

通过深度强化学习实现人类水平的控制
Volodymyr Mnih
1∗
,Koray Kavukcuoglu
1∗
,
David Silver
1∗
, Andrei A. Rusu
1
...
December 13, 2018
Abstract
强化学习理论对关于智能体在一个环境中如何优化他们的行为提供了规范性的说明,其
根源是对动物行为研究得到的关于心理学和神经学的观点。在接近真实世界复杂度的情境
下,强化学习已经获得了一些成果;然而智能体也面对一些困难的挑战:必须从环境中的高
维感觉输入中得到有效的特征,并且要使用它们概括过去的经验来应付新的场景。明显地,
人类和其他动物看起来通过优雅地联合强化学习与多层次感觉处理系统来处理这些问题,大
量神经数据证明神经元发射的多巴胺相位信号与时间差分强化学习算法有明显的相似。当强
化学习智能体在多领域获得成功,它们的适用性以前仅限于可以手工制作有用特性的领域,
或者可以被完全观察、处于低维状态空间的领域。因此我们最近提出了通过训练深度神经网
络来开发一个称为“Deep Q-Network”的新型人工智能体,它可以通过高维感觉输入直
接学习成功的策略来实现端到端的强化学习。我们在传统 Atari2600 游戏挑战领域测试了
这个智能体。我们确信深度 Q 网络智能体仅仅从像素和游戏得分获取输入,使用相同的算
法、网络结构和超参数实现了对于 49 个游戏与专业人类游戏测试人员同等级别的表现,能
