### Hadoop 3.3.6 最新安装教程知识点概览
#### 一、准备工作:用户与组配置
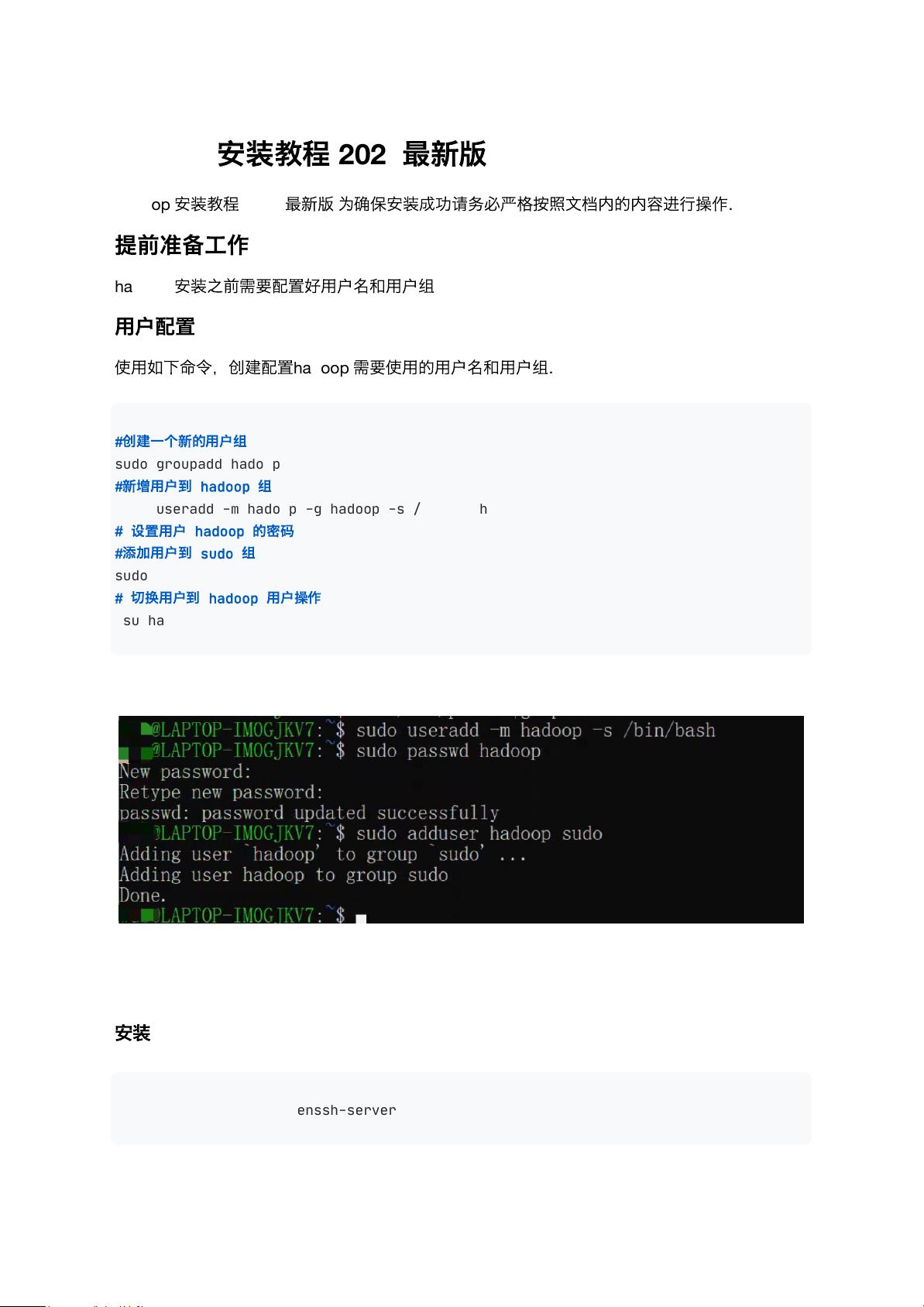
- **创建用户组**:通过 `sudo groupadd hadoop` 命令来创建一个新的用户组 `hadoop`。
- **创建用户**:利用 `sudo useradd -m hadoop -g hadoop -s /bin/bash` 命令创建一个名为 `hadoop` 的用户,并将其加入 `hadoop` 组中,同时指定 `/bin/bash` 作为该用户的默认 shell。
- **设置用户密码**:使用 `passwd hadoop` 命令来为 `hadoop` 用户设置密码。
- **将用户添加至 sudo 组**:通过 `sudo adduser hadoop sudo` 命令将 `hadoop` 用户添加到 `sudo` 组中,以便于后续的操作可以获取管理员权限。
- **切换用户**:使用 `su hadoop` 命令切换到 `hadoop` 用户。
#### 二、SSH 免密登录配置
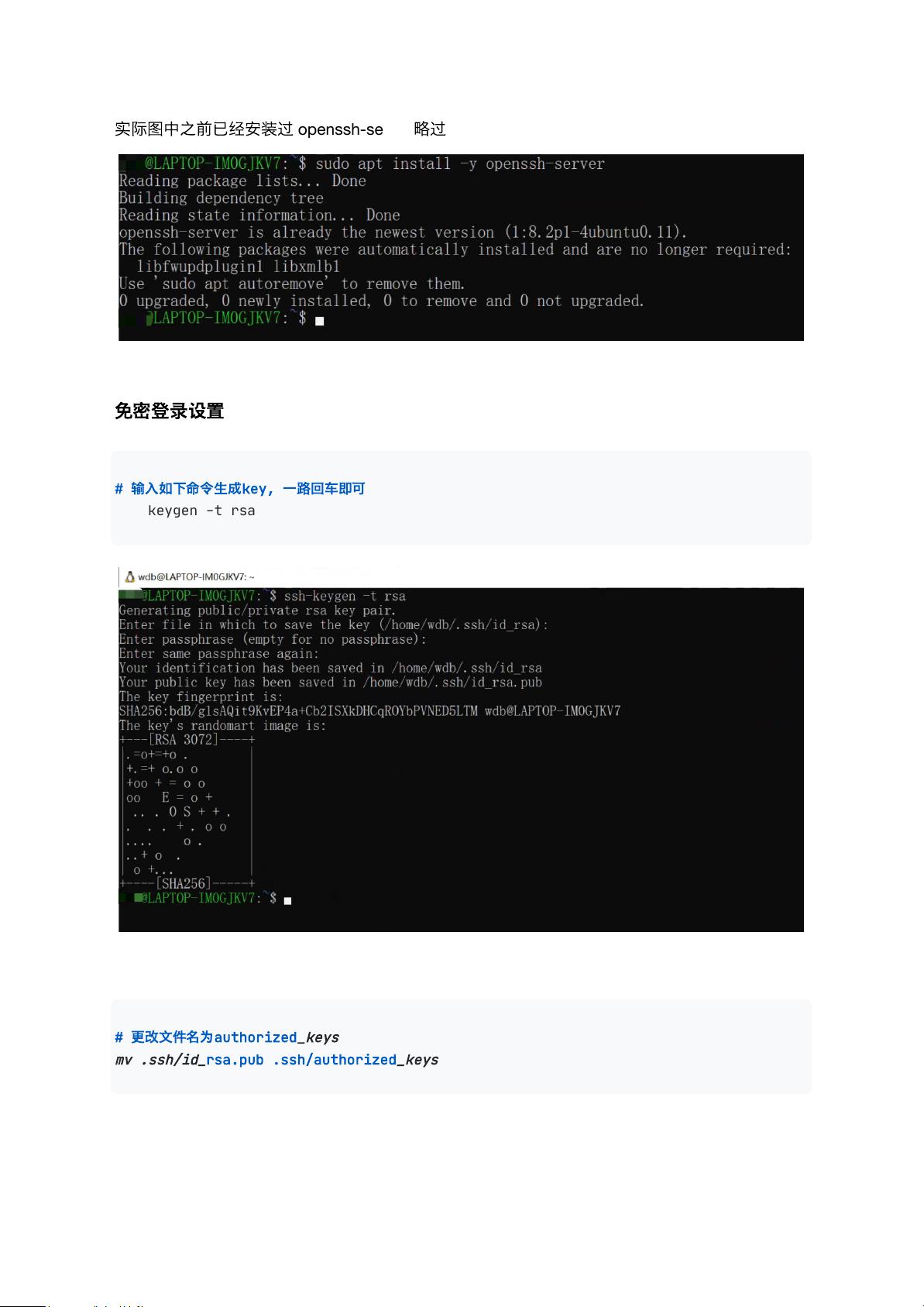
- **安装 SSH Server**:运行 `sudo apt install -y openssh-server` 命令安装 SSH 服务端。
- **生成 SSH 密钥**:执行 `ssh-keygen -t rsa` 命令来生成 SSH 密钥对,一路回车以接受默认设置。
- **修改密钥文件名**:通过 `mv .ssh/id_rsa.pub .ssh/authorized_keys` 命令来重命名公钥文件。
