

第 1 页共 103 页
第一章 体系结构
1.1 发展历程
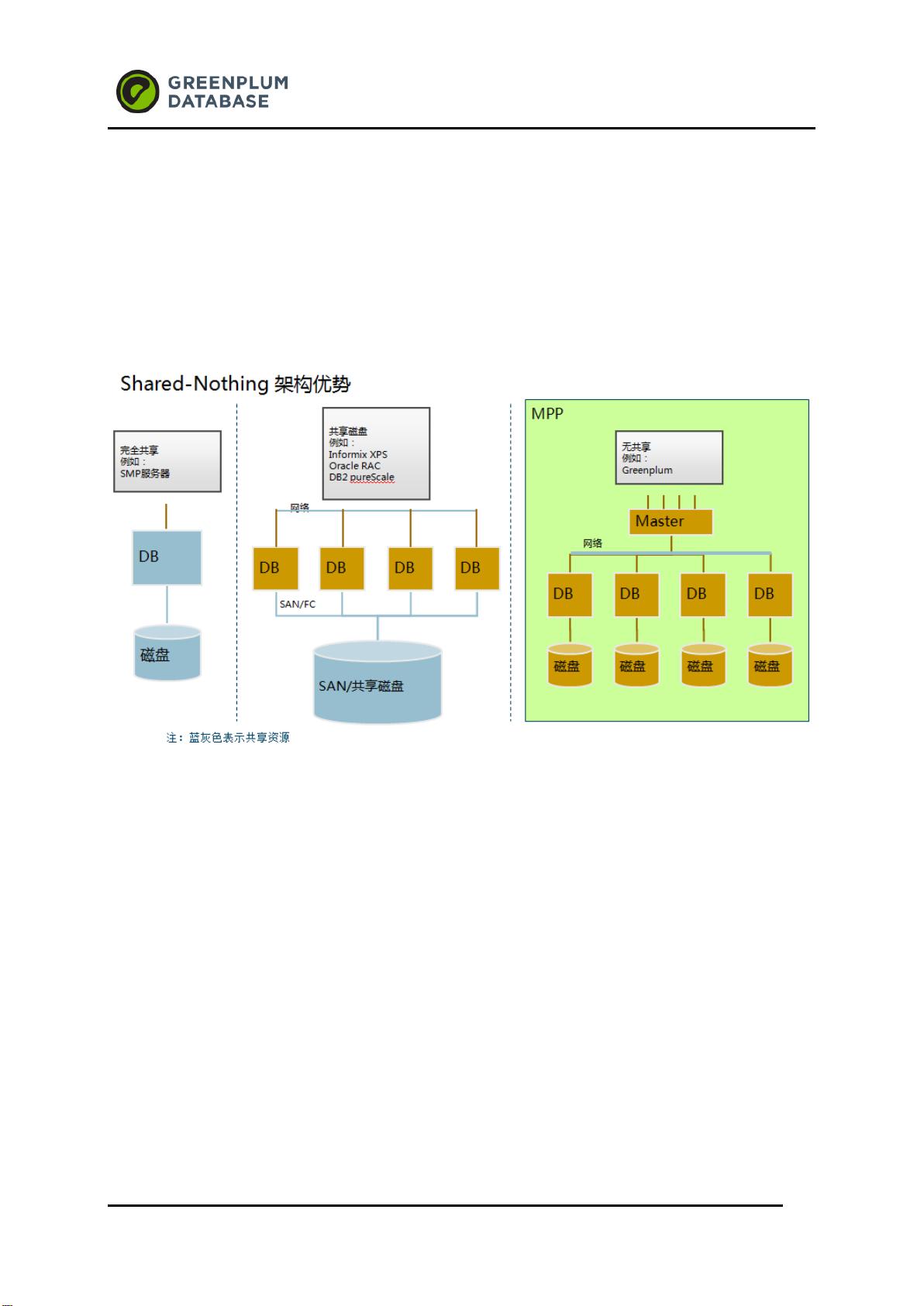
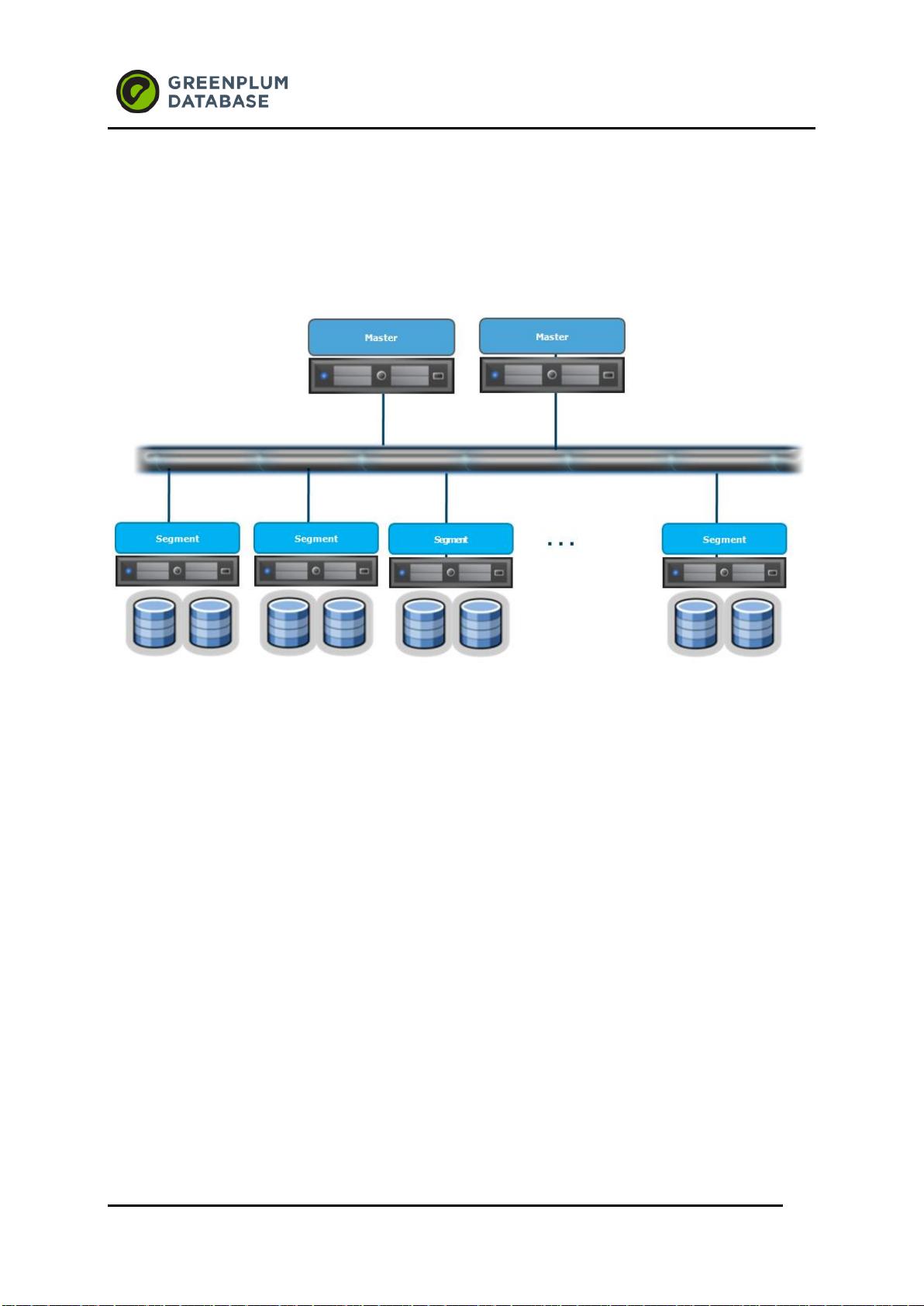
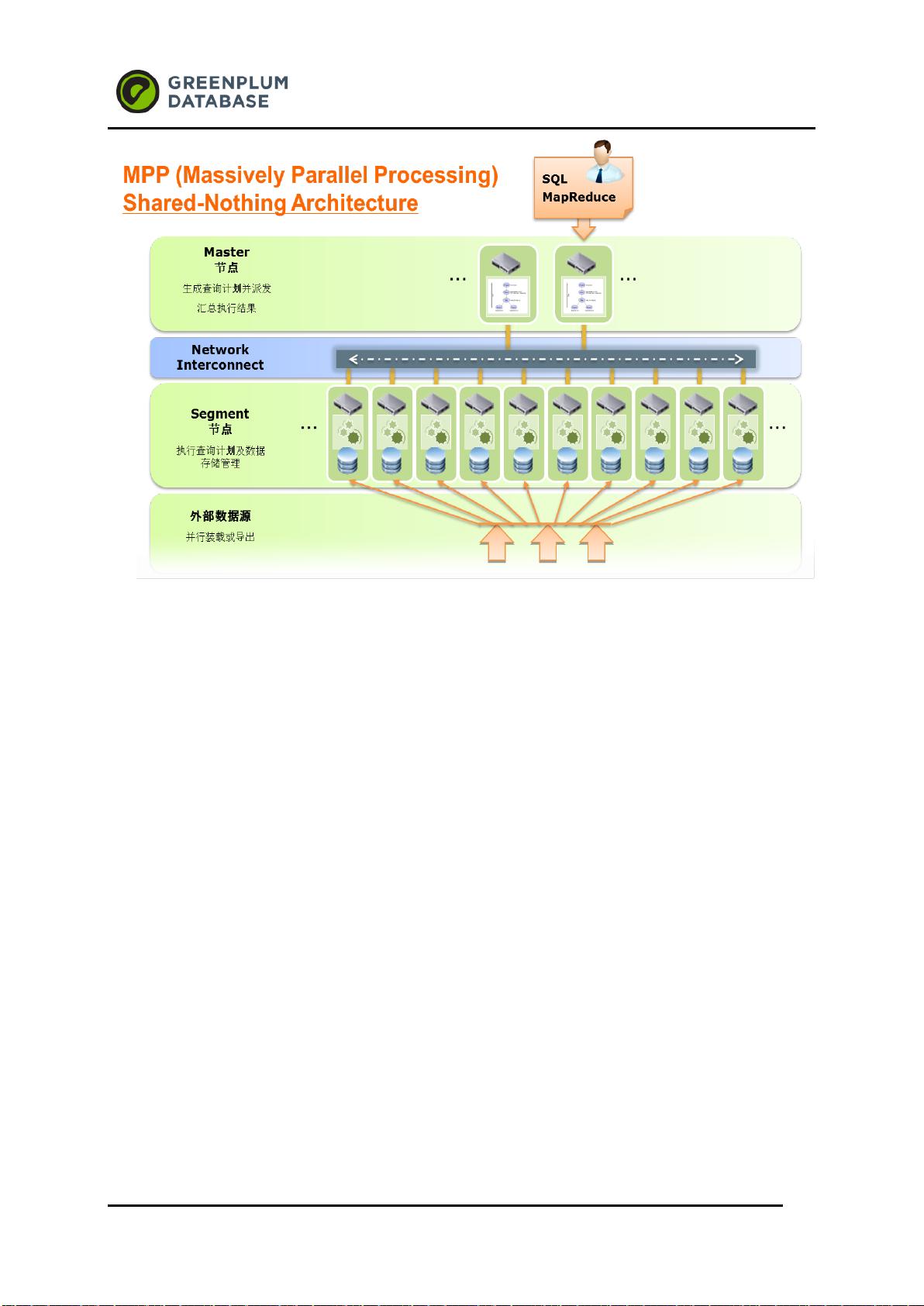
Greenplum 是 2003 年成立的,核心技术团队成员来自各个顶级数据库公司和大规模并行计
算公司的资深软件架构师, Greenplum 数据库软件是业内首创的无共享、大规模并行处理
(massivelyparallel processing (MPP))的数据库软件产品,它包含大规模并行计算技术和数据
库技术最新的研发成果:包括无共享/MPP,按列存储数据库,数据库内压缩,MapReduce,永不
