chatGPT基础科普
171 浏览量
2023-04-20
13:12:59
上传
评论
收藏 2.66MB PDF 举报


Yam
Feeling, Coding, Thinking
ChatGPT 基础科普:知其一点所以然
2022年底,ChatGPT突然间在AI圈开始流行,准确来说是搞自然语言处理(Natural Language Processing,
NLP)圈子里先火起来了。遥想当时,本以为就会在圈内火一阵,结果现在……没想到居然成了AI的救命稻草,当
然对AI工程师尤其是NLP工程师是什么就不好说了。海内外沸腾之后就是第一时间的跟进,结果自然是努力对齐而
无功,连牛逼的Google和FaceBook都翻车了。不过总归是折腾出来一些东西,大伙儿也都有了目标,圈子又有了
新活力。希望OpenAI继续发力,我等再多苟些日子。
无论是ChatGPT还是后来的模仿者,它们其实都是语言模型,准确来说——大语言模型。使用时,无论是调用API
还是开源项目,总有一些参数可能需要调整。对大部分内行人士来说应该都不成问题,但对外行就有点玄乎了。基
于此,本文将简要介绍ChatGPT相关技术基本原理,行文将站在外行人角度,尝试将内容尽量平民化。虽然不能深
入细节,但知晓原理足以很好使用了。
本文共分为四个部分:
LM:这是ChatGPT的基石的基石,是一个最基本的概念,绕不开,逃不过,没办法。
Transformer:这是ChatGPT的基石,准确来说它的一部分是基石。
GPT:本体,从GPT-1,一直到现在的GPT-4,按openai自己的说法,那模型都是那个模型,只是它长大
了,变胖了,不过更好看了。关于这点,大家基本都没想到。现在好了,攀不上了。
RLHF:ChatGPT神兵利器,有此利刃,ChatGPT才是那个ChatGPT,不然就只能是GPT-3。
LM
LM,Language Model,语言模型,简单来说就是利用自然语言构建的模型。这个自然语言就是人常说的话,或
者记录的文字等等,只要是人生产出来的文字,都可以看做语言。你现在看到的文字也是。模型就是根据特定输
入,通过一定计算输出相应结果的一个东西,可以把它当做人的大脑,输入就是你的耳、眼听或看到的文字,输出
就是嘴巴说出来或手写出来的文字。总结一下,语言模型就是利用自然语言文本构建的,根据输入的文字,输出相
应文字的模型。
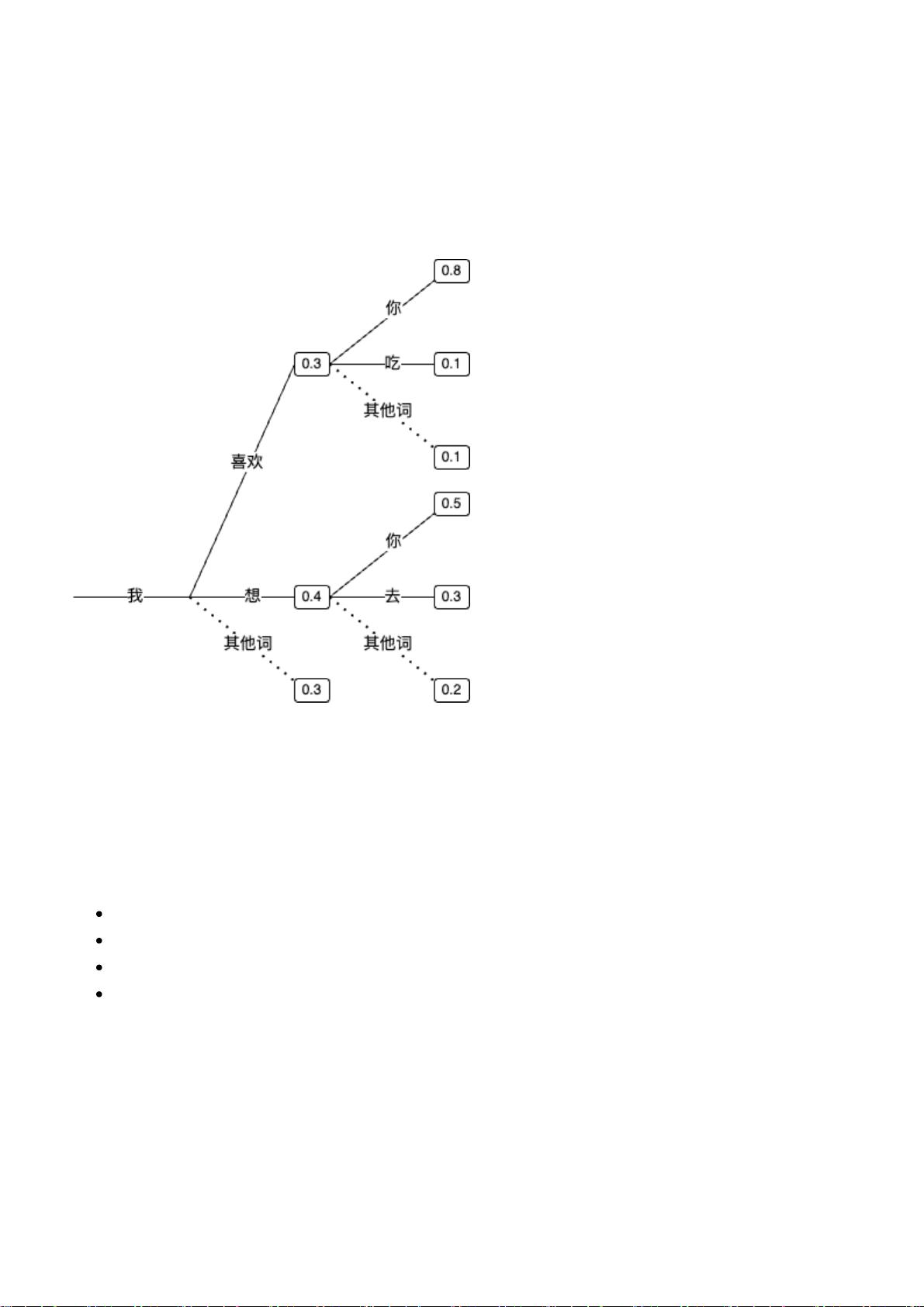
具体是怎么做的呢,方法有很多种,比如我写好一个模板:「XX喜欢YY」,如果XX=我,YY=你,那就是我喜欢
你,反过来就是你喜欢我。我们这里重点要说的是概率语言模型,它的核心是概率,准确来说是下一个词的概率。
这种语言模型在通过已经有的词预测接下来的词。我们举个简单的例子,比如你只告诉模型:「我喜欢你」这句
话,当你输入「我」的时候,它就知道你接下来要说「喜欢」了。为什么?因为它脑子里就只有这四个字,你没告
诉它其他的呀。

剩余17页未读,继续阅读
资源评论













