

Deep Image Retrieval:
Learning global representations for image search
Albert Gordo, Jon Almaz´an, Jerome Revaud, and Diane Larlus
Computer Vision Group, Xerox Research Center Europe
firstname.lastname@xrce.xerox.com
Abstract. We propose a novel approach for instance-level image re-
trieval. It produces a global and compact fixed-length representation for
each image by aggregating many region-wise descriptors. In contrast to
previous works employing pre-trained deep networks as a black box to
produce features, our method leverages a deep architecture trained for
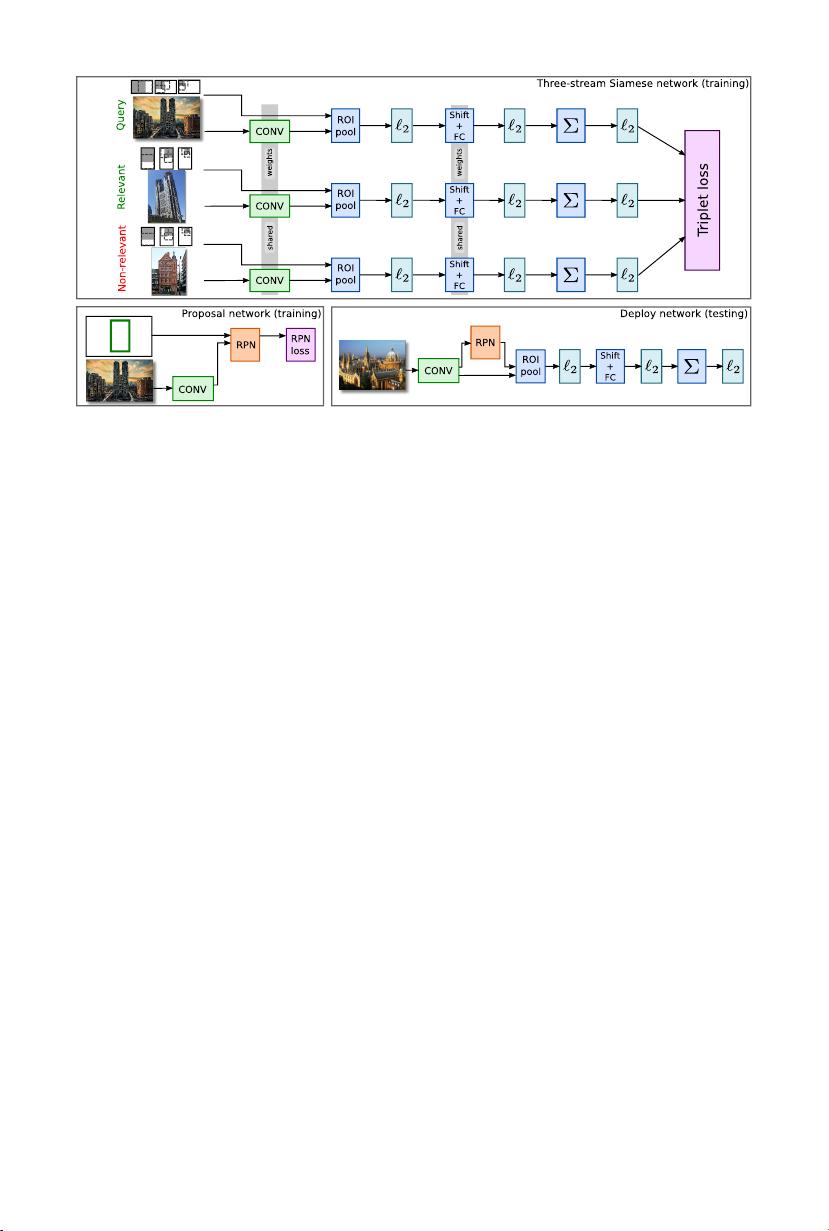
the specific task of image retrieval. Our contribution is twofold: (i) we
leverage a ranking framework to learn convolution and projection weights
that are used to build the region features; and (ii) we employ a region
proposal network to learn which regions should be pooled to form the fi-
nal global descriptor. We show that using clean training data is key to the
success of our approach. To that aim, we use a large scale but noisy land-
mark dataset and develop an automatic cleaning approach. The proposed
architecture produces a global image representation in a single forward
pass. Our approach significantly outperforms previous approaches based
on global descriptors on standard datasets. It even surpasses most prior
works based on costly local descriptor indexing and spatial verification
1
.
Keywords: deep learning, instance-level retrieval
1 Introduction
Since their ground-breaking results on image classification in recent ImageNet
challenges [1,2], deep learning based methods have shined in many other com-
puter vision tasks, including object detection [3] and semantic segmentation [4].
Recently, they also rekindled highly semantic tasks such as image captioning [5,6]
and visual question answering [7]. However, for some problems such as instance-
level image retrieval, deep learning methods have led to rather underwhelming
results. In fact, for most image retrieval benchmarks, the state of the art is cur-
rently held by conventional methods relying on local descriptor matching and
re-ranking with elaborate spatial verification [8,9,10,11].
Recent works leveraging deep architectures for image retrieval are mostly
limited to using a pre-trained network as local feature extractor. Most efforts
have been devoted towards designing image representations suitable for image
retrieval on top of those features. This is challenging because representations for
1
Additional material available at www.xrce.xerox.com/Deep-Image-Retrieval
arXiv:1604.01325v2 [cs.CV] 28 Jul 2016


剩余20页未读,继续阅读
资源评论













