oversubscribed command queues in gpus
需积分: 5 73 浏览量
2023-09-20
16:27:41
上传
评论
收藏 1.16MB PDF 举报


1
Permission to make digital or hard copies of all or part of this work for personal or
classroom use is granted without fee provided that copies are not made or distributed
for profit or commercial advantage and that copies bear this notice and the full citation
on the first page. Copyrights for components of this work owned by others than ACM
must be honored. Abstracting with credit is permitted. To copy otherwise, or republish,
to post on servers or to redistribute to lists, requires prior specific permission and/or a
fee. Request permissions from Permissions@acm.org.
GPGPU-11, February 24–28, 2018, Vienna, Austria
© 2018 Association for Computing Machinery.
ACM ISBN 978-1-4503-5647-3/18/02…$15.00
https://doi.org/10.1145/3180270.3180271
Oversubscribed Command Queues in GPUs
Sooraj Puthoor
AMD Research
Sooraj.Puthoor@amd.com
Xulong Tang
Penn State
xzt102@cse.psu.edu
Joseph Gross
AMD Research
Joe.Gross@amd.com
Bradford M. Beckmann
AMD Research
Brad.Beckmann@amd.com
Abstract
As GPUs become larger and provide an increasing number of
parallel execution units, a single kernel is no longer sufficient to
utilize all available resources. As a result, GPU applications are
beginning to use fine-grain asynchronous kernels, which are
executed in parallel and expose more concurrency. Currently, the
Heterogeneous System Architecture (HSA) and Compute Unified
Device Architecture (CUDA) specifications support concurrent
kernel launches with the help of multiple command queues (a.k.a.
HSA queues and CUDA streams, respectively). In conjunction,
GPU hardware has decreased launch overheads making fine-grain
kernels more attractive.
Although increasing the number of command queues is good for
kernel concurrency, the GPU hardware can only monitor a fixed
number of queues at any given time. Therefore, if the number of
command queues exceeds hardware’s monitoring capability, the
queues become oversubscribed and hardware has to service some
of these queues sequentially. This mapping process periodically
swaps between all allocated queues and limits the available
concurrency to the ready kernels in the currently mapped queues.
In this paper, we bring to attention the queue oversubscription
challenge and demonstrate one solution, queue prioritization,
which provides up to 45x speedup for NW benchmark against the
baseline that swaps queues in a round-robin fashion.
CCS CONCEPTS
• Computer systems organization~Single instruction, multiple
data • Software and its engineering~Scheduling
ACM Reference format:
S. Puthoor, X. Tang, J. Gross and B. Beckmann. In GPGPU-11: In
GPGPU-11: General Purpose GPUs, February 24–28, 2018, Vienna,
Austria. ACM, New York, NY, USA, 11 pages.
DOI: https://doi.org/10.1145/3180270.3180271
1. Introduction
GPUs are continually increasing their computational resources with
the latest offerings from AMD and NVIDIA boasting impressive
performance improvements over their previous generations [1][41].
With this increase in hardware resources, there is a demand to run
a more diverse set of applications, such as machine learning, cloud
computing, graph analytics, and high performance computing
(HPC) [42][45][46][51]. While some of these workloads can
launch a single kernel large enough to completely consume the
entire GPU, many others rely on concurrent kernel launches to
utilize all available resources.
For graphics workloads, the benefits of using concurrent
kernels has been well documented [1][60]. By running multiple
rendering tasks (a.k.a. kernels) concurrently, these tasks can share
the available resources and increase utilization, leading to faster
frame rate within the same power budget. Complementary, there
have been previous works in the HPC domain that have also
increased GPU utilization by running multiple kernels concurrently
[52][56].
