distribute_crawler
==================
使用scrapy,redis, mongodb,graphite实现的一个分布式网络爬虫,底层存储mongodb集群,分布式使用redis实现,
爬虫状态显示使用graphite实现。
这个工程是我对垂直搜索引擎中分布式网络爬虫的探索实现,它包含一个针对http://www.woaidu.org/ 网站的spider,
将其网站的书名,作者,书籍封面图片,书籍概要,原始网址链接,书籍下载信息和书籍爬取到本地:
* 分布式使用redis实现,redis中存储了工程的request,stats信息,能够对各个机器上的爬虫实现集中管理,这样可以
解决爬虫的性能瓶颈,利用redis的高效和易于扩展能够轻松实现高效率下载:当redis存储或者访问速度遇到瓶颈时,可以
通过增大redis集群数和爬虫集群数量改善。
* 底层存储实现了两种方式:
* 将书名,作者,书籍封面图片文件系统路径,书籍概要,原始网址链接,书籍下载信息,书籍文件系统路径保存到mongodb
中,此时mongodb使用单个服务器,对图片采用图片的url的hash值作为文件名进行存储,同时可以定制生成各种大小尺寸的缩略
图,对文件动态获得文件名,将其下载到本地,存储方式和图片类似,这样在每次下载之前会检查图片和文件是否曾经下载,对
已经下载的不再下载;
* 将书名,作者,书籍封面图片文件系统路径,书籍概要,原始网址链接,书籍下载信息,书籍保存到mongodb中,此时mongodb
采用mongodb集群进行存储,片键和索引的选择请看代码,文件采用mongodb的gridfs存储,图片仍然存储在文件系统中,在每次下载
之前会检查图片和文件是否曾经下载,对已经下载的不再下载;
* 避免爬虫被禁的策略:
* 禁用cookie
* 实现了一个download middleware,不停的变user-aget
* 实现了一个可以访问google cache中的数据的download middleware(默认禁用)
* 调试策略的实现:
* 将系统log信息写到文件中
* 对重要的log信息(eg:drop item,success)采用彩色样式终端打印
* 文件,信息存储:
* 实现了FilePipeline可以将指定扩展名的文件下载到本地
* 实现了MongodbWoaiduBookFile可以将文件以gridfs形式存储在mongodb集群中
* 实现了SingleMongodbPipeline和ShardMongodbPipeline,用来将采集的信息分别以单服务器和集群方式保存到mongodb中
* 访问速度动态控制:
* 跟据网络延迟,分析出scrapy服务器和网站的响应速度,动态改变网站下载延迟
* 配置最大并行requests个数,每个域名最大并行请求个数和并行处理items个数
* 爬虫状态查看:
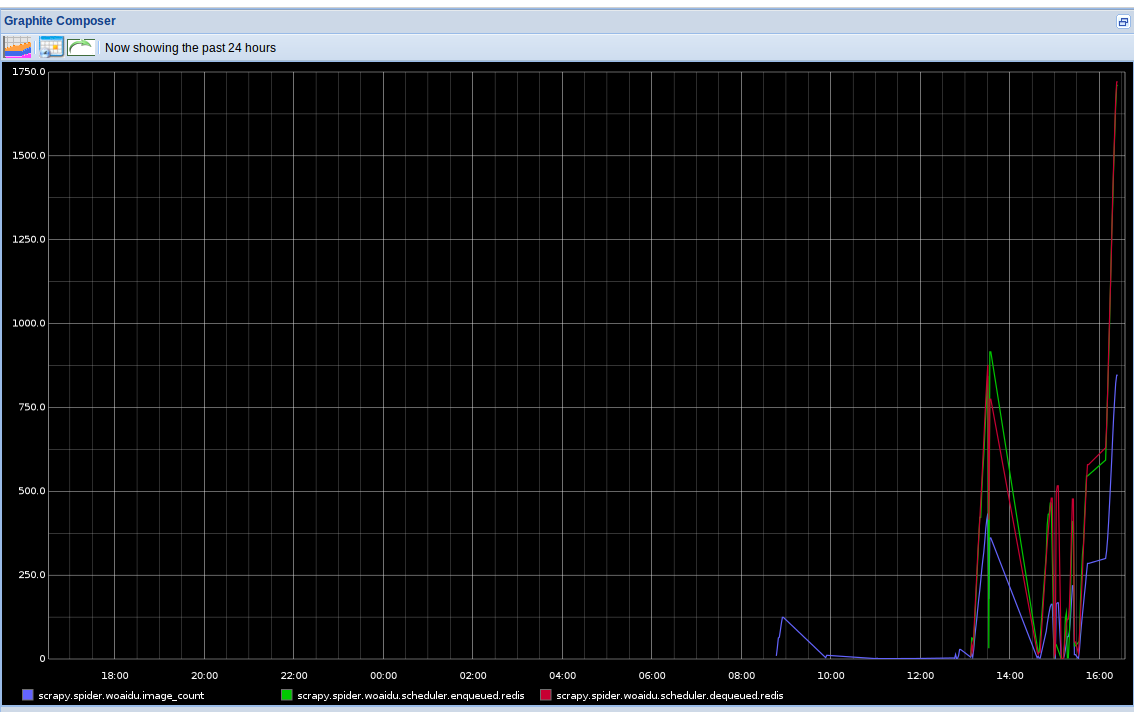
* 将爬虫stats信息(请求个数,文件下载个数,图片下载个数等)保存到redis中
* 实现了一个针对分布式的stats collector,并将其结果用graphite以图表形式动态实时显示
* mongodb集群部署:在commands目录下有init_sharding_mongodb.py文件,可以方便在本地部署
需要的其他的库
==============
* scrapy(最好是最新版)
* graphite(针对他的配置可以参考:statscol/graphite.py)
* redis
* mongodb
可重用的组件
============
* 终端彩色样式显示(utils/color.py)
* 在本地建立一个mongodb集群(commands/init_sharding_mongodb.py),使用方法:
```
sudo python init_sharding_mongodb.py --path=/usr/bin
```
* 单机graphite状态收集器(statscol.graphite.GraphiteStatsCollector)
* 基于redis分布式的graphite状态收集器(statscol.graphite.RedisGraphiteStatsCollector)
* scrapy分布式处理方案(scrapy_redis)
* rotate user-agent download middleware(contrib.downloadmiddleware.rotate_useragent.RotateUserAgentMiddleware)
* 访问google cache的download middleware(contrib.downloadmiddleware.google_cache.GoogleCacheMiddleware)
* 下载指定文件类型的文件并实现避免重复下载的pipeline(pipelines.file.FilePipeline)
