

13
实现
DQN
和
A2C
的强化学习方法
1. 实验环境
硬件配置
◦ 处理器:2*AMD EPYC 7773X 64-Core
◦ 内存:1.5TB
◦ 显卡:8*NVIDIA GeForce RTX 3090 24GB
工具环境
◦ Python:3.10.12
◦ Anaconda:23.7.4
◦ 系统:Ubuntu 22.04.3 LTS (GNU/Linux 5.15.0-91-generic x86_64)
◦ IDE:VS Code 1.85.1
◦ gym:0.26.2
◦ Pytorch:2.1.2
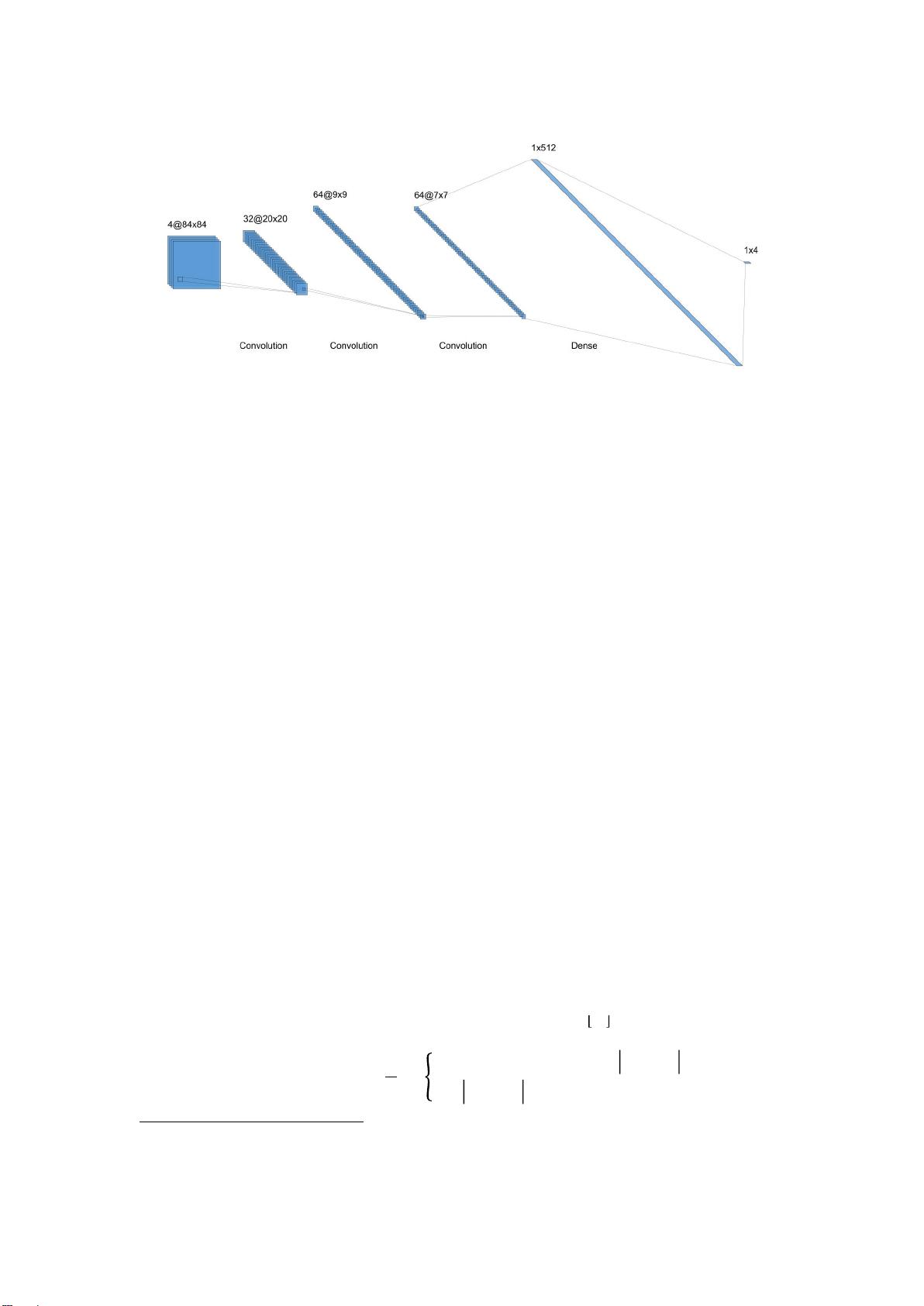
2. 实现
2.1 Breakout for Atari 2600
Breakout 是一款经典的雅达利游戏,也就是我们所熟知的“打砖块”。玩家
需要左右移动在屏幕下方的短平板子将一颗不断弹跳的小球反弹回屏幕上方,使
其将一块块矩形砖块组成的六行砖块墙面打碎,并防止小球从屏幕底部掉落。在
Atari 2600 版本的 Breakout 中,玩家共有 5 次小球掉落机会,一旦用完就标志游
戏结束,每打掉一块砖块得 1 分,全部打掉则游戏胜利结束。
图 2-1 Breakout for Atari 2600 游戏示意图


剩余19页未读,继续阅读
资源评论


一条独龙
- 粉丝: 2058
- 资源: 2









最新资源
- 企业数据分类分级操作指南
- 201-springboot养老院管理系统.zip
- 186-基于Spring Boot的电影售票系统.zip
- 156-ssm贝儿米幼儿教育管理系统-java毕业设计.zip
- VID20241125095115.mp4
- 158-ssm仓库智能仓储系统-java毕业设计.zip
- C语言实现空瓶换水问题算法解析与应用
- springboot002旅游网站.zip
- 162-java 工商局商家管理系统.zip
- 一款基于django的多用户问题管理和流程管理系统项目资源.zip
- 056-java精品项目-基于ssm的航空售票系统-带.zip
- 260-springboot基于图像识别与分类的中国蛇类识别系统.zip
- 140-java项目-ssm高校二手交易平台-带论文.zip
- 211-基于Java的社区生鲜团购系统.zip
- springboot023攀枝花市鲜花销售系统.zip
- 152-便民医疗服务小程序.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