- **编辑 SSH 配置文件**:使用 `sudo vi /etc/ssh/sshd_config` 命令编辑 SSH 配置文件,并添加以下两行配置:
- `PubkeyAuthentication yes`
- `AuthorizedKeysFile .ssh/authorized_keys`
#### 三、Java 环境配置
- **安装 Java**:执行 `sudo apt-get install openjdk-8-jdk` 命令安装 OpenJDK 8。
- **查看 Java 版本**:运行 `java -version` 命令来确认 Java 版本已正确安装。
- **配置 Java 环境变量**:编辑 `~/.bashrc` 文件,在文件末尾添加以下内容并保存:
- `export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64`
- **验证 Java 环境变量设置**:通过 `echo $JAVA_HOME` 命令来验证环境变量是否设置成功。
#### 四、Hadoop 的安装与配置
- **下载 Hadoop**:使用 `wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.4.0/hadoop-3.4.0.tar.gz` 命令下载 Hadoop 的安装包。
- **解压缩 Hadoop**:通过 `sudo tar-zxvf ~/hadoop-3.4.0.tar.gz -C /usr/local/` 命令将 Hadoop 解压到 `/usr/local/` 目录下。
- **修改目录名称与权限**:执行以下命令:
- `sudo mv /usr/local/hadoop-3.4.0/ /usr/local/hadoop`
