
整
个
Hash
表
,
从
⽽
使
得
其
表
现
的
效
率
低
下
。
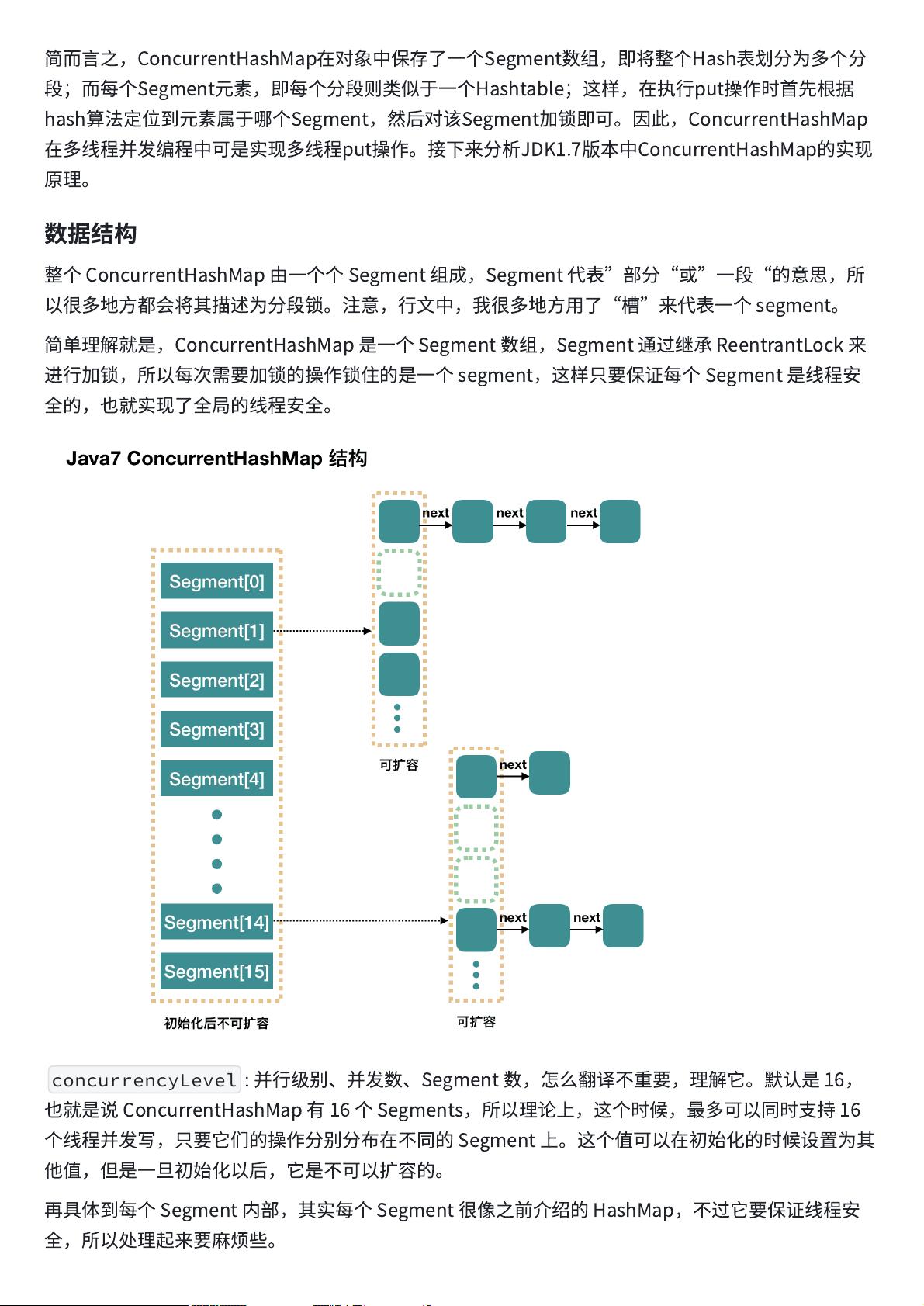
ConcurrentHashMap-JDK1.7
在
JDK1.5~1.7
版
本
,
Java
使
⽤
了
分
段
锁
机
制
实
现
ConcurrentHashMap.



剩余23页未读,继续阅读
资源评论













