# (白嫖)这是一个为麻瓜设计的本地OCR模块
只需要简单几步操作即可拥有两大通用识别模块,让你在工作中畅通无阻。
测试图片 test1.png

测试图片 test2.jpg
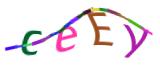
## SDK类参数
| 参数名 | 必选 | 类型 | 说明 |
| ---------- | ---- | --------- | -------------------------------------- |
| model_type | No | ModelType | 指定预置模型类型 |
| conf_path | No | str | 指定自定义模型yaml配置文件(绝对路径) |
以上参数两者选其一即可,默认 model_type 为 ModelType.OCR, 若指定 conf_path 参数则优先使用自定义模型。
## 核心API
1. ```SDK.predict(image_bytes: bytes)```
## 使用指北
**注意: 因模块过新,阿里/清华等第三方源可能尚未更新镜像,因此手动指定使用境外源,为了提高依赖的安装速度,可预先自行安装依赖:tensorflow/numpy/opencv-python/pillow/pyyaml**
1. ```pip install muggle-ocr```
2. 调用示例:
```python
import time
# 1. 导入包
import muggle_ocr
"""
使用预置模型,预置模型包含了[ModelType.OCR, ModelType.Captcha] 两种
其中 ModelType.OCR 用于识别普通印刷文本, ModelType.Captcha 用于识别4-6位简单英数验证码
"""
# 打开印刷文本图片
with open(r"test1.png", "rb") as f:
ocr_bytes = f.read()
# 打开验证码图片
with open(r"test2.jpg", "rb") as f:
captcha_bytes = f.read()
# 2. 初始化;model_type 可选: [ModelType.OCR, ModelType.Captcha]
sdk = muggle_ocr.SDK(model_type=muggle_ocr.ModelType.OCR)
# ModelType.Captcha 可识别光学印刷文本
for i in range(5):
st = time.time()
# 3. 调用预测函数
text = sdk.predict(image_bytes=ocr_bytes)
print(text, time.time() - st)
# ModelType.Captcha 可识别4-6位验证码
sdk = muggle_ocr.SDK(model_type=muggle_ocr.ModelType.Captcha)
for i in range(5):
st = time.time()
# 3. 调用预测函数
text = sdk.predict(image_bytes=captcha_bytes)
print(text, time.time() - st)
"""
使用自定义模型
支持基于 https://github.com/kerlomz/captcha_trainer 框架训练的模型
训练完成后,进入导出编译模型的[out]路径下, 把[graph]路径下的pb模型和[model]下的yaml配置文件放到同一路径下。
将 conf_path 参数指定为 yaml配置文件 的绝对或项目相对路径即可,其他步骤一致,如下示例:
"""
with open(r"test3.jpg", "rb") as f:
b = f.read()
sdk = muggle_ocr.SDK(conf_path="./ocr.yaml")
text = sdk.predict(image_bytes=b)
```
**输出结果:**
```shell script
MuggleOCR Session [ocr] Loaded.
曹文轩教授作序推荐 0.010004520416259766
曹文轩教授作序推荐 0.009941339492797852
曹文轩教授作序推荐 0.0109710693359375
曹文轩教授作序推荐 0.00901031494140625
曹文轩教授作序推荐 0.010967493057250977
MuggleOCR Session [captcha] Loaded.
ceey 0.010970592498779297
ceey 0.009973287582397461
ceey 0.010970592498779297
ceey 0.009973526000976562
ceey 0.009973287582397461
```
OCR和验证码识别的速度基本都在10ms左右,低配CPU可能需要15-20ms。本模块仅支持单行识别,如有多行识别需求请自行采用目标检测预裁图片。
对本项目感兴趣的可以加QQ群交流:857149419
muggle-ocr-1.0.3_muggle_ocr库下载_验证码识别_

版权申诉
 muggle-ocr-1.0.3.zip (16个子文件)
muggle-ocr-1.0.3.zip (16个子文件)  PKG-INFO 5KB
PKG-INFO 5KB muggle_ocr captcha.yaml 6KB sdk.py 88KB __init__.py 157B init_data.py 4KB ocr.yaml 8KB captcha.pb 2.51MB ocr.pb 4.55MB muggle_ocr.egg-info
muggle_ocr captcha.yaml 6KB sdk.py 88KB __init__.py 157B init_data.py 4KB ocr.yaml 8KB captcha.pb 2.51MB ocr.pb 4.55MB muggle_ocr.egg-info  dependency_links.txt 1B PKG-INFO 5KB requires.txt 51B SOURCES.txt 336B top_level.txt 11B setup.cfg 42B setup.py 1KB README.md 4KB
dependency_links.txt 1B PKG-INFO 5KB requires.txt 51B SOURCES.txt 336B top_level.txt 11B setup.cfg 42B setup.py 1KB README.md 4KB
弓弢
- 粉丝: 42
- 资源: 4022

下载权益

C知道特权

VIP文章

课程特权
开通VIP









最新资源
- 2022年各城市PM2.5, PM10, SO2, NO2等环境空气质量数据
- Golang:通过Gin框架+Redis+责任链,实现一个简单的钉钉机器人,进行消息处理 ps:多应用版
- 2021年各城市PM2.5, PM10, SO2, NO2等环境空气质量数据
- CORRUPT.navicat150-premium-cs-x64.exe
- centos7 ssh 升级至 9.6p1
- DriverMax Pro .exe
- PHP端通过modbus协议跟第三方设备进行数据通信
- navicat安装包亲测可用
- 算法部署-使用OpenVINO部署MobileStyleGAN轻量化高保真图像合成算法-项目源码-优质项目实战.zip
- 基于java实现远程采集华为逆变器使用modbus tcp协议进行通讯的设备数据
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



- 1
- 2
前往页