停机扩容,多级容错等等。该数据库软件被业界认可为扩展能力最大的分析型(OLAP)数据库软件。
已有 100 多家世界级重大客户采用该软件,这些客户中大多数 Greenplum 数据仓库所管理的数据
量都超过 100TB,其中,全球最大的有 6500TB,中国最大的有 400TB。每一天,全球有数亿级
的用户在直接、间接用到 Greenplum 发明的数据库平台。
Greenplum 数据仓库软件是业界首创将大规模并行计算技术,应用到了数据库软件领域。该
类技术同样应用在 Google 搜索引擎的中。
主要事件参考如下:
2003 年:Greenplum 由 Scott Yara 和 Luke Lonergan 成立。
2005 年:Greenplum 数据库第一个版本发布。
2006 年:与 Sun 公司合作,成为其合伙人。
2008 年:Greenplum MapReduce 发布,同年 12 月份进入中国市场,一年多后,Greenplum
正式宣布在中国独立运营。
2010:Greenplum 被 EMC 收购,并被整合到 EMC 的云计算战略中。
2011-2012:Greenplum 社区版发布,Greenplum Chorus 发布并开源。
2013:VMware 和 EMC 联合宣布将成立合资公司 Pivotal,并将 Greenplum DB 整合过来。
2014:Greenplum 4.3 发布。

剩余102页未读,继续阅读
资源评论













