




我们希望这篇文章能够促进大型语言模型的透明度,成为开源社区共同努力
复现 GPT-3.5 的路线图。
致国内的同胞们:
在国际学术界看来,ChatGPT / GPT-3.5 是一种划时代的产物,它与之前常
见的语言模型 (Bert/ Bart/ T5) 的区别,几乎是导弹与弓箭的区别,一定要引
起最高程度的重视。
在我跟国际同行的交流中,国际上的主流学术机构 (如斯坦福大学,伯克利加
州大学) 和主流业界研究院(如谷歌大脑,微软研究院)都已经全面拥抱大模
型。
在当前这个阶段,国内的技术水准,学术视野,治学理念和国际前沿的差距似
乎并没有减少,反而正在扩大,如果现状持续下去,极有可能出现技术断代。
此诚危急存亡之秋。
多年以后,面对行刑队,奥雷里亚诺·布恩迪亚上校将会回想起父亲带他
去见识冰块的那个遥远的下午。——
《百年孤独》
加西亚·马尔克斯
一、2020版初代GPT-3与大规模预训练
初代GPT-3展示了三个重要能力:
语言生成:遵循提示词(prompt),然后生成补全提示词的句子。这也是今
天人类与语言模型最普遍的交互方式。
上下文学习 (in-context learning): 遵循给定任务的几个示例,然后为新的
测试用例生成解决方案。很重要的一点是,GPT-3虽然是个语言模型,但它的
论文几乎没有谈到“语言建模” (language modeling) —— 作者将他们全部的
写作精力都投入到了对上下文学习的愿景上,这才是 GPT-3的真正重点。
世 界 知 识 : 包 括 事 实 性 知 识 (factual knowledge) 和 常 识
(commonsense)。
那么这些能力从何而来呢?
基本上,以上三种能力都来自于大规模预训练:在有3000亿单词的语料上预
训练拥有1750亿参数的模型( 训练语料的60%来自于 2016 - 2019 的 C4
+ 22% 来 自 于 WebText2 + 16% 来 自 于 Books + 3% 来 自 于
Wikipedia)。其中:
语言生成的能力来自于语言建模的训练目标 (language modeling)。
世界知识来自 3000 亿单词的训练语料库(不然还能是哪儿呢)。
模型的 1750 亿参数是为了存储知识,Liang et al. (2022) 的文章进一步证明
了这一点。他们的结论是,知识密集型任务的性能与模型大小息息相关。
上下文学习的能力来源及为什么上下文学习可以泛化,仍然难以溯源。 直觉
上,这种能力可能来自于同一个任务的数据点在训练时按顺序排列在同一个
batch 中。然而,很少有人研究为什么语言模型预训练会促使上下文学习,以
及为什么上下文学习的行为与微调 (fine-tuning) 如此不同。
令人好奇的是,初代的GPT-3有多强。其实 比 较 难确定初代 GPT-3 (在
OpenAI API 中被称为 davinci )到底是“强”还是“弱”。一方面,它合理地回
应了某些特定的查询,并在许多数据集中达到了还不错的性能;另一方面,
它在许多任务上的表现还不如 T5 这样的小模型(参见其原始论文)。在今
天(2022 年 12 月)ChatGPT 的标准下,很难说初代的 GPT-3 是“智能
的”。Meta 开源的 OPT 模型试图复现初代 GPT-3,但它的能力与当今的标
准也形成了尖锐的对比。许多测试过 OPT 的人也认为与现在的 text-davinc
i-002 相比,该模型确实 “不咋地”。尽管如此,OPT 可能是初代 GPT-3 的
一个足够好的开源的近似模型了(根据 OPT 论文和斯坦福大学的 HELM 评
