纵横小说网站数据采集与分析
背景与目的意义
随着数字化时代的到来,网络小说已经成为了国内文学市场中的重要组成部分,并且在
不断的扩大其市场份额。其中,纵横中文网作为国内最具影响力的网络小说平台之一,一直
以来受到了读者和写手的热烈追捧。对于爱好网络小说的读者们来说,纵横中文网不仅提供
了大量的小说作品,还提供了免费的在线阅读服务,为人们的阅读需求提供了极大的帮助。
同时,作为网络小说文学市场中的主要参与者之一,纵横中文网对于触达同行和读者,以及
市场调研和更新优化都有着极大的作用。
针对上述情况,本次设计提出了一个基于 python 的纵横中文网站数据采集与分析研究
项目。其主要目的如下:
1. 了解网络小说行业的市场情况:针对纵横中文网站的各种数据进行收集、统计、分
析,掌握网站中小说类别、点击量、评论数、月票数、阅读量等数据的情况,分析不同小说
类别的市场状况,探究行业发展趋势。
2. 掌握读者需求和偏好:通过对读者类别、点击数等数据的分析,掌握读者对于小说
作品的喜好和需求,为作家创作提供参考意见。
3. 评估小说作品质量:根据小说作品的点击量、阅读量等相关数据,建立起小说作品
的质量评估系统并进行数据分析和统计。
4. 协助网站运营:根据网站数据进行各类数据分析及市场调研,协助网站运营、小说
作者和阅读者制定更为准确和有效的市场推广、运营策略。
综上所述,纵横中文网站数据采集与分析研究的主要目的是为了了解网络小说行业的市