* 下载制定文件类型的文件并提供mongodb gridfs存储的pipeline(pipelines.file.MongodbWoaiduBookFile)
* item mongodb存储的pipeline(pipelines.mongodb.SingleMongodbPipeline and ShardMongodbPipeline)
使用方法
========
#mongodb集群存储
* 安装scrapy
* 安装redispy
* 安装pymongo
* 安装graphite(如何配置请查看:statscol/graphite.py)
* 安装mongodb
* 安装redis
* 下载本工程
* 启动redis server
* 搭建mongodb集群
```
cd woaidu_crawler/commands/
sudo python init_sharding_mongodb.py --path=/usr/bin
```
* 在含有log文件夹的目录下执行:
```
scrapy crawl woaidu
```
* 打开http://127.0.0.1/ 通过图表查看spider实时状态信息
* 要想尝试分布式,可以在另外一个目录运行此工程
#mongodb
* 安装scrapy
* 安装redispy
* 安装pymongo
* 安装graphite(如何配置请查看:statscol/graphite.py)
* 安装mongodb
* 安装redis
* 下载本工程
* 启动redis server
* 搭建mongodb服务器
```
cd woaidu_crawler/commands/
python init_single_mongodb.py
```
* 设置settings.py:
```python
ITEM_PIPELINES = ['woaidu_crawler.pipelines.cover_image.WoaiduCoverImage',
'woaidu_crawler.pipelines.bookfile.WoaiduBookFile',
'woaidu_crawler.pipelines.drop_none_download.DropNoneBookFile',
'woaidu_crawler.pipelines.mongodb.SingleMongodbPipeline',
'woaidu_crawler.pipelines.final_test.FinalTestPipeline',]
```
* 在含有log文件夹的目录下执行:
```
scrapy crawl woaidu
```
* 打开http://127.0.0.1/ (也就是你运行的graphite-web的url) 通过图表查看spider实时状态信息
* 要想尝试分布式,可以在另外一个目录运行此工程
注意
====
每次运行完之后都要执行commands/clear_stats.py文件来清除redis中的stats信息
```
python clear_stats.py
```
Screenshots
===========

计算机毕业设计:python+爬虫+爬爱书网

需积分: 0 188 浏览量
更新于2024-11-08
收藏 9.78MB ZIP 举报
distribute_crawler
==================
使用scrapy,redis, mongodb,graphite实现的一个分布式网络爬虫,底层存储mongodb集群,分布式使用redis实现,
爬虫状态显示使用graphite实现。
这个工程是我对垂直搜索引擎中分布式网络爬虫的探索实现,它包含一个针对http://www.woaidu.org/ 网站的spider,
将其网站的书名,作者,书籍封面图片,书籍概要,原始网址链接,书籍下载信息和书籍爬取到本地:
* 分布式使用redis实现,redis中存储了工程的request,stats信息,能够对各个机器上的爬虫实现集中管理,这样可以
解决爬虫的性能瓶颈,利用redis的高效和易于扩展能够轻松实现高效率下载:当redis存储或者访问速度遇到瓶颈时,可以
通过增大redis集群数和爬虫集群数量改善。
* 底层存储实现了两种方式:
* 将书名,作者,书籍封面图片文件系统路径,书籍概要,原始网址链接,书籍下载信息,书籍文件系统路径保存到mongodb
中,此时mongodb使用单个服务器,对图片采用图片的
 计算机毕业设计:python+爬虫+爬爱书网 (983个子文件)
计算机毕业设计:python+爬虫+爬爱书网 (983个子文件)  scrapy.cfg 110B
