Paper-自动增强技术
需积分: 5 2 浏览量
2023-11-02
09:42:43
上传
评论
收藏 1.09MB PDF 举报


AutoAugment:
Learning Augmentation Strategies from Data
Ekin D. Cubuk
∗
, Barret Zoph
∗
, Dandelion Man
´
e, Vijay Vasudevan, Quoc V. Le
Google Brain
Abstract
Data augmentation is an effective technique for improv-
ing the accuracy of modern image classifiers. However, cur-
rent data augmentation implementations are manually de-
signed. In this paper, we describe a simple procedure called
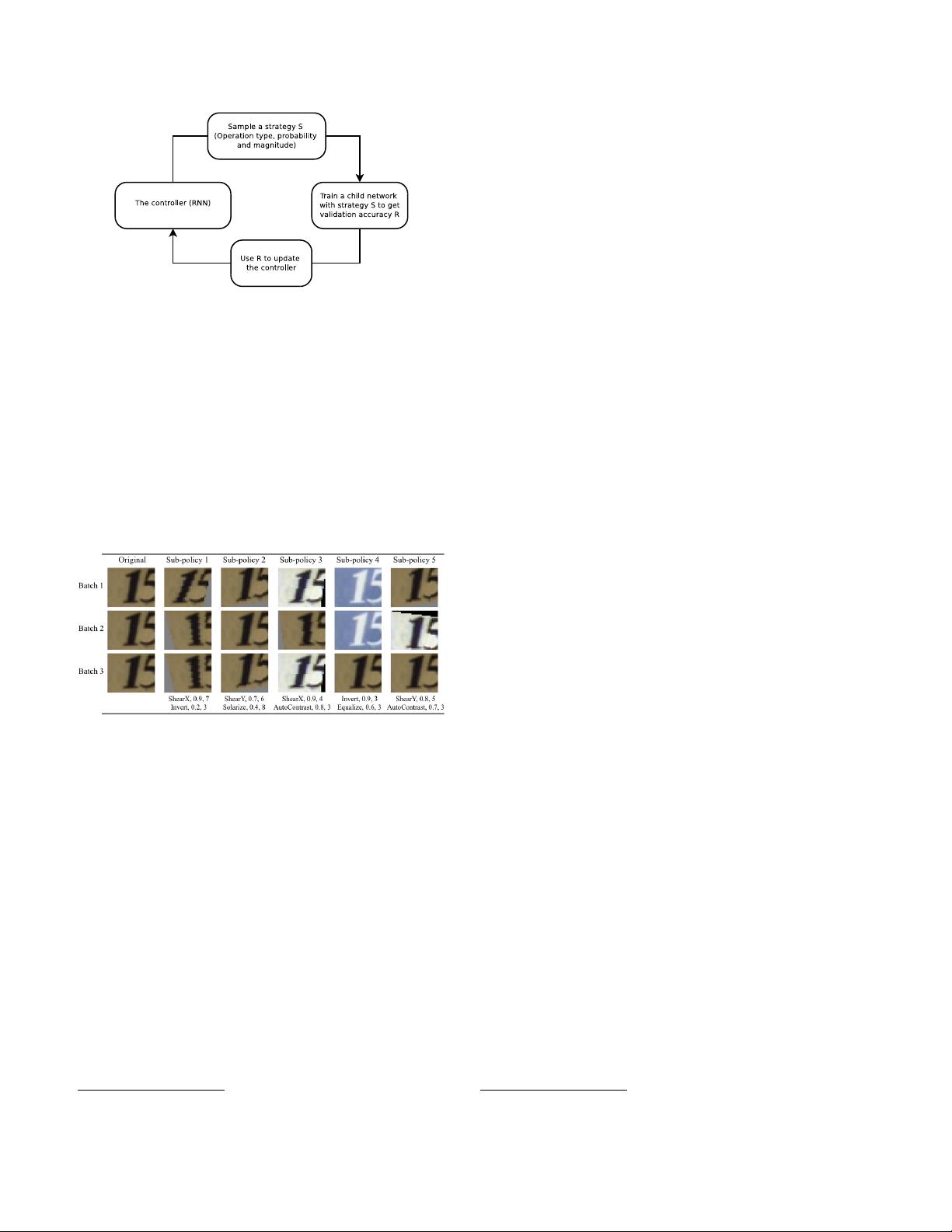
AutoAugment to automatically search for improved data
augmentation policies. In our implementation, we have de-
signed a search space where a policy consists of many sub-
policies, one of which is randomly chosen for each image
in each mini-batch. A sub-policy consists of two opera-
tions, each operation being an image processing function
such as translation, rotation, or shearing, and the probabil-
ities and magnitudes with which the functions are applied.
We use a search algorithm to find the best policy such that
the neural network yields the highest validation accuracy
on a target dataset. Our method achieves state-of-the-art
accuracy on CIFAR-10, CIFAR-100, SVHN, and ImageNet
(without additional data). On ImageNet, we attain a Top-1
accuracy of 83.5% which is 0.4% better than the previous
record of 83.1%. On CIFAR-10, we achieve an error rate of
1.5%, which is 0.6% better than the previous state-of-the-
art. Augmentation policies we find are transferable between
datasets. The policy learned on ImageNet transfers well to
achieve significant improvements on other datasets, such as
Oxford Flowers, Caltech-101, Oxford-IIT Pets, FGVC Air-
craft, and Stanford Cars.
1. Introduction
Deep neural nets are powerful machine learning systems
that tend to work well when trained on massive amounts
of data. Data augmentation is an effective technique to in-
crease both the amount and diversity of data by randomly
“augmenting” it [3, 54, 29]; in the image domain, common
augmentations include translating the image by a few pix-
els, or flipping the image horizontally. Intuitively, data aug-
mentation is used to teach a model about invariances in the
data domain: classifying an object is often insensitive to
∗
Equal contribution.
horizontal flips or translation. Network architectures can
also be used to hardcode invariances: convolutional net-
works bake in translation invariance [16, 32, 25, 29]. How-
