搜索中的Query理解及应用.pdf
版权申诉
123 浏览量
2023-08-12
12:59:53
上传
评论
收藏 2.4MB PDF 举报


搜索中的 Query 理解及应⽤
5⽉18⽇⼣⼩瑶的卖萌屋
⼀只⼩狐狸带你解锁炼丹术&NLP秘籍
⽂章作者:Joelchen 腾讯 研究员
编辑整理:Hoh
内容来源:腾讯技术⼯程出品
链接:https://zhuanlan.zhihu.com/p/112719984
前⾔
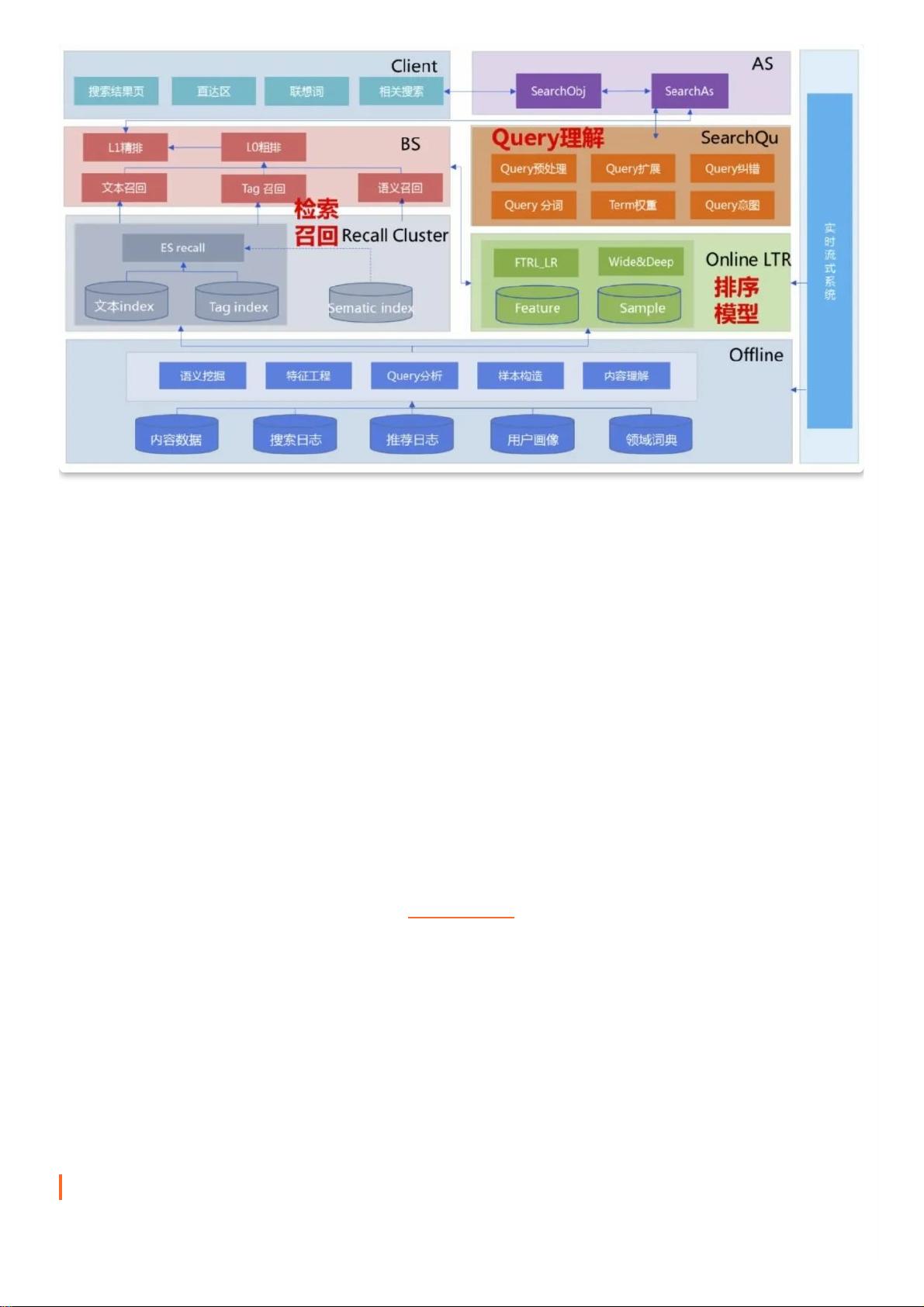
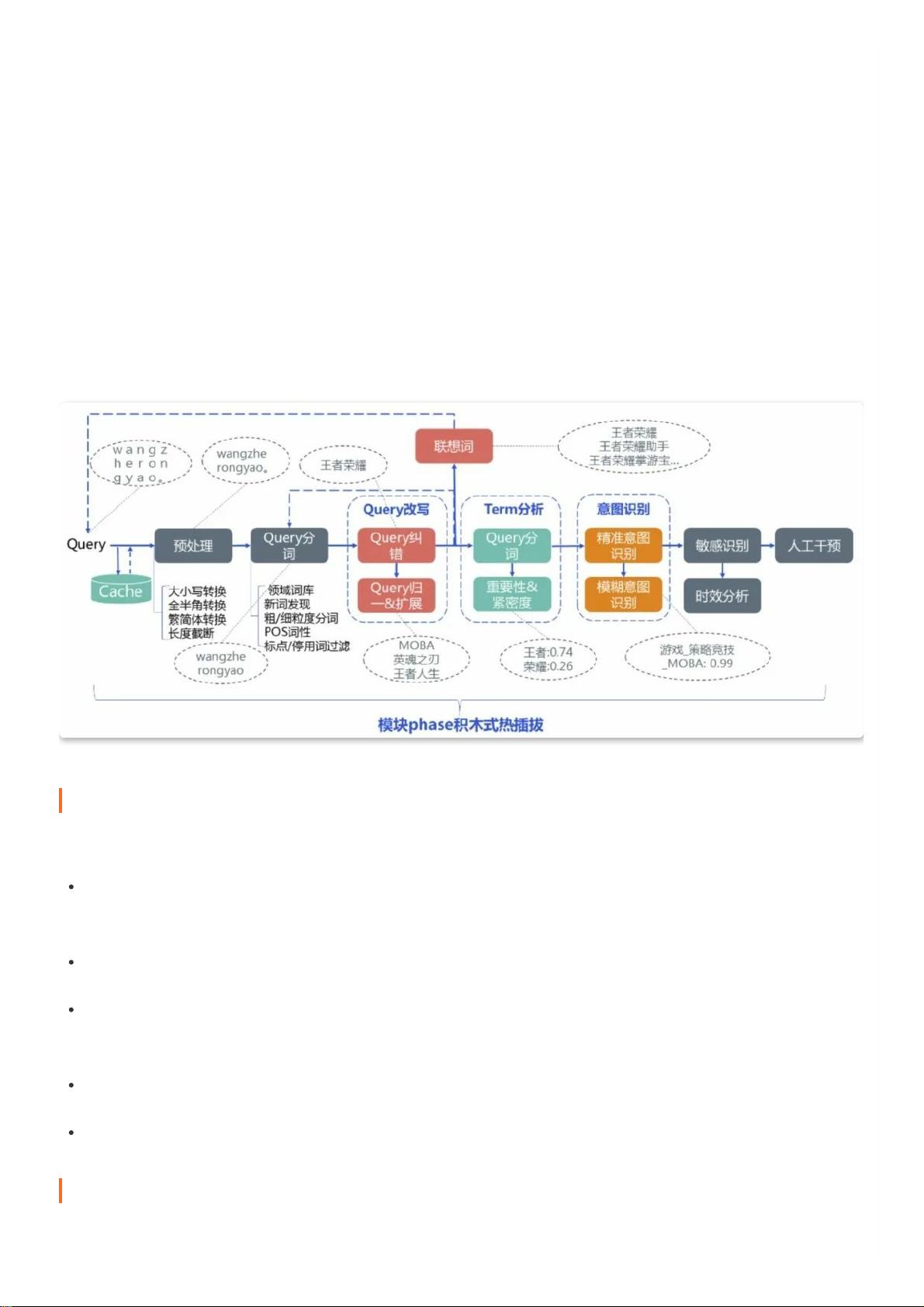
Query 理解 ( QU,Query Understanding ),简单来说就是从词法、句法、语义三个层⾯对 query 进⾏结构化解析。这⾥ query 从⼴
义上来说涉及的任务⽐较多,最常⻅的就是我们在搜索系统中输⼊的查询词,也可以是 FAQ 问答或阅读理解中的问句,⼜或者可以
是⼈机对话中⽤⼾的聊天输⼊。本⽂主要介绍在搜索中的 query 理解,会相对系统性地介绍 query 理解中各个重要模块以及它们之
间如何 work 起来共同为搜索召回及排序模块服务,同时简单总结个⼈⽬前了解到业界在各个模块中的⼀些实现⽅法。
