

分享一个Python爬虫入门实例(有源码,学习使用)
一、爬虫基础知识
Python爬虫是一种使用Python编程语言实现的自动化获取网页数据的技术。它广泛应用于数据采集、
数据分析、网络监测等领域。以下是对Python爬虫的详细介绍:
1. 架构和组成:
下载器:负责根据指定的URL下载网页内容,常用的库有Requests和urllib。
解析器:用于解析下载的网页内容,提取所需的数据。BeautifulSoup和lxml是常用的解析库。
存储器:将提取的数据存储到本地或数据库中,以便于后续处理和分析。
2. 优势:
易于学习和使用:Python语言简洁易懂,入门门槛低,适合初学者。
强大的库支持:拥有丰富的第三方库,如Requests、BeautifulSoup和Scrapy,大大提高了开发效
率。
跨平台性:Python是跨平台的,可以在多种操作系统上运行。
社区活跃:Python有着庞大的开发者社区,遇到问题时可以快速找到解决方案。
3. 应用场景:
数据挖掘:从网站抓取大量数据进行市场分析、用户行为研究等。
监控竞品:定期检查竞争对手的网站变化,如价格变动、新产品发布等。
内容聚合:自动收集来自不同来源的内容,整合后提供给用户。
自动化测试:模拟用户操作,进行网站的自动化测试。
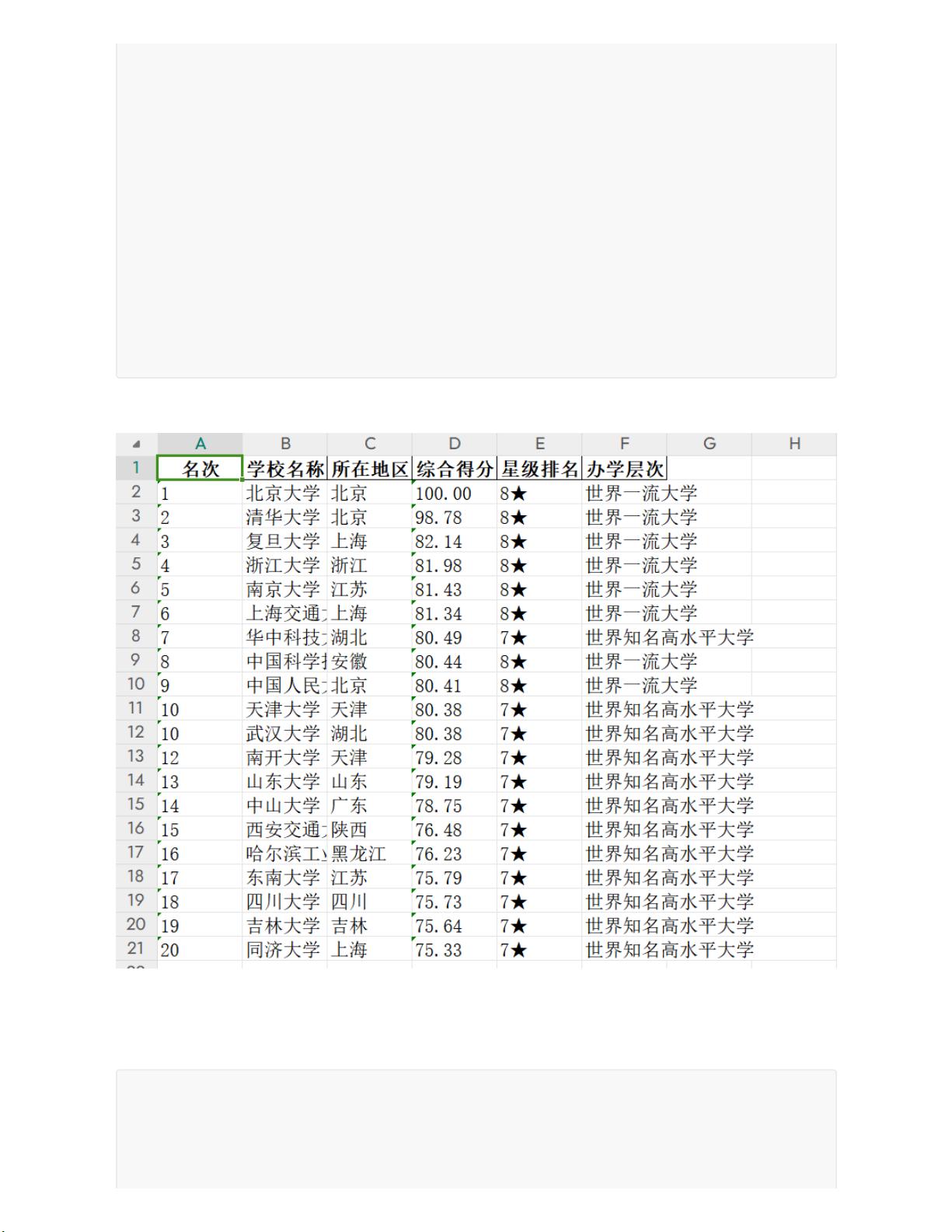
二、案例:爬取大学排名数据
代码实现:
import requests
from bs4 import BeautifulSoup
import pandas as pd
ulist = []
# 爬取的网站的URL
url = "http://www.gaosan.com/gaokao/241219.html"
response = requests.get(url)
# 编码格式
response.encoding = 'utf-8'
# 编译数据
soup = BeautifulSoup(response.text, 'html.parser')
# 将数据存入定义好的ulist
for tr in soup.find('tbody').children:
tds = tr('td')
剩余7页未读,继续阅读
资源评论


衍生星球
- 粉丝: 2326
- 资源: 6









最新资源
- 菊花枝条裁断机sw18可编辑全套技术资料100%好用.zip
- 基于java的会员管理系统+jsp源码(java毕业设计完整源码+LW).zip
- 基于ssm的少儿编程网上报名系统源码(java毕业设计完整源码+LW).zip
- 基于ssm的毕业生就业信息统计系统源码(java毕业设计完整源码+LW).zip
- 基于ssm的新能源汽车在线租赁管理系统源码(java毕业设计完整源码+LW).zip
- 精密裁断机(sw18可编辑+cad)全套技术资料100%好用.zip
- 基于ssm的线上旅行信息管理系统ssm源码(java毕业设计完整源码+LW).zip
- 胶条切断机(sw18可编辑+工程图)全套技术资料100%好用.zip
- 基于ssm的医院住院管理系统源码(java毕业设计完整源码+LW).zip
- 卡簧安装器sw18可编辑全套技术资料100%好用.zip
- 基于ssm的小型企业办公自动化系统的设计和开发源码(java毕业设计完整源码+LW).zip
- .net(c#)开发的windows 服务,实现不同MySQL数据库的数据同步功能,例子简单,有具体的操作说明,可供参考
- 基于ssm的健身房管理系统的设计与实现源码(java毕业设计完整源码+LW).zip
- 使用Python为图像中的不同区域添加颜色
- 卡片分拣机sw18可编辑全套技术资料100%好用.zip
- 基于ssm的网上花店设计源码(java毕业设计完整源码+LW).zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