ever, using data augmentation to incorporate potential in-
variances can be easier than hardcoding invariances into the
model architecture directly.
Dataset GPU Best published Our results
hours results
CIFAR-10 5000 2.1 1.5
CIFAR-100 0 12.2 10.7
SVHN 1000 1.3 1.0
Stanford Cars 0 5.9 5.2
ImageNet 15000 3.9 3.5
Table 1. Error rates (%) from this paper compared to the best re-
sults so far on five datasets (Top-5 for ImageNet, Top-1 for the
others). Previous best result on Stanford Cars fine-tuned weights
originally trained on a larger dataset [66], whereas we use a ran-
domly initialized network. Previous best results on other datasets
only include models that were not trained on additional data, for
a single evaluation (without ensembling). See Tables 2,3, and 4
for more detailed comparison. GPU hours are estimated for an
NVIDIA Tesla P100.
Yet a large focus of the machine learning and computer
vision community has been to engineer better network ar-
chitectures (e.g., [55, 59, 20, 58, 64, 19, 72, 23, 48]). Less
attention has been paid to finding better data augmentation
methods that incorporate more invariances. For instance,
on ImageNet, the data augmentation approach by [29], in-
troduced in 2012, remains the standard with small changes.
Even when augmentation improvements have been found
for a particular dataset, they often do not transfer to other
datasets as effectively. For example, horizontal flipping of
images during training is an effective data augmentation
method on CIFAR-10, but not on MNIST, due to the dif-
ferent symmetries present in these datasets. The need for
automatically learned data-augmentation has been raised re-
cently as an important unsolved problem [57].
In this paper, we aim to automate the process of finding
an effective data augmentation policy for a target dataset.
In our implementation (Section 3), each policy expresses
several choices and orders of possible augmentation opera-
1
arXiv:1805.09501v3 [cs.CV] 11 Apr 2019

剩余13页未读,继续阅读
资源评论


IRUIRUI__
- 粉丝: 543
- 资源: 55









最新资源
- 热设计仿真分析汇报模板,可编辑,真实项目!
- 基于YOLOv5 + Flask + Vue实现深度学习算法的垃圾检测系统源码+数据库(高分项目)
- yuuuuuuuuuuuuuuuuuu
- 打印设计软件DLL(最新版,修复了很多bug)+ 测试源码 + Dev所需全部组件(Debug目录里面)
- YOLOv5 + Flask + Vue实现基于深度学习算法的垃圾检测系统源码+数据库
- IMG_0310.jpg
- Fine Report-常用JS接口实例汇总演示
- 【Elman算法】matlab实现Elman网络预测股市开盘价.docx
- MobaXterm-telnet-ssh远程链接工具
- 微信小程序自拍人相框拍摄
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