相关概念
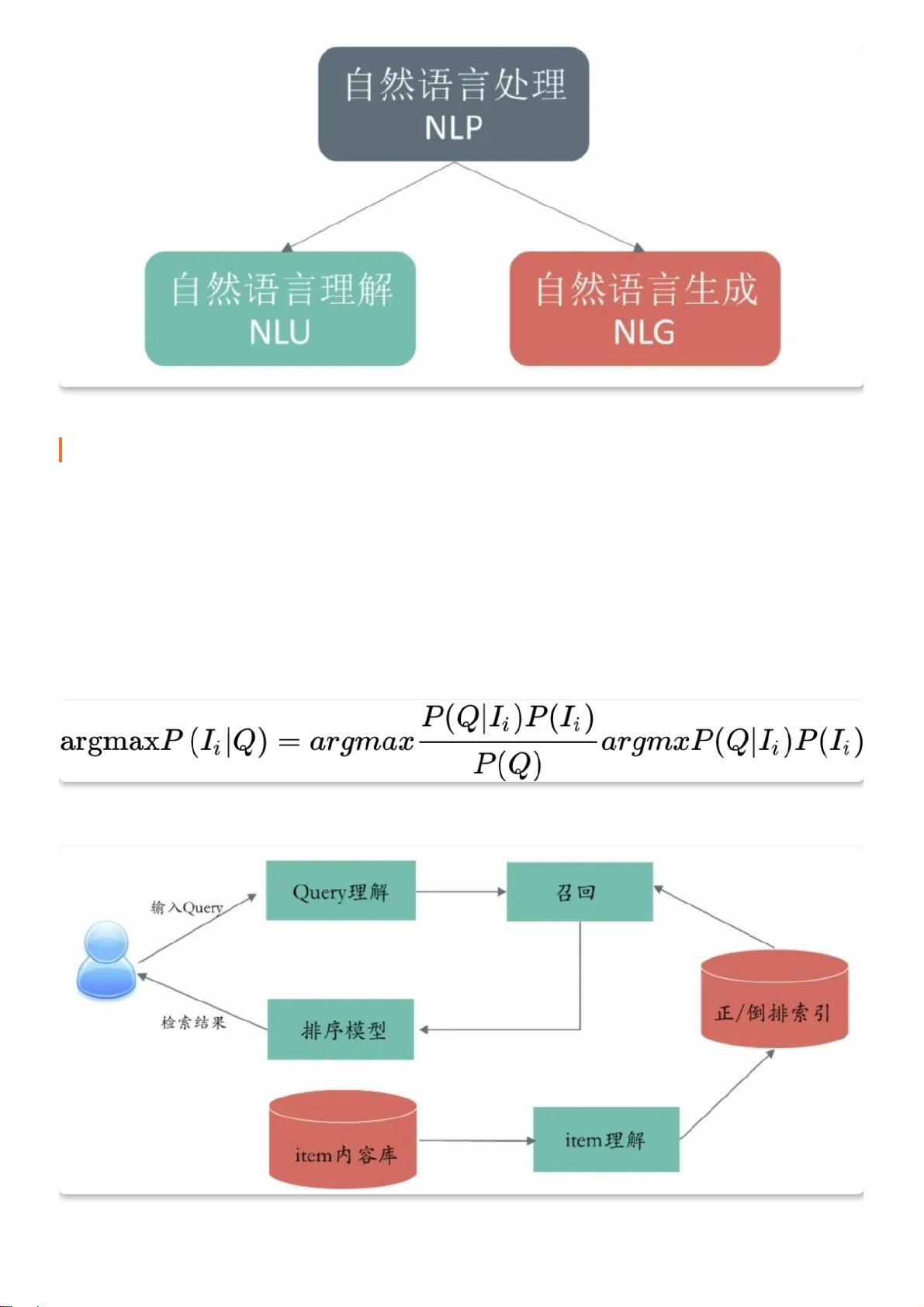
1. NLP
⾃然语⾔处理 ( NLP,Natural Language Processing ) 是集语⾔学、统计学、计算机科学,⼈⼯智能等学科于⼀体的交叉领域,⽬
标是让计算机能在处理理解⼈类⾃然语⾔的基础上进⼀步执⾏结构化输出或语⾔⽣成等其他任务,其涉及的基础技术主要有:词法
分析、句法分析、语义分析、语⽤分析、⽣成模型等。诸如语⾳识别、机器翻译、QA 问答、对话机器⼈、阅读理解、⽂本分类聚
类等任务都属于 NLP 的范畴。
这些任务从变换⽅向上来看,主要可以分为⾃然语⾔理解 ( NLU,Natural Language Understanding ) 和⾃然语⾔⽣成 (
NLG,Natural Language Generation ) 两个⽅⾯,其中 NLU 是指对⾃然语⾔进⾏理解并输出结构化语义信息,⽽ NLG 则是多模态
内容 ( 图像、语⾳、视频、结构/半结构/⾮结构化⽂本 ) 之间的相互⽣成转换。
⼀些任务同时涵盖 NLU 和 NLG,⽐如对话机器⼈任务需要在理解⽤⼾的对话内容 ( NLU 范畴 ) 基础上进⾏对话内容⽣成 ( NLG 范
畴 ),同时为进⾏多轮对话理解及与⽤⼾交互提⽰这些还需要有对话管理模块 ( DM,Dialogue Management ) 等进⾏协调作出对话
控制。本⽂要介绍的搜索 query 理解⼤部分模块属于 NLU 范畴,⽽像 query 改写模块等也会涉及到⼀些 NLG ⽅法。

剩余24页未读,继续阅读
资源评论


地理探险家
- 粉丝: 1046
- 资源: 5416









最新资源
- Android面试题.txt
- chujuyingshi1129802.apk
- 865804808983585自动化办公必备numpy、pandas数据处理课件.zip
- Fences 5是一款桌面整理软件,主要用于Windows操作系统,能够帮助用户更有效地管理和组织桌面上的图标和文件
- Appium入门 appium-desktop安装包,下载即可安装使用
- 初步图优化之后的fb bev 结构图
- 爬取cnnvd网站代码最新的 2024年
- 资源专区-毕业设计-数据分析-CRM客户关系管理系统
- 毕业设计-使用Matlab基于遗传算法+非线性规划实现的函数寻优算法-附项目源码.zip
- api接口python.rar
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