够超越以前所有算法。这项工作链接了高维感觉输入和行动,从而产生了第一个能够在各种
挑战中学习性能优异的人工智能体。
1 前言
我们打算创造一个单一算法,使其能够在多种具有挑战性的任务上做范围广泛的开发——
一个一般人工智能已经放弃努力的核心目标。为了达到这个目的,我们开发了一种新型智能体,
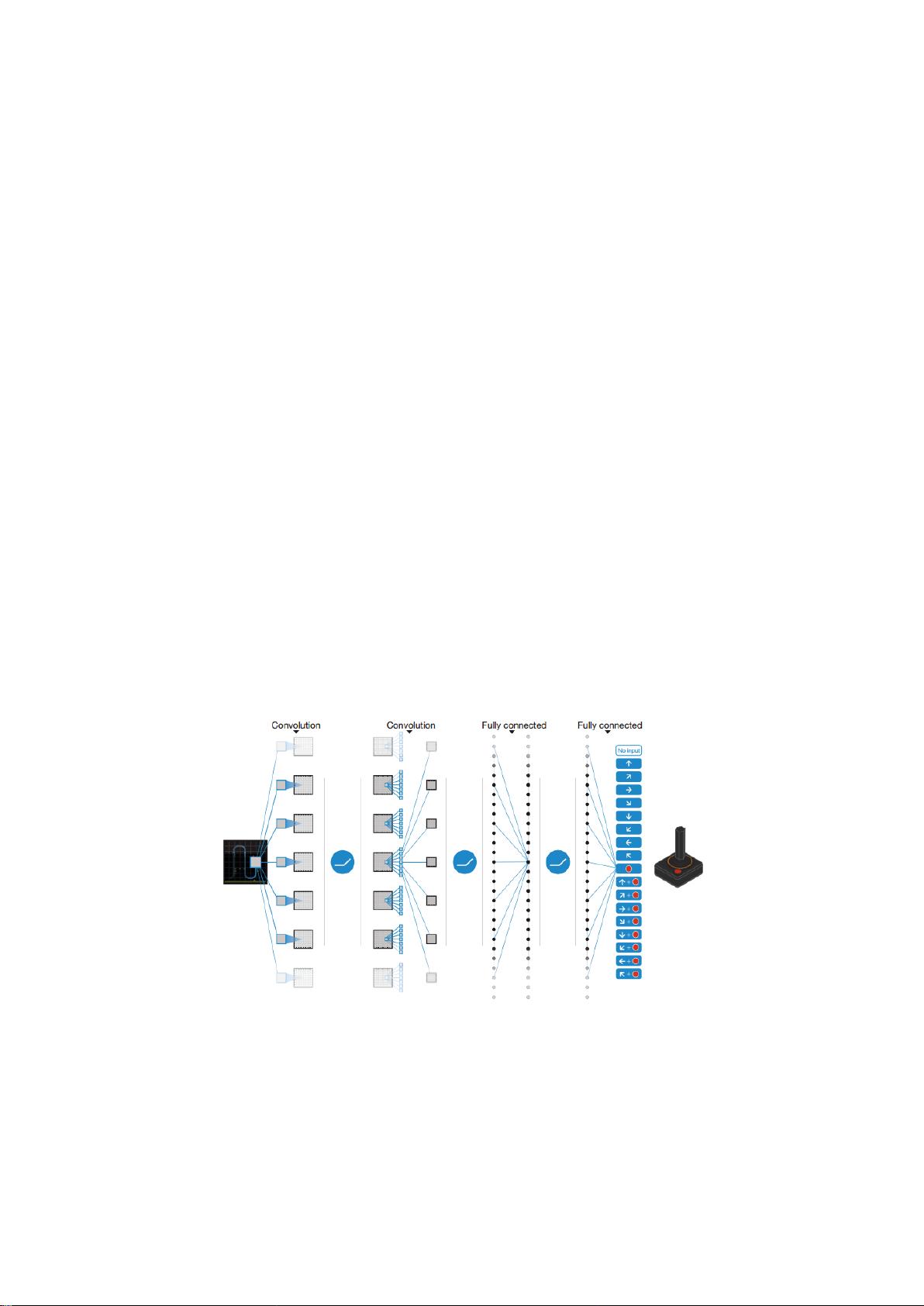
深度 Q 网络(DQN),可以让一类我们熟知的人工神经网络(例如深度神经网络)与强化学习
结合,在各自层里的节点逐步地建立更抽象的数据特征,让人工神经网络学习概念(例如直接
来自原始感观数据的对象类别)成为可能。我们使用了一种特别成功的结构,深度卷积网络,这
种网络使用分层的卷积核来模拟感受野效应——受到 Hubei 和 Wiesel 关于前视觉皮层前馈过
程研究工作的启发——从而利用图像中存在的局部空间相关性,建立对自然变换的鲁棒性,例
如视点或比例的变化。
我们考虑到智能体通过一系列的观察、动作和奖赏与环境进行交互。智能体的目标是选择
一种可以使未来累计奖赏最大的一种动作。更书面地说,我们使用了一个深度卷积神经网络来
近似一个最佳动作值函数:
Q
∗
(s, a) = max
π
E[r
t
+ γr
t+1
+ γ
2
r
t+2
+ ...|s
t
= s, a
t
= a, π] (1)
1
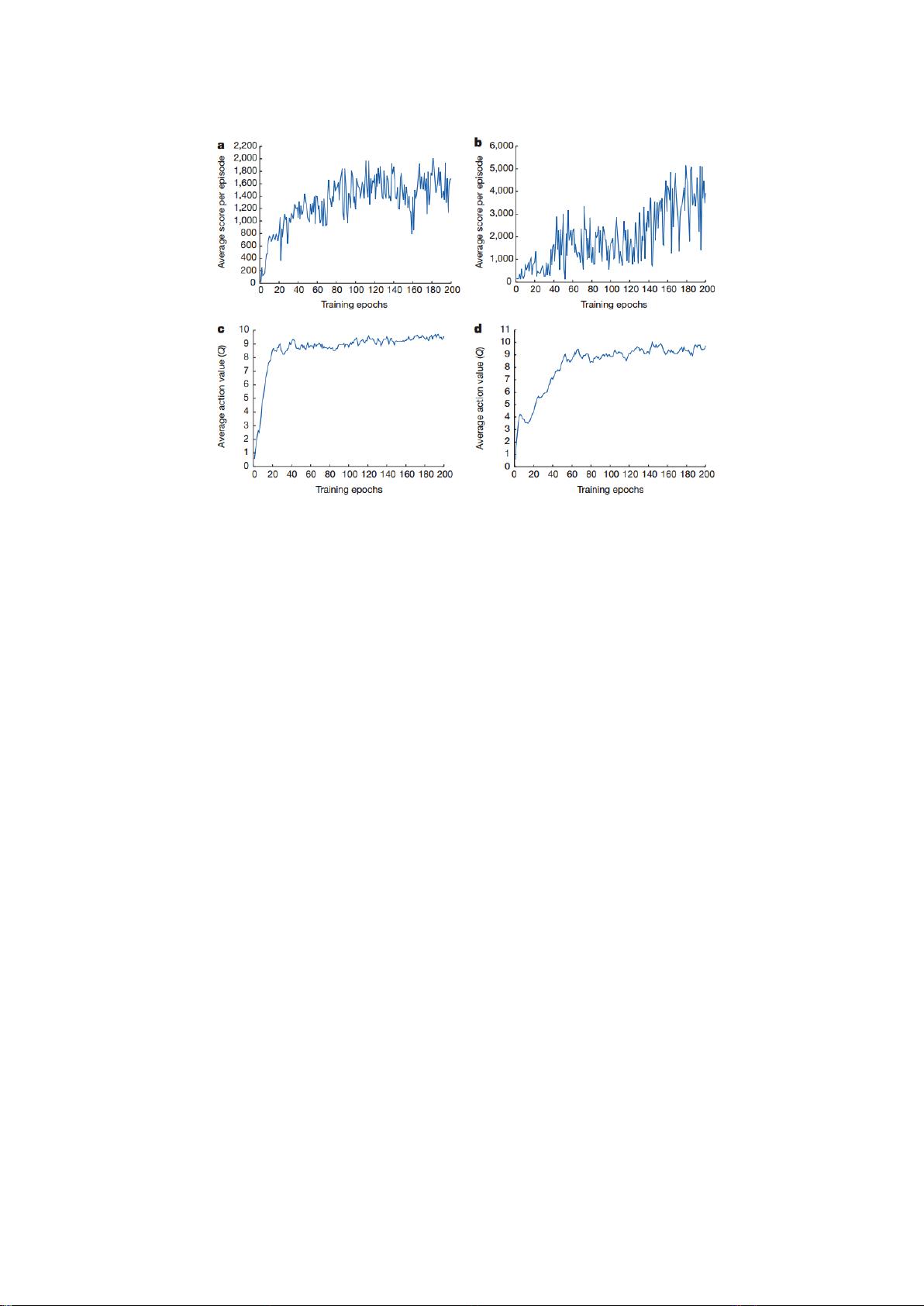
剩余17页未读,继续阅读






评论0
最新资源