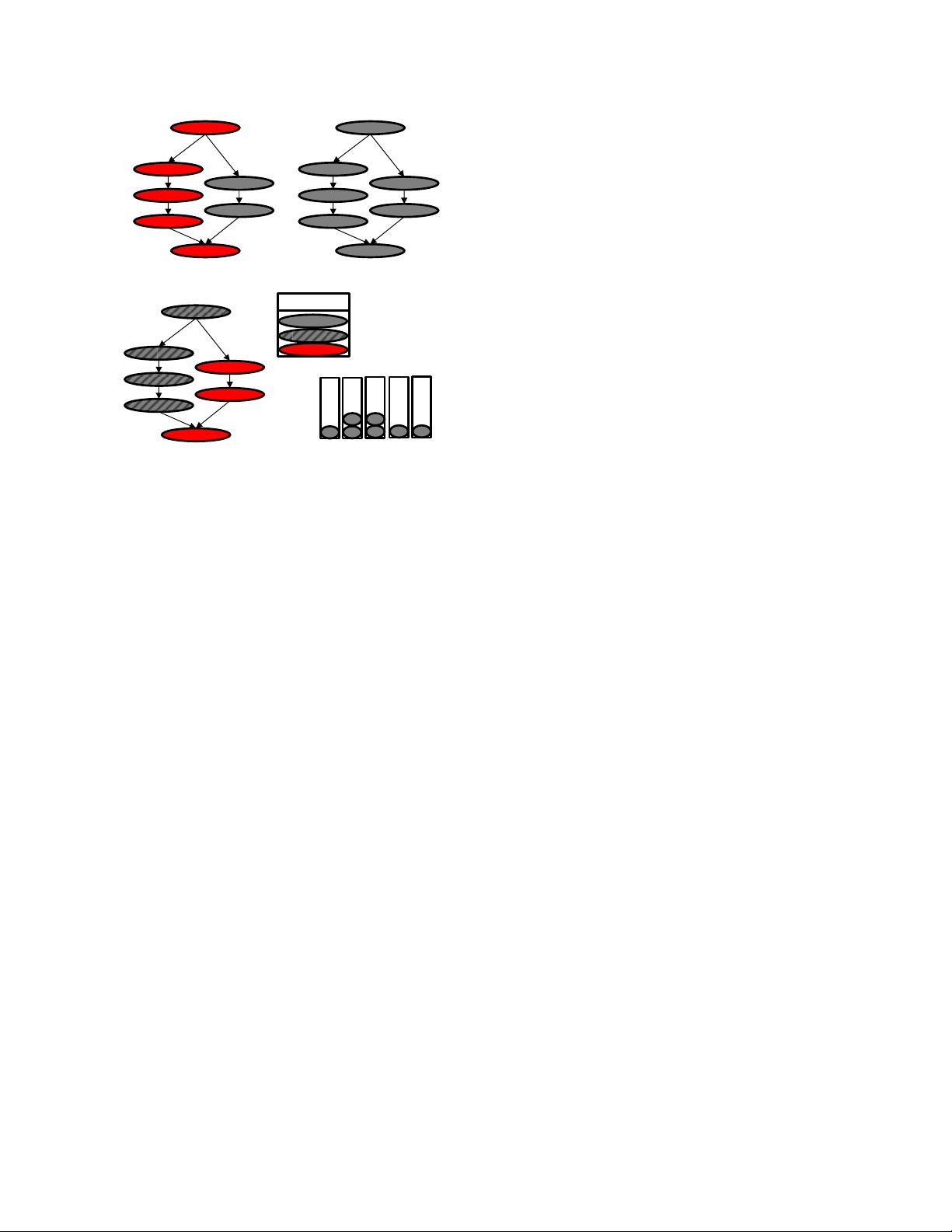
To run multiple kernels simultaneously, existing bulk-
synchronous applications are often refactored to use asynchronous
tasks. For these task-based implementations, their execution is
typically represented as a Directed Acyclic Graph (DAG) with
nodes of the DAG representing tasks and the edges representing
dependencies between tasks. From the perspective of a GPU, a task
is an instance of a GPU kernel with its associated arguments. As
the task size decreases, GPU utilization usually increases because
smaller tasks are ready to launch when a smaller fraction of data
and resources become available versus larger tasks. The idea is
similar to filling an hour glass with sand versus marbles. With sand,
the hour glass empties faster because the fine-grain particles
occupy the available free space at the narrow neck more quickly.
