Min Lin
1,2
, Qiang Chen
2
, Shuicheng Yan
2
1
Graduate School for Integrative Sciences and Engineering
2
Department of Electronic & Computer Engineering
National University of Singapore, Singapore
{linmin,chenqiang,eleyans}@nus.edu.sg
Abstract
We propose a novel deep network structure called “Network In Network”(NIN)
to enhance model discriminability for local patches within the receptive field. The
conventional convolutional layer uses linear filters followed by a nonlinear acti-
vation function to scan the input. Instead, we build micro neural networks with
more complex structures to abstract the data within the receptive field. We in-
stantiate the micro neural network with a multilayer perceptron, which is a potent
function approximator. The feature maps are obtained by sliding the micro net-
works over the input in a similar manner as CNN; they are then fed into the next
layer. Deep NIN can be implemented by stacking mutiple of the above described
structure. With enhanced local modeling via the micro network, we are able to uti-
lize global average pooling over feature maps in the classification layer, which is
easier to interpret and less prone to overfitting than traditional fully connected lay-
ers. We demonstrated the state-of-the-art classification performances with NIN on
CIFAR-10 and CIFAR-100, and reasonable performances on SVHN and MNIST
datasets.
1 Introduction
Convolutional neural networks (CNNs) [1] consist of alternating convolutional layers and pooling
layers. Convolution layers take inner product of the linear filter and the underlying receptive field
followed by a nonlinear activation function at every local portion of the input. The resulting outputs
are called feature maps.
The convolution filter in CNN is a generalized linear model (GLM) for the underlying data patch,