scrapy.cfg 110B 08fb1d8db8fbdbb4577207dc3013c7826aa1f16f.jpg 710KB d8f8782e7bd0d9033efc8b5e3e01ef1dcf81ebd6.jpg 238KB b2b8caddd1a2025b154ca62c796a9c5d3299fe07.jpg 88KB ea543b98a5d116e077e89789428e2ff1cc364d76.jpg 84KB 9876a80aa4f84ab797b4a75fc9bee28fa50cf3c5.jpg 77KB 56fd785f61d3caf2c6c044f6a4eca319bd8dc64b.jpg 70KB d97232fa8b1d76153fc1237e3143f29fef058357.jpg 67KB 1fcaa1a947322e12f1818816b4476cd397e47eaa.jpg 55KB 0e5df4346f95d4569f6b8048a67cbf01a55e7b19.jpg 53KB 958d99535491469acab9a679320ec62080498d76.jpg 51KB a9be2ed4a030c4b50b1eebcb820dd96cdd260a9c.jpg 47KB e198dcde5c65c69969ac3f9e953e66f6d5fd1a78.jpg 39KB cace7b88cdf11d9c43079be11057054639384079.jpg 37KB 4482c5a68b566908cab7238a7698c97b6b7b8eda.jpg 34KB 3ef50e7f1c43c1946e7886d83f4784ed16d40317.jpg 32KB 5ba548d2b748941d34057117d752c716eda40fee.jpg 27KB e9f9daca2e6cec195c1d12c0a5000a763a1726fa.jpg 24KB 4ea6023e4d270e949d91d1190355d33f6138db2b.jpg 24KB 3f7876a487acd2de50919123216faafd895a61d6.jpg 23KB 76fe6f2f1ae6aa94e8eca16f616b8674e40d5330.jpg 21KB 76fe6f2f1ae6aa94e8eca16f616b8674e40d5330.jpg 21KB 5ba548d2b748941d34057117d752c716eda40fee.jpg 21KB 8de771eb440f5211df9893399a77954d9f8084bd.jpg 21KB 0c771760340001f29f0b7079526b38ff2d807f44.jpg 20KB 5426f759f0423369d96d6428a9a73da8ec034e07.jpg 20KB 5426f759f0423369d96d6428a9a73da8ec034e07.jpg 20KB 871e3d73c0408e72f3e8065d406087a933c8e153.jpg 20KB 3f7876a487acd2de50919123216faafd895a61d6.jpg 20KB d0217dcec23be8ad1fdabd092c8cb381249562bd.jpg 19KB fcb7213b7c394a9f81564ac80f7dd77b7bed2ff7.jpg 19KB fcb7213b7c394a9f81564ac80f7dd77b7bed2ff7.jpg 19KB 76bd3c97f53764518adbcd5d4b98e69da405ec2b.jpg 19KB bdaaab85e047946e825bf3a1b108a289bbb28a8c.jpg 19KB d7256a829319b1583e00fcb36ad85b0910641695.jpg 19KB d7256a829319b1583e00fcb36ad85b0910641695.jpg 19KB e9f9daca2e6cec195c1d12c0a5000a763a1726fa.jpg 18KB deb424bf196828d65b4263d31c44c923123a1f64.jpg 18KB 4cf176895b7b2a3edc29edff94404fe044f8d123.jpg 18KB 4cf176895b7b2a3edc29edff94404fe044f8d123.jpg 18KB 758547a9a9eb6d6958b731db03b9396238f11ebf.jpg 18KB a52874f1615da1f96f2786f37bae51272c0cd090.jpg 18KB cace7b88cdf11d9c43079be11057054639384079.jpg 17KB 2087f03016f463a4c1e41c5abd22cf66929a4a0e.jpg 17KB 2087f03016f463a4c1e41c5abd22cf66929a4a0e.jpg 17KB 