Of course, the benefit from running fine-grain tasks depends on
amortizing the launch overhead. This can be done by both reducing
the latency for an individual kernel launch and by allowing multiple
kernel launches simultaneously. To reduce kernel launch latency,
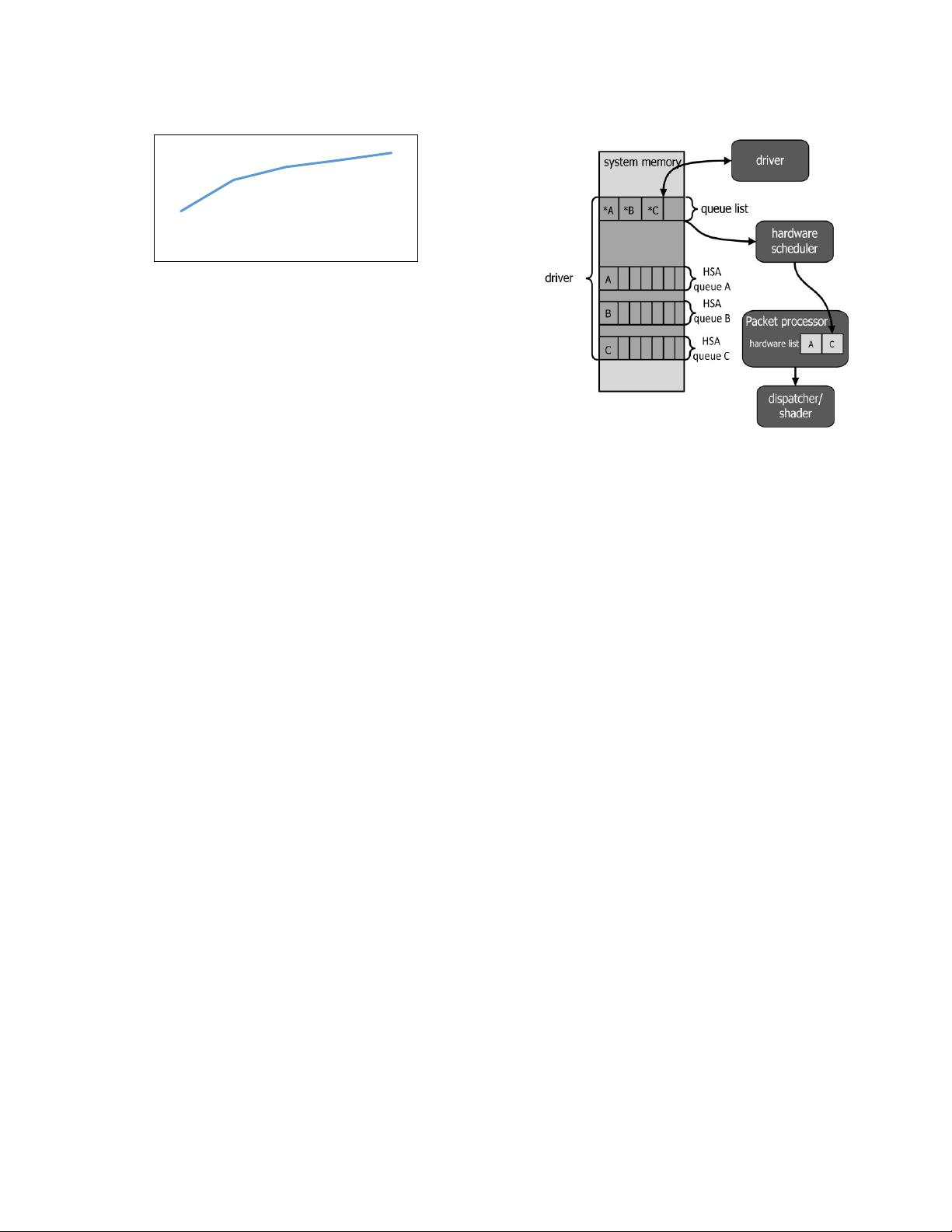
the Heterogeneous System Architecture (HSA) allows applications
to directly enqueue work into user-mode queues and avoids heavy
weight operating system (OS) or GPU driver involvement
[28][47]. To allow simultaneous kernel launches, HSA allows
applications to allocate multiple user-mode queues which hardware
can service simultaneously. Compute Unified Device Architecture
(CUDA) supports a similar feature by allowing applications to
allocate multiple streams [17]. In the extreme case, the concurrency
exposed to hardware is only limited by the virtual memory
available to queue allocation.
While hypothetically more queues expose more concurrency, it
is not feasible to build a hardware that can simultaneously monitor
many queues. Instead, when the queues created by the application
exceed the number of queues can be monitored by the hardware,
the queues are oversubscribed and the GPU must employ a
procedure to ensure all queues are eventually serviced. For
instance, periodically swapping between all queues at regular
intervals is one obvious solution.
Processing task graphs using this queue swapping mechanism
can cause performance challenges. For example, when tasks in
mapped queues are waiting for tasks in unmapped queues, GPU
utilization can suffer significantly. While hardware will eventually
map the queues with ready tasks ensuring forward progress, the
delay caused by unintelligent queue mapping leads to significant
performance degradation and the degradation becomes worse with
more complex task graphs.
剩余10页未读,继续阅读
资源评论