and we argue that the level of abstraction is low with GLM. By abstraction we mean that the fea-
ture is invariant to the variants of the same concept [2]. Replacing the GLM with a more potent
nonlinear function approximator can enhance the abstraction ability of the local model. GLM can
achieve a good extent of abstraction when the samples of the latent concepts are linearly separable,
i.e. the variants of the concepts all live on one side of the separation plane defined by the GLM. Thus
conventional CNN implicitly makes the assumption that the latent concepts are linearly separable.
However, the data for the same concept often live on a nonlinear manifold, therefore the represen-
tations that capture these concepts are generally highly nonlinear function of the input. In NIN, the
GLM is replaced with a ”micro network” structure which is a general nonlinear function approxi-
mator. In this work, we choose multilayer perceptron [3] as the instantiation of the micro network,
which is a universal function approximator and a neural network trainable by back-propagation.
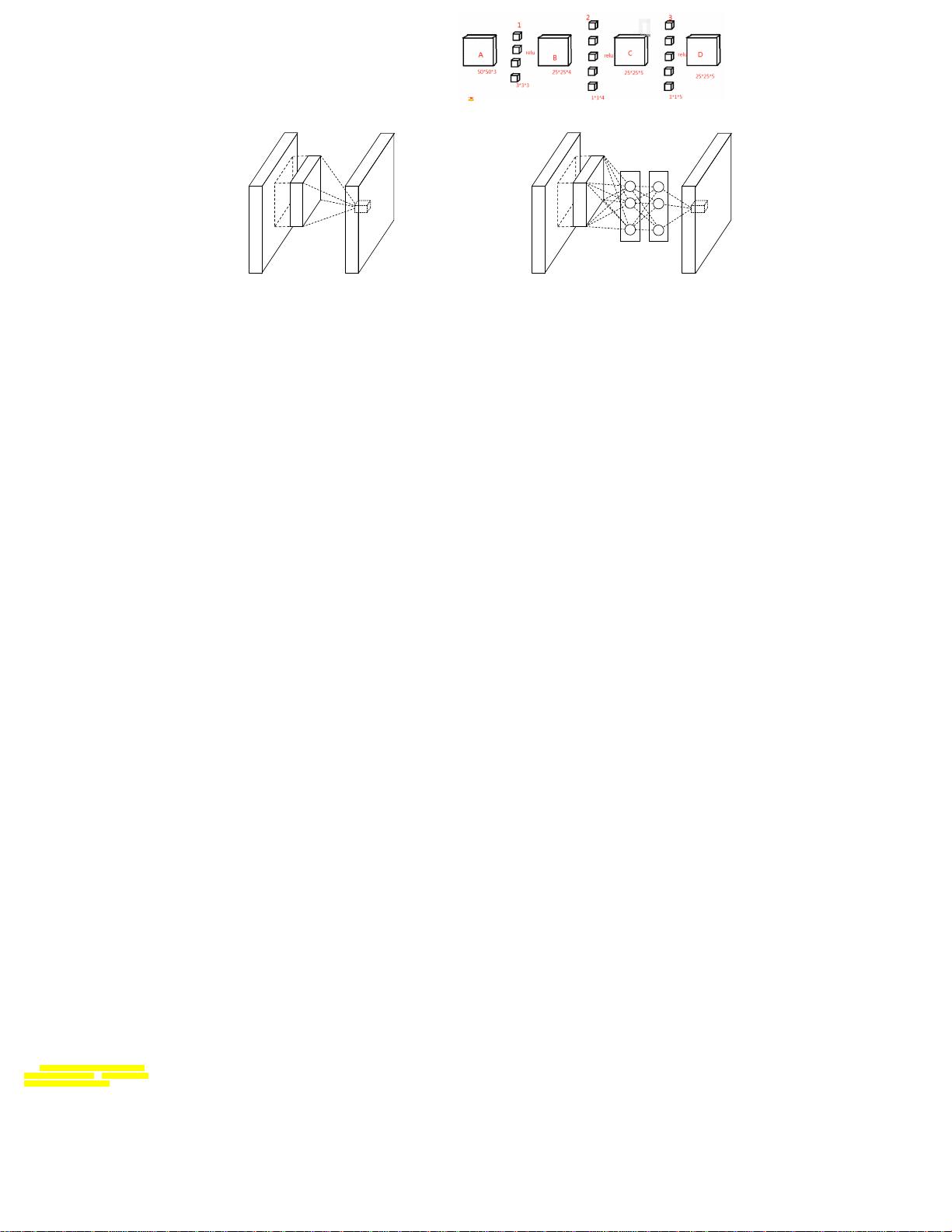
The resulting structure which we call an mlpconv layer is compared with CNN in Figure 1. Both the
linear convolutional layer and the mlpconv layer map the local receptive field to an output feature
vector. The mlpconv maps the input local patch to the output feature vector with a multilayer percep-
tron (MLP) consisting of multiple fully connected layers with nonlinear activation functions. The
MLP is shared among all local receptive fields. The feature maps are obtained by sliding the MLP
1
以前的深度学习结构,往往是CNN+POOLing+FC之类的组合,接一个分类器。
-->这样在CNN与FC进行结合的过程中,则把两部分过程独立来开
POOLing负责将维度,CNN负责提取特征,FC负责特征分类
由于卷积网络参数较少,因此深度卷积网络的参数其实大部分集中在了全连接层,那么这
个时候,到底是卷积层对结果贡献大还是全连接层贡献大?