65d5683c242d07aa228e5b053fb28a6e798ba130.jpg 17KB e7a222499927bfb9e2a9332c6da9d14f2a8a9e0c.jpg 17KB 2501202566fd7ed7e5fb9ebb17f8f78ecdc3d87f.jpg 17KB 2501202566fd7ed7e5fb9ebb17f8f78ecdc3d87f.jpg 17KB 649d02927f1fcb96a475d265e1b3957e06132410.jpg 17KB a63f8895bd9695546eb2a6eb038fb2de6e37151b.jpg 17KB a63f8895bd9695546eb2a6eb038fb2de6e37151b.jpg 17KB c39ee206e84b067eedec3569abd6507bca0acc2e.jpg 17KB c39ee206e84b067eedec3569abd6507bca0acc2e.jpg 17KB cf42864d660418cde81af6128d53c1f3ddfbef1e.jpg 17KB cf42864d660418cde81af6128d53c1f3ddfbef1e.jpg 17KB 4a5ff449eae0f4e47c63c6dccd2845bd30e96d2e.jpg 17KB 4a5ff449eae0f4e47c63c6dccd2845bd30e96d2e.jpg 17KB 758547a9a9eb6d6958b731db03b9396238f11ebf.jpg 16KB bdb5903f09e4efaf1e122d9ef298fb3710648b84.jpg 16KB 0c771760340001f29f0b7079526b38ff2d807f44.jpg 16KB 327accb933fd1c4ecb341855bb71e4cacd4a6de2.jpg 16KB 327accb933fd1c4ecb341855bb71e4cacd4a6de2.jpg 16KB fcd3ad96d81f3a659f4967416c8b101c2aa8f384.jpg 16KB 12d6989f8dd00e508f8216a7ef92519b9f8bf9c4.jpg 16KB 12d6989f8dd00e508f8216a7ef92519b9f8bf9c4.jpg 16KB 65d5683c242d07aa228e5b053fb28a6e798ba130.jpg 16KB d302317ef5fd37008d082c691d280c0af6f3803e.jpg 16KB d302317ef5fd37008d082c691d280c0af6f3803e.jpg 16KB 02a22a0f2e09dcedd321e9b16e892e3930c0322b.jpg 16KB 02a22a0f2e09dcedd321e9b16e892e3930c0322b.jpg 16KB 871e3d73c0408e72f3e8065d406087a933c8e153.jpg 16KB dbf172fadb89a03383cc68d0a168cb05d5cf7093.jpg 16KB c7437b31a86eaf9bf69070a4637dc4ef8ed1cf12.jpg 15KB dbf172fadb89a03383cc68d0a168cb05d5cf7093.jpg 15KB fcd3ad96d81f3a659f4967416c8b101c2aa8f384.jpg 15KB 958d99535491469acab9a679320ec62080498d76.jpg 15KB a5bbec9dc0ffa81ab8537979a57070fafcfb052b.jpg 15KB 05c4f0c9bdd2c70423a1a85ab2d53c3c9cd20fd5.jpg 15KB cb632c6f28f6884ddeb69d7d97a3329a75d030e9.jpg 15KB 3ef50e7f1c43c1946e7886d83f4784ed16d40317.jpg 15KB bedaf1f617156c9e89934a7a1bbedf51dc450950.jpg 15KB bedaf1f617156c9e89934a7a1bbedf51dc450950.jpg 15KB 828f559bf880728f834c20b7eaf079f936e22c74.jpg 15KB 828f559bf880728f834c20b7eaf079f936e22c74.jpg 15KB b2b8caddd1a2025b154ca62c796a9c5d3299fe07.jpg 15KB 8de771eb440f5211df9893399a77954d9f8084bd.jpg 15KB 71954f465f5aeedf400ca92fb18c5d2b359105e7.jpg 15KB 