MAE-Masked Autoencoders Are Scalable Vision Learners

需积分: 0 11 浏览量
更新于2024-11-24
收藏 1.52MB PDF 举报
MAE-Masked Autoencoders Are Scalable Vision Learners
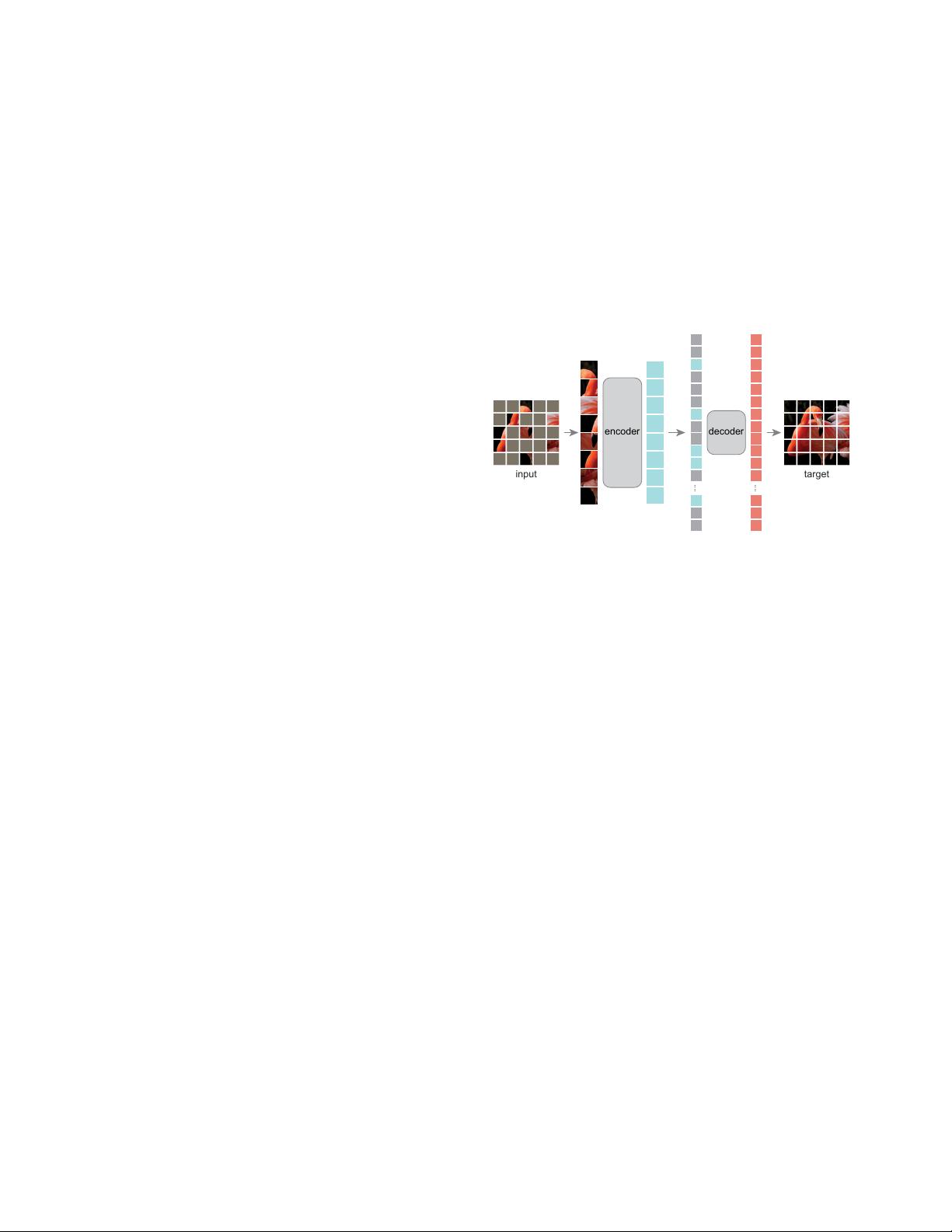
Masked Autoencoders Are Scalable Vision Learners
Kaiming He
∗,†
Xinlei Chen
∗
Saining Xie Yanghao Li Piotr Doll
´
ar Ross Girshick
∗
equal technical contribution
†
project lead
Facebook AI Research (FAIR)
Abstract
This paper shows that masked autoencoders (MAE) are
scalable self-supervised learners for computer vision. Our
MAE approach is simple: we mask random patches of the
input image and reconstruct the missing pixels. It is based
on two core designs. First, we develop an asymmetric
encoder-decoder architecture, with an encoder that oper-
ates only on the visible subset of patches (without mask to-
kens), along with a lightweight decoder that reconstructs
the original image from the latent representation and mask
tokens. Second, we find that masking a high proportion
of the input image, e.g., 75%, yields a nontrivial and
meaningful self-supervisory task. Coupling these two de-
signs enables us to train large models efficiently and ef-
fectively: we accelerate training (by 3× or more) and im-
prove accuracy. Our scalable approach allows for learning
high-capacity models that generalize well: e.g., a vanilla
ViT-Huge model achieves the best accuracy (87.8%) among
methods that use only ImageNet-1K data. Transfer per-
formance in downstream tasks outperforms supervised pre-
training and shows promising scaling behavior.
1. Introduction
Deep learning has witnessed an explosion of archi-
tectures of continuously growing capability and capacity
[33, 25, 57]. Aided by the rapid gains in hardware, mod-
els today can easily overfit one million images [13] and
begin to demand hundreds of millions of—often publicly
inaccessible—labeled images [16].
This appetite for data has been successfully addressed in
natural language processing (NLP) by self-supervised pre-
training. The solutions, based on autoregressive language
modeling in GPT [47, 48, 4] and masked autoencoding in
BERT [14], are conceptually simple: they remove a portion
of the data and learn to predict the removed content. These
methods now enable training of generalizable NLP models
containing over one hundred billion parameters [4].
The idea of masked autoencoders, a form of more gen-
eral denoising autoencoders [58], is natural and applicable
in computer vision as well. Indeed, closely related research
encoder
....
....
decoder
input target
Figure 1. Our MAE architecture. During pre-training, a large
random subset of image patches (e.g., 75%) is masked out. The
encoder is applied to the small subset of visible patches. Mask
tokens are introduced after the encoder, and the full set of en-
coded patches and mask tokens is processed by a small decoder
that reconstructs the original image in pixels. After pre-training,
the decoder is discarded and the encoder is applied to uncorrupted
images (full sets of patches) for recognition tasks.
in vision [59, 46] preceded BERT. However, despite signif-
icant interest in this idea following the success of BERT,
progress of autoencoding methods in vision lags behind
NLP. We ask: what makes masked autoencoding different
between vision and language? We attempt to answer this
question from the following perspectives:
(i) Until recently, architectures were different. In vision,
convolutional networks [34] were dominant over the last
decade [33]. Convolutions typically operate on regular grids
and it is not straightforward to integrate ‘indicators’ such as
mask tokens [14] or positional embeddings [57] into con-
volutional networks. This architectural gap, however, has
been addressed with the introduction of Vision Transform-
ers (ViT) [16] and should no longer present an obstacle.
(ii) Information density is different between language
and vision. Languages are human-generated signals that
are highly semantic and information-dense. When training
a model to predict only a few missing words per sentence,
this task appears to induce sophisticated language under-
standing. Images, on the contrary, are natural signals with
heavy spatial redundancy—e.g., a missing patch can be re-
covered from neighboring patches with little high-level un-
15979
2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
978-1-6654-6946-3/22/$31.00 ©2022 IEEE
DOI 10.1109/CVPR52688.2022.01553
2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) | 978-1-6654-6946-3/22/$31.00 ©2022 IEEE | DOI: 10.1109/CVPR52688.2022.01553
Authorized licensed use limited to: Shandong Normal University. Downloaded on April 15,2023 at 07:13:39 UTC from IEEE Xplore. Restrictions apply.
下载后可阅读完整内容,剩余9页未读,立即下载
171 浏览量
2023-04-18 上传
163 浏览量
106 浏览量
2021-12-06 上传
190 浏览量
152 浏览量
190 浏览量
2021-05-18 上传
139 浏览量
2021-03-22 上传
2021-06-20 上传
195 浏览量
194 浏览量
176 浏览量
107 浏览量
116 浏览量
189 浏览量
2021-02-10 上传
2022-10-18 上传
2021-04-05 上传
144 浏览量
162 浏览量
185 浏览量
资源评论