---->本文提出的模型尝试赋予卷积层更强大的表征能力,同时去掉了全连接层,使用平均
池化层来代替全连接层进行分类,这样做的好处就是一方面减少了参数,另一方面避免了
由全连接层导致的过拟合的问题,因为池化层本身就充当了避免过拟合的功能,从而也就
不需要采用dropout了。 (池化是抽象“大而化之”,有防止过拟合作用)
卷积层是一个线性层(激活函数的目的就使数据非线性),如果遇到特征是高度非线性的
,那么此线性卷积就不足以表达了,传统的做法是通过多个特征图来增强卷积层的表达能
力,但是这样做又会对下一个卷积层造成较大的压力,因为下一层要考虑如何组合这些特
征图得到更高级的特征抽象。
我们提出了一种新的深度网络结构,叫做“Network in
Network(NIN)”来增强模型对感受野(receptive field)
局部区域(local patches) 的辨别力。传统的卷积层使用线
性滤波器,然后使用非线性激活函数来扫描输入。而我们使
用更复杂的结构建立了一个micro神经网络来在感受野之中
对数据进行抽象。我们使用多层感知机MLP来实现这个微型
神经网络,MLP是一种很好的函数近似器。我们通过在输入
上以与CNN近似的方式,使用微型神经网络进行滑窗,得到
特征图,然后特征图输出到下一层。深层的NIN网络可以靠
堆叠小网络实现。通过微型神经网络增强了局部模型,我们
可以在分类层,对特征图使用全局平均池化(global
average pooling),与传统的FC层相比,它更易于解释且
不易过拟合。我们使用NIN在CIFAR-
10和CIFAR-100上得到当今最好水平,在SVHM和MINST得到了
较好的表现。
CNN包括一系列卷积层和池化层,卷积层将
卷积核与卷积核的感受野范围内的输入做
内积,然后接一个非线性激活函数,输出
结果叫做特征图。
CNN中的卷积核对于它包含的data来说是一
种广义线性模型(Generalized linear
model,GLM),我们认为GLM的抽象等级比
较低。所谓抽象,我们的意思是该特征对于
相同概念的变体是不变的。使用一个更有力
的非线性函数近似器替换GLM可以提升模型
的抽象能力。当要学习的潜在concepts是线
性可分得时候,GLM可以取得很好的抽象效
果,也就是说,不同的概念可以由GLM定义
的平面分开。因此,传统的CNN简单的就假
设这些潜在概念是线性可分得。然而,实际
情况下,同种概念的数据也可能以一种非线
性流形存在,因此可以表示这些概念的
representations通常都是输入的高度非线
性函数。在NIN中,我们使用一个“micro
network”替代GLM,这个微小网络是一个普
通的非线性函数近似器(approximator)。
我们选择MLP作为微小网络的实例,它是一
个通用函数逼近器和也是一个可通过反向传
播训练的神经网络。
作者将一般的CNN网络的卷积操作改成了多层感知机,这
个多层感知机在二维输入上进行滑动计算出输出,整个网
络由很多个这样的层堆叠而成,这就是NIN的结构。
为什么要进行这样的改进呢?
--->作者提出,卷积操作其实可以看做一个广义线性模型
(GLM),因为其在进行特征提取的时候只有线性操作。
不是有激活函数吗?
--->激活函数只能说是为了分割不同卷积层防止其能合在一
起,并不能算是卷积提取特征里的非线性。
经过conv后wx,出来了一堆线性特征,然后加relu把特征再
非线性化
既然一般的卷积只是个线性模型,那它提取特征的能力就受
限了。
如果把这个特征提取的过程理解成在输入空间里进行分割,
举个例子就是,比如卷积的感受野是个3*3的区域,那么输入
空间就是9*9的,卷积提取特征会对这个9*9空间进行分割,
这一部分输出1,那一部分输出2,这个分割超平面就只能是
线性的,表达能力就受到限制。
例如在一个用于识别汽车图片的网络模型中
--->靠前的卷积层会被用于提取一些粗糙的原始的特征 (如:
线段、棱角等)
--->靠后的卷积层则会以前面的为基础提取到更为高级一些
的特征(如:轮胎、车门等)。
在每个阶段里所形的这些原始特征都被称之为“latent