649d02927f1fcb96a475d265e1b3957e06132410.jpg 15KB 4d5bf0e0571b1a7ae491dabb1824894b9bd29151.jpg 14KB 4d5bf0e0571b1a7ae491dabb1824894b9bd29151.jpg 14KB 09432ca24329f10b7627fa09cb0b3852c94a987d.jpg 14KB 09432ca24329f10b7627fa09cb0b3852c94a987d.jpg 14KB c98945536d107be9ba21a38bb1cc013572e4ba05.jpg 14KB c98945536d107be9ba21a38bb1cc013572e4ba05.jpg 14KB d0217dcec23be8ad1fdabd092c8cb381249562bd.jpg 14KB c7437b31a86eaf9bf69070a4637dc4ef8ed1cf12.jpg 14KB df91567303dc4b86feb87c77699437c354a1a9c4.jpg 14KB df91567303dc4b86feb87c77699437c354a1a9c4.jpg 14KB 655f87d07df8670c7a024000009108e3f870805e.jpg 14KB
08fb1d8db8fbdbb4577207dc3013c7826aa1f16f.jpg 710KB d8f8782e7bd0d9033efc8b5e3e01ef1dcf81ebd6.jpg 238KB b2b8caddd1a2025b154ca62c796a9c5d3299fe07.jpg 88KB ea543b98a5d116e077e89789428e2ff1cc364d76.jpg 84KB 9876a80aa4f84ab797b4a75fc9bee28fa50cf3c5.jpg 77KB 56fd785f61d3caf2c6c044f6a4eca319bd8dc64b.jpg 70KB d97232fa8b1d76153fc1237e3143f29fef058357.jpg 67KB 1fcaa1a947322e12f1818816b4476cd397e47eaa.jpg 55KB 0e5df4346f95d4569f6b8048a67cbf01a55e7b19.jpg 53KB 958d99535491469acab9a679320ec62080498d76.jpg 51KB a9be2ed4a030c4b50b1eebcb820dd96cdd260a9c.jpg 47KB e198dcde5c65c69969ac3f9e953e66f6d5fd1a78.jpg 39KB cace7b88cdf11d9c43079be11057054639384079.jpg 37KB 4482c5a68b566908cab7238a7698c97b6b7b8eda.jpg 34KB 3ef50e7f1c43c1946e7886d83f4784ed16d40317.jpg 32KB 5ba548d2b748941d34057117d752c716eda40fee.jpg 27KB e9f9daca2e6cec195c1d12c0a5000a763a1726fa.jpg 24KB 4ea6023e4d270e949d91d1190355d33f6138db2b.jpg 24KB 3f7876a487acd2de50919123216faafd895a61d6.jpg 23KB 76fe6f2f1ae6aa94e8eca16f616b8674e40d5330.jpg 21KB 76fe6f2f1ae6aa94e8eca16f616b8674e40d5330.jpg 21KB 5ba548d2b748941d34057117d752c716eda40fee.jpg 21KB 8de771eb440f5211df9893399a77954d9f8084bd.jpg 21KB 0c771760340001f29f0b7079526b38ff2d807f44.jpg 20KB 5426f759f0423369d96d6428a9a73da8ec034e07.jpg 20KB 5426f759f0423369d96d6428a9a73da8ec034e07.jpg 20KB 871e3d73c0408e72f3e8065d406087a933c8e153.jpg 20KB 3f7876a487acd2de50919123216faafd895a61d6.jpg 20KB d0217dcec23be8ad1fdabd092c8cb381249562bd.jpg 19KB fcb7213b7c394a9f81564ac80f7dd77b7bed2ff7.jpg 19KB fcb7213b7c394a9f81564ac80f7dd77b7bed2ff7.jpg 