场情况,掌握读者需求和偏好,并评估小说作品质量,为网站运营和小说作者提供参考意见,
从而提高整个网站的服务质量和市场竞争力。
技术介绍
在纵横小说网站数据采集与分析研究中,主要使用到了以下技术:
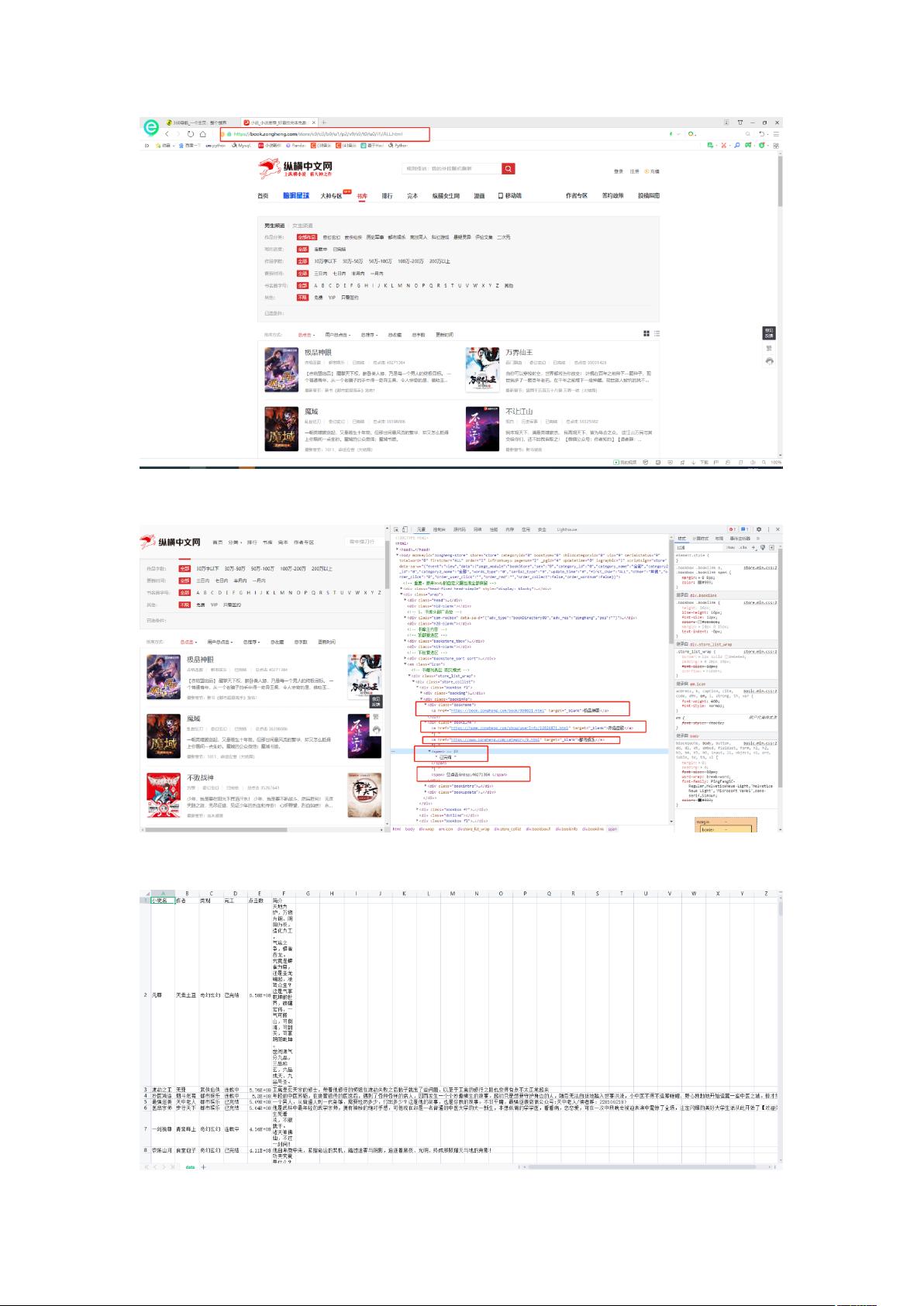
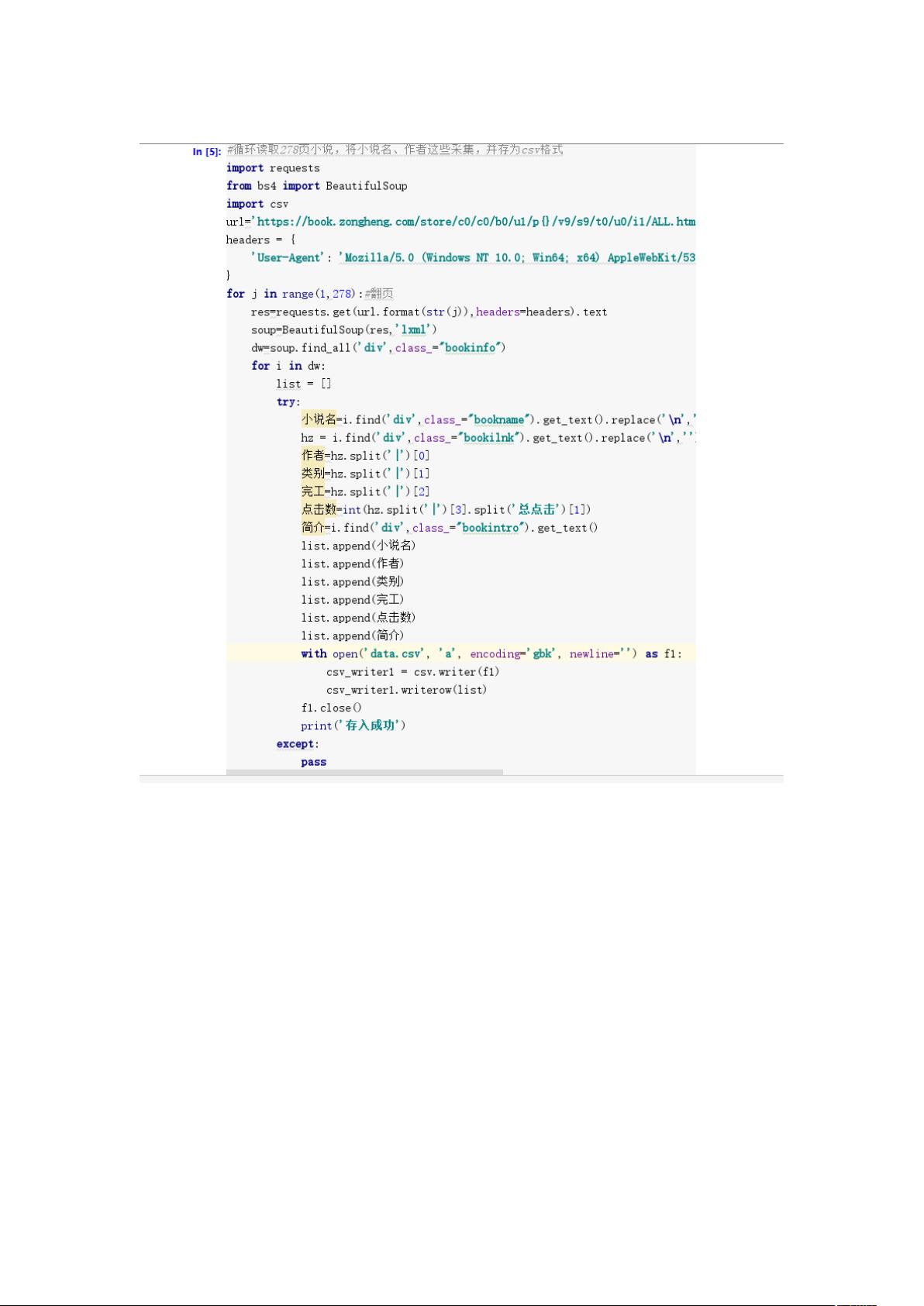
1. 爬虫技术:采用 requests、BeautifulSoup 等开源的 python 爬虫框架进行数据采集。
通过模拟浏览器行为获取网站数据,包括小说作品信息、读者评论、评分等内容。
2. 数据处理和分析技术:对采集到的数据进行清洗、整理和存储。使用 Pandas 等 python
数据分析库对数据进行处理和分析,完成各种统计、可视化和数据挖掘任务。
3. 可视化技术:使用 Matplotlib 数据可视化工具对数据进行可视化,生成各种图表和图
形,以便更好地展示数据分析结果。
4. 随机森林算法:采用随机森林算法对小说作品进行质量评估。将小说作品的点击量、
类别等数据作为训练数据,利用随机森林算法建立质量评估模型,对新的小说作品进行评估。
在数据采集中,本文主要采用 request 库爬虫框架,模拟浏览器行为获取网站数据。针
对不同类型的数据,本文采用 BeautifulSoup 等解析库进行解析,将数据提取出来并进行清
洗和存储。