concept”。作者认为,传统的GLM在进行每一阶段的特征提
取中,根本不足以区分这些特征元素
---例如某个卷积层可能提取得到了很多“轮胎”这一类的
sameconcept,但是GLM区分不了这些非线性的特征 (到底是
哪一类汽车的轮胎)。
--->原来的conv提取的是,浅层就是一堆线段、棱角、颜色
特征(不知道是谁的线段,谁的棱角,谁的颜色)
深层提取的是车轮、车门、车窗等特征(不知道是谁的车门,
谁的车窗、谁的车轮)--->这些只能靠下一层再划分
下一层再有好多个卷积核
这个负责车门这一堆,那个负责车窗这一堆,另外一个负责
车轮那一堆
车门这一堆再分是那种车的车门,车窗这一对再分是哪种车
窗的,车轮这一对再
Network In Network
我们当然希望提取的更抽象,也就是知道
浅层:这一堆线段里(这一个线段是哪一个车的哪一个部位的),这一堆棱角里(这一个棱角是哪一个车的哪一个部位的),这一堆颜色(这一个颜色是哪一个车的哪一个部位的)
深层:这一堆车门(这一个车门是哪一种车的),这一堆车窗(这一个车窗是哪种车的),这一堆车轮(这一个车轮是哪种车的)
浅层:这一堆是线段,那一堆是棱角、另一堆是颜色(线性划分)
深层:这一堆是车门,那一堆是车窗、另一堆是车轮(线性划分)
棱角
线段
颜色
车门 车窗
车轮
然后全连接层把这些车轮,车窗,车门
(等等我们无法理解的特征)共1000个,然后
输出10个种类汽车--->根据权重检测出结果
小汽车的车轮
小汽车的车窗
小汽车的车门
大巴车的车轮
大巴车的车窗
大巴车的车门
把原来conv弄的更抽象,
由原来抽象出来的车门,车窗,车轮
抽象成 谁的车门,谁的车窗,谁的车轮
都是车窗
都属于大巴车
经典-->没有办法
线性区分了,因
为抽象出来特征
包含的信息太多
了。
我们称之为mlpconv层的结果结构在图1中与
CNN进行了比较。线性卷积层和mlpconv层都
将局部接收场映射到输出特征向量。
mlpconv 层将局部块( input local patch
)的输入通过一个由全连接层和非线性激活
函数组成的多层感知器(MLP)映射到了输出
的特征向量。 MLP在所有局部感受野中共享
。特征图通过用像CNN一样的方式在输入上滑
动MLP得到,NIN的总体结构是一系列mplconv
层的堆叠。 它被称为“网络中的网络”
(NIN),因为我们有微型网络(MLP),它在
mlpconv层中构成整个深层网络的组成部分。
以分类概念(categorical concepts)为例,模型抽象能力高时,某分类下的目标即使具
有多种多样的表现形式,也被被检测出其所属分类。假设潜在概念(latent concepts)
的样本线性可分,即,同一concept的所有变体均居于某个分离面的同一侧(比如SVM),
此时线性模型可以达到很好的抽象程度。
传统的CNN就默认了这个假设——认为隐含概念(latent concept)是线性可分的,虽然
卷积层后面接了一个激活函数,但是其抽象能力不足。然而,同一概念的数据通常是非线
性流形的,流形可以简单想成是很多曲面片的叠加,比如一个圆,一个球面等,捕捉这些
概念的表达通常都是输入的高维非线性函数。在NIN中,GLM用“微型网络(micro
network)”结构替代,该结构是一个非线性函数逼近器。
NIN网络用微型网络mlpconv层代替了传统的卷积层;用GAP代替了传统CNN
不用Fc层,用全局平均池化层
(把整张feature map 变成1个数)
最后要检测n种物体,最后一层就出n个feature map 然后出n个数 也就能检测n种物体)
-->没有参数,可以避免过拟合 它对空间信息进行了求和,因而对输入的空间变换更具有稳定性
因为全连接参数很多,容易过拟合,所以一般和dropout一起用
强化特征映射和类别之间的一致性
用NIN模块替换传统Conv+Pool结构
(NIN使用1*1卷积融合多通道)
-->提升CNN的非线性表达能力 (提出了抽象能力更强的Mlpconv层)
强化特征映射和类别之间的一致性
模型中末尾的全连接层