19KB 76bd3c97f53764518adbcd5d4b98e69da405ec2b.jpg 19KB bdaaab85e047946e825bf3a1b108a289bbb28a8c.jpg 19KB d7256a829319b1583e00fcb36ad85b0910641695.jpg 19KB d7256a829319b1583e00fcb36ad85b0910641695.jpg 19KB e9f9daca2e6cec195c1d12c0a5000a763a1726fa.jpg 18KB deb424bf196828d65b4263d31c44c923123a1f64.jpg 18KB 4cf176895b7b2a3edc29edff94404fe044f8d123.jpg 18KB 4cf176895b7b2a3edc29edff94404fe044f8d123.jpg 18KB 758547a9a9eb6d6958b731db03b9396238f11ebf.jpg 18KB a52874f1615da1f96f2786f37bae51272c0cd090.jpg 18KB cace7b88cdf11d9c43079be11057054639384079.jpg 17KB 2087f03016f463a4c1e41c5abd22cf66929a4a0e.jpg 17KB 2087f03016f463a4c1e41c5abd22cf66929a4a0e.jpg 17KB 65d5683c242d07aa228e5b053fb28a6e798ba130.jpg 17KB e7a222499927bfb9e2a9332c6da9d14f2a8a9e0c.jpg 17KB 2501202566fd7ed7e5fb9ebb17f8f78ecdc3d87f.jpg 17KB 2501202566fd7ed7e5fb9ebb17f8f78ecdc3d87f.jpg 17KB 649d02927f1fcb96a475d265e1b3957e06132410.jpg 17KB a63f8895bd9695546eb2a6eb038fb2de6e37151b.jpg 17KB a63f8895bd9695546eb2a6eb038fb2de6e37151b.jpg 17KB c39ee206e84b067eedec3569abd6507bca0acc2e.jpg 17KB c39ee206e84b067eedec3569abd6507bca0acc2e.jpg 17KB cf42864d660418cde81af6128d53c1f3ddfbef1e.jpg 17KB cf42864d660418cde81af6128d53c1f3ddfbef1e.jpg 17KB 4a5ff449eae0f4e47c63c6dccd2845bd30e96d2e.jpg 17KB 4a5ff449eae0f4e47c63c6dccd2845bd30e96d2e.jpg 17KB 758547a9a9eb6d6958b731db03b9396238f11ebf.jpg 16KB bdb5903f09e4efaf1e122d9ef298fb3710648b84.jpg 16KB 0c771760340001f29f0b7079526b38ff2d807f44.jpg 16KB 327accb933fd1c4ecb341855bb71e4cacd4a6de2.jpg 16KB 327accb933fd1c4ecb341855bb71e4cacd4a6de2.jpg 16KB fcd3ad96d81f3a659f4967416c8b101c2aa8f384.jpg 16KB 12d6989f8dd00e508f8216a7ef92519b9f8bf9c4.jpg 16KB 12d6989f8dd00e508f8216a7ef92519b9f8bf9c4.jpg 16KB 65d5683c242d07aa228e5b053fb28a6e798ba130.jpg 16KB d302317ef5fd37008d082c691d280c0af6f3803e.jpg 16KB d302317ef5fd37008d082c691d280c0af6f3803e.jpg 16KB 02a22a0f2e09dcedd321e9b16e892e3930c0322b.jpg 16KB 02a22a0f2e09dcedd321e9b16e892e3930c0322b.jpg 16KB 871e3d73c0408e72f3e8065d406087a933c8e153.jpg 16KB dbf172fadb89a03383cc68d0a168cb05d5cf7093.jpg 16KB c7437b31a86eaf9bf69070a4637dc4ef8ed1cf12.jpg 15KB