估)。
虽然初代的 GPT-3 可能表面上看起来很弱,但后来的实验证明,初代 GPT-
3 有着非常强的潜力。这些潜力后来被代码训练、指令微调 (instruction
tuning) 和 基 于 人 类 反 馈 的 强 化 学 习 (reinforcement learning with
human feedback, RLHF) 解锁,最终体展示出极为强大的突现能力。
二、从2020版GPT-3到2022版ChatGPT
从最初的 GPT-3 开始,为了展示 OpenAI 是如何发展到ChatGPT的,我们
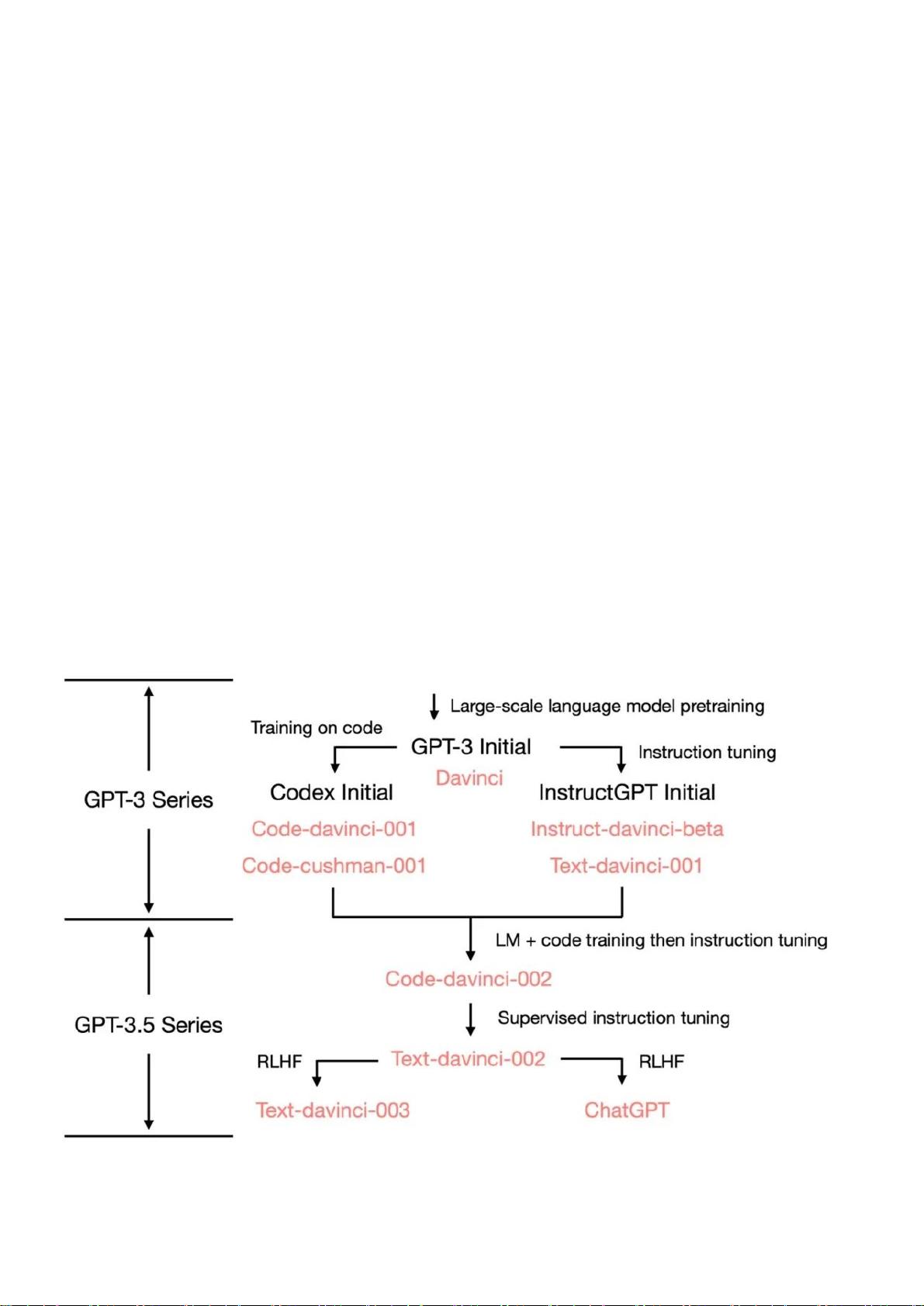
看一下 GPT-3.5 的进化树:

在 2020 年 7 月,OpenAI 发布了模型索引为的 davinci 的初代 GPT-3
论文,从此它就开始不断进化。在 2021 年 7 月,Codex 的论文发布,其中
初始的 Codex 是根据(可能是内部的)120 亿参数的 GPT-3 变体进行微调
的。后来这个 120 亿参数的模型演变成 OpenAI API 中的 code-cushman-0
01 。在 2022 年 3 月,OpenAI 发布了指令微调 (instruction tuning) 的
论文,其监督微调 (supervised instruction tuning) 的部分对应了 davinci
-instruct-beta 和 text-davinci-001 。 在 2022 年 4 月 至 7 月 的 ,
OpenAI 开 始 对 code-davinci-002 模 型 进 行 Beta 测 试 , 也 称 其 为
Codex。然后 code-davinci-002 、 text-davinci-003 和 ChatGPT 都是从
code-davinci-002 进行指令微调得到的。详细信息请参阅 OpenAI的模型索
引文档。
尽管 Codex 听着像是一个只管代码的模型,但 code-davinci-002 可能是最
强 大 的 针 对 自 然 语 言 的 GPT-3.5 变 体 ( 优 于 text-davinci-002
和 -003 )。 code-davinci-002 很可能在文本和代码上都经过训练,然后根
据指令进行调整(将在下面解释)。然后2022 年 5-6 月发布的 text-davin
ci-002 是 一 个 基 于 code-davinci-002 的 有 监 督 指 令 微 调 (supervised
instruction tuned) 模型。在 text-davinci-002 上面进行指令微调很可能
降低了模型的上下文学习能力,但是增强了模型的零样本能力(将在下面解
释)。然后是 text-davinci-003 和 ChatGPT ,它们都在 2022 年 11 月发
布,是使用的基于人类反馈的强化学习的版本指令微调 (instruction tuning
with reinforcement learning from human feedback) 模型的两种不同变
体。 text-davinci-003 恢复了(但仍然比 code-davinci-002 差)一些在 t
ext-davinci-002 中丢失的部分上下文学习能力(大概是因为它在微调的时
候混入了语言建模) 并进一步改进了零样本能力(得益于RLHF)。另一方
面,ChatGPT 似乎牺牲了几乎所有的上下文学习的能力来换取建模对话历史
的能力。