薛定谔的猫ovo
- 粉丝: 5w+
- 资源: 5









最新资源
- 微电网模型Matlab Simulink,风光储微电网,永磁风机并网仿真,光伏并网仿真,蓄电池仿真,柴油发电机,光储微电网 风储微电网 Matlab仿真平台搭建的风光储微电网模型,风光柴储微电网,pw
- 程序员简历模板-单页单色59.docx
- 程序员简历模板-单页单色54.docx
- 程序员简历模板-单页单色39.docx
- comsol激光打孔模型,采用水平集两相流,涉及传热,熔化,表面张力,高斯热源
- 程序员简历模板-单页单色41.docx
- 程序员简历模板-单页单色60.docx
- 电机故障数据集.rar
- 51单片机温室大棚温湿度光照控制系统资料包括原理图,PCB文件,源程序,一些软件等,仿真文件 设计简介: (1)51单片机+DHT11温湿度传感器+GY-30光照传感器+1602液晶; (2)温度检
- 流浪动物救助平台 源码+数据库+论文(JAVA+SpringBoot+Vue.JS+MySQL).zip
- 微环谐振腔的光学频率梳matlab仿真 微腔光频梳仿真 包括求解LLE方程(Lugiato-Lefever equation)实现微环中的光频梳,同时考虑了色散,克尔非线性,外部泵浦等因素,具有可延展
- ZenIdentityServer4 客户凭证模式
- 流浪动物救助平台 JAVA毕业设计 源码+数据库+论文 Vue.js+SpringBoot+MySQL.zip
- 流浪动物救助网站 JAVA毕业设计 源码+数据库+论文 Vue.js+SpringBoot+MySQL.zip
- 风光储、风光储并网直流微电网simulink仿真模型 系统由光伏发电系统、风力发电系统、混合储能系统(可单独储能系统)、逆变器VSR?大电网构成 光伏系统采用扰动观察法实现mppt控
- 流浪猫狗救助救援网站 源码+数据库+论文(JAVA+SpringBoot+Vue.JS+MySQL).zip