dbf172fadb89a03383cc68d0a168cb05d5cf7093.jpg 15KB fcd3ad96d81f3a659f4967416c8b101c2aa8f384.jpg 15KB 958d99535491469acab9a679320ec62080498d76.jpg 15KB a5bbec9dc0ffa81ab8537979a57070fafcfb052b.jpg 15KB 05c4f0c9bdd2c70423a1a85ab2d53c3c9cd20fd5.jpg 15KB cb632c6f28f6884ddeb69d7d97a3329a75d030e9.jpg 15KB 3ef50e7f1c43c1946e7886d83f4784ed16d40317.jpg 15KB bedaf1f617156c9e89934a7a1bbedf51dc450950.jpg 15KB bedaf1f617156c9e89934a7a1bbedf51dc450950.jpg 15KB 828f559bf880728f834c20b7eaf079f936e22c74.jpg 15KB 828f559bf880728f834c20b7eaf079f936e22c74.jpg 15KB b2b8caddd1a2025b154ca62c796a9c5d3299fe07.jpg 15KB 8de771eb440f5211df9893399a77954d9f8084bd.jpg 15KB 71954f465f5aeedf400ca92fb18c5d2b359105e7.jpg 15KB 649d02927f1fcb96a475d265e1b3957e06132410.jpg 15KB 4d5bf0e0571b1a7ae491dabb1824894b9bd29151.jpg 14KB 4d5bf0e0571b1a7ae491dabb1824894b9bd29151.jpg 14KB 09432ca24329f10b7627fa09cb0b3852c94a987d.jpg 14KB 09432ca24329f10b7627fa09cb0b3852c94a987d.jpg 14KB c98945536d107be9ba21a38bb1cc013572e4ba05.jpg 14KB c98945536d107be9ba21a38bb1cc013572e4ba05.jpg 14KB d0217dcec23be8ad1fdabd092c8cb381249562bd.jpg 14KB c7437b31a86eaf9bf69070a4637dc4ef8ed1cf12.jpg 14KB df91567303dc4b86feb87c77699437c354a1a9c4.jpg 14KB df91567303dc4b86feb87c77699437c354a1a9c4.jpg 14KB 655f87d07df8670c7a024000009108e3f870805e.jpg 14KB共 983 条
- 1
- 2
- 3
- 4
- 5
- 6
- 10
2024-11-12 上传
151 浏览量
133 浏览量
2024-11-08 上传
2024-11-01 上传
130 浏览量
152 浏览量
188 浏览量
191 浏览量
2024-04-30 上传
2024-11-04 上传
116 浏览量
2024-06-17 上传
185 浏览量
2024-07-14 上传
2024-11-13 上传
2023-09-09 上传
122 浏览量
173 浏览量
185 浏览量
101 浏览量
130 浏览量
资源评论



铭瑾熙
- 粉丝: 832
- 资源: 55









最新资源
- 基于小程序的校园失物招领源码(小程序毕业设计完整源码+LW).zip
- 基于小程序的图书管理系统源码(小程序毕业设计完整源码+LW).zip
- 基于小程序的学生选课系统源码(小程序毕业设计完整源码+LW).zip
- 气动举升输送机sw18可编辑全套技术资料100%好用.zip
- 基于小程序的英语学习激励系统源码(小程序毕业设计完整源码+LW).zip
- 汽车密封条自动打孔裁断一体机sw18可编辑全套技术资料100%好用.zip
- 基于小程序的驾校预约管理系统源码(小程序毕业设计完整源码+LW).zip
- 汽车油泵盖组装机sw18可编辑全套技术资料100%好用.zip
- 智慧混凝土管理系统功能说明
- 美国芝加哥矢量边界shp 2024版
- JAVA大作业贪吃蛇-加上mysql数据库-课程设计
- 去镍机sw20可编辑全套技术资料100%好用.zip
- 全自动充磁机(含DFM)sw17可编辑全套技术资料100%好用.zip
- content_1735747612598.zip
- 全自动贴膜机(含cad)stp全套技术资料100%好用.zip
- 柔性链输送机设备sw18可编辑全套技术资料100%好用.zip