- `sudo chown -R hadoop:hadoop /usr/local/hadoop`
- **查看 Hadoop 版本**:使用 `usr/local/hadoop/bin/hadoop version` 命令查看 Hadoop 的版本信息。
- **配置 Hadoop**:编辑 Hadoop 的配置文件 `core-site.xml`:
- 设置 `<name>dfs.replication</name>` 的值为 `1`,表示每个文件的副本数量。
- 设置 `<name>dfs.namenode.name.dir</name>` 的值为 `file:/usr/local/hadoop/tmp/dfs/name`,用于定义 NameNode 的存储路径。
- 设置 `<name>dfs.datanode.data.dir</name>` 的值为 `file:/usr/local/hadoop/tmp/dfs/data`,用于定义 DataNode 的存储路径。
### 补充说明
- 在进行上述操作前,请确保您的系统已更新到最新状态,可以通过 `sudo apt update && sudo apt upgrade` 来完成系统更新。
- 在安装过程中,如果遇到任何问题,如权限错误或依赖缺失等,请及时查阅官方文档或社区支持文档。
- 对于 Hadoop 的安装,建议在虚拟机环境下进行操作,以避免对生产环境造成不必要的干扰。
- 完成 Hadoop 的安装后,还需要进一步配置 HDFS 和 YARN 等服务,以实现分布式计算的功能。
- 在使用 Hadoop 进行大数据处理时,还需要学习 MapReduce、Spark 等相关的框架和技术,以充分发挥 Hadoop 生态系统的强大功能。