

2023/6/28 17:12
Pix2Seq:谷歌大脑提出 CV 任务统一接口!
https://mp.weixin.qq.com/s/F4xkRINbT40ua0UuulMjDw
1/8
Pix2Seq:谷歌大脑提出 CV 任务统一接口!
文 | 青豆
最近一个大趋势就是将各类任务统一在一个大一统框架下。大规模预训练语言模型已成功打通各类
文本任务,使得不同的NLP任务上,都可以用这种统一的sequence生成框架作为基础模型,只需
要通过prompt的方式,指导模型生成目标结果。
这种大一统的sequence生成框架在NLP任务成功的关键是任务描述和任务输出都可以序列化成text
tokens。
但CV任务输入输出都更加多样,那不是得为不同的任务定制不同的模型和损失函数?这也是CV任
务大一统框架的瓶颈。
以自然语言为输出的任务,比如image captioning、visual question answering这类任务,天然
可 以 转 化 为 生 成 text token sequence 。 但 模 型 的 输 出 形 式 还 存 在 很 多 其 他 的 形 式 , 例 如
bounding box、dense masks等。
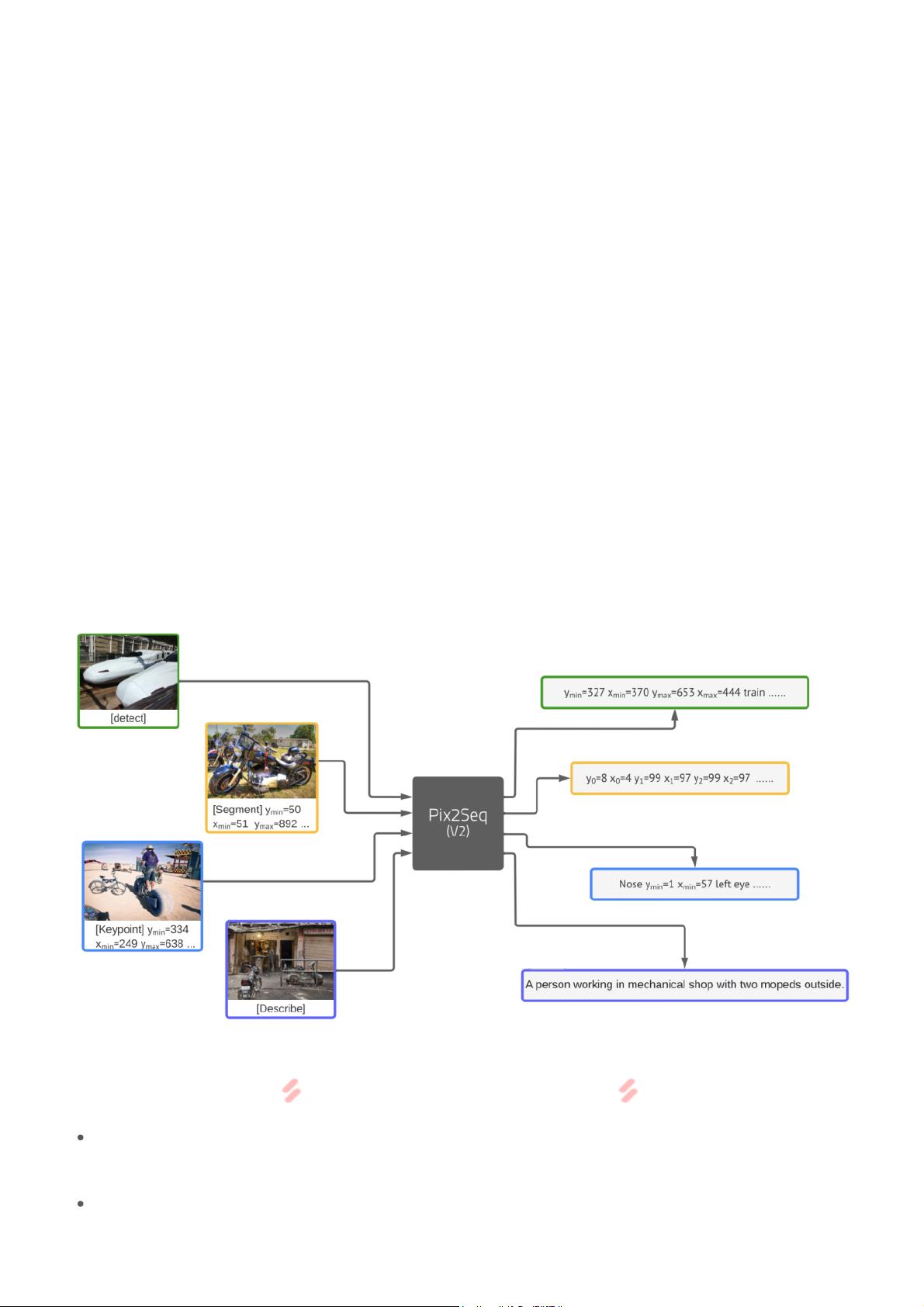
Pix2Seq在这样的动机下诞生了:既然输出形式不同是难点,能否将各类输出形式都统一成token
sequence?
去年Google Brain提出的Pix2Seq就以目标检测作为出发点,建立Pixel-to-Sequence的映射,探
索了这种可能性(戳《图灵奖大佬+谷歌团队,为通用人工智能背书!CV 任务也能用 LM 建
模!》)。
青豆 2022-07-20 12:05 发表于北京
原创
夕小瑶科技说
剩余7页未读,继续阅读
资源评论


普通网友
- 粉丝: 1277
- 资源: 5623









最新资源
- matlab平台的的语音滤波设计.zip
- matlab平台的汉字语音识别.zip
- matlab平台的汉字识别.zip
- matlab平台的的运动行为检测.zip
- matlab平台的火焰识别系统设计.zip
- matlab平台的基于DWT+SVD结合傅里叶变换的数字图像水印水印系统.zip
- matlab平台的火焰烟雾检测.zip
- matlab平台的教室人数统计.zip
- matlab平台的交通道路标识识别.zip
- matlab平台的家居防火识别系统.zip
- matlab平台的考勤系统设计.zip
- matlab平台的口罩检测.zip
- matlab平台的金属表面缺陷分析.zip
- matlab平台的口罩识别设计.zip
- matlab平台的口罩识别.zip
- matlab平台的口罩识别检测.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


