


做技术人的指路明灯,做职场生涯的精神导师
课程目标
1. 消息的存储原理
2. Partition 的副本机制原理
3. 副本数据的同步原理
消息的文件存储机制
前面我们知道了一个 topic 的多个 partition 在物理磁盘上
的保存路径,那么我们再来分析日志的存储方式。通过如
下命令找到对应 partition 下的日志内容
[root@localhost ~]# ls /tmp/kafka-logs/firstTopic-1/
00000000000000000000.index

做技术人的指路明灯,做职场生涯的精神导师
00000000000000000000.log
00000000000000000000.timeindex leader-epoch-
checkpoint
kafka 是通过分段的方式将 Log 分为多个 LogSegment,
LogSegment 是一个逻辑上的概念,一个 LogSegment 对
应磁盘上的一个日志文件和一个索引文件,其中日志文件
是用来记录消息的。索引文件是用来保存消息的索引。那
么这个 LogSegment 是什么呢?
LogSegment
假设 kafka 以 partition 为最小存储单位,那么我们可以想
象当 kafka producer 不断发送消息,必然会引起 partition
文件的无线扩张,这样对于消息文件的维护以及被消费的
消息的清理带来非常大的挑战,所以 kafka 以 segment 为
单位又把 partition 进行细分。每个 partition 相当于一个巨
型文件被平均分配到多个大小相等的segment数据文件中
(每个 segment 文件中的消息不一定相等),这种特性方
便已经被消费的消息的清理,提高磁盘的利用率。
➢ log.segment.bytes=107370 (设置分段大小),默认是
1gb,我们把这个值调小以后,可以看到日志分段的效果
⚫ 抽取其中 3 个分段来进行分析

做技术人的指路明灯,做职场生涯的精神导师
segment file 由 2 大部分组成,分别为 index file 和 data
file,此 2 个文件一一对应,成对出现,后缀".index"和“.log”
分别表示为 segment 索引文件、数据文件.
segment 文件命名规则:partion 全局的第一个 segment
从 0 开始,后续每个 segment 文件名为上一个 segment
文件最后一条消息的 offset 值进行递增。数值最大为 64 位
long 大小,20 位数字字符长度,没有数字用 0 填充
查看 segment 文件命名规则
➢ 通过下面这条命令可以看到 kafka 消息日志的内容
sh kafka-run-class.sh kafka.tools.DumpLogSegments --
files /tmp/kafka-logs/test-
0/00000000000000000000.log --print-data-log
输出结果为:
offset: 5376 position: 102124 CreateTime: 1531477349287
isvalid: true keysize: -1 valuesize: 12 magic: 2
compresscodec: NONE producerId: -1 producerEpoch: -

做技术人的指路明灯,做职场生涯的精神导师
1 sequence: -1 isTransactional: false headerKeys: []
payload: message_5376
第一个 log 文件的最后一个 offset 为:5376,所以下一个
segment 的文件命名为: 00000000000000005376.log。对
应的 index 为 00000000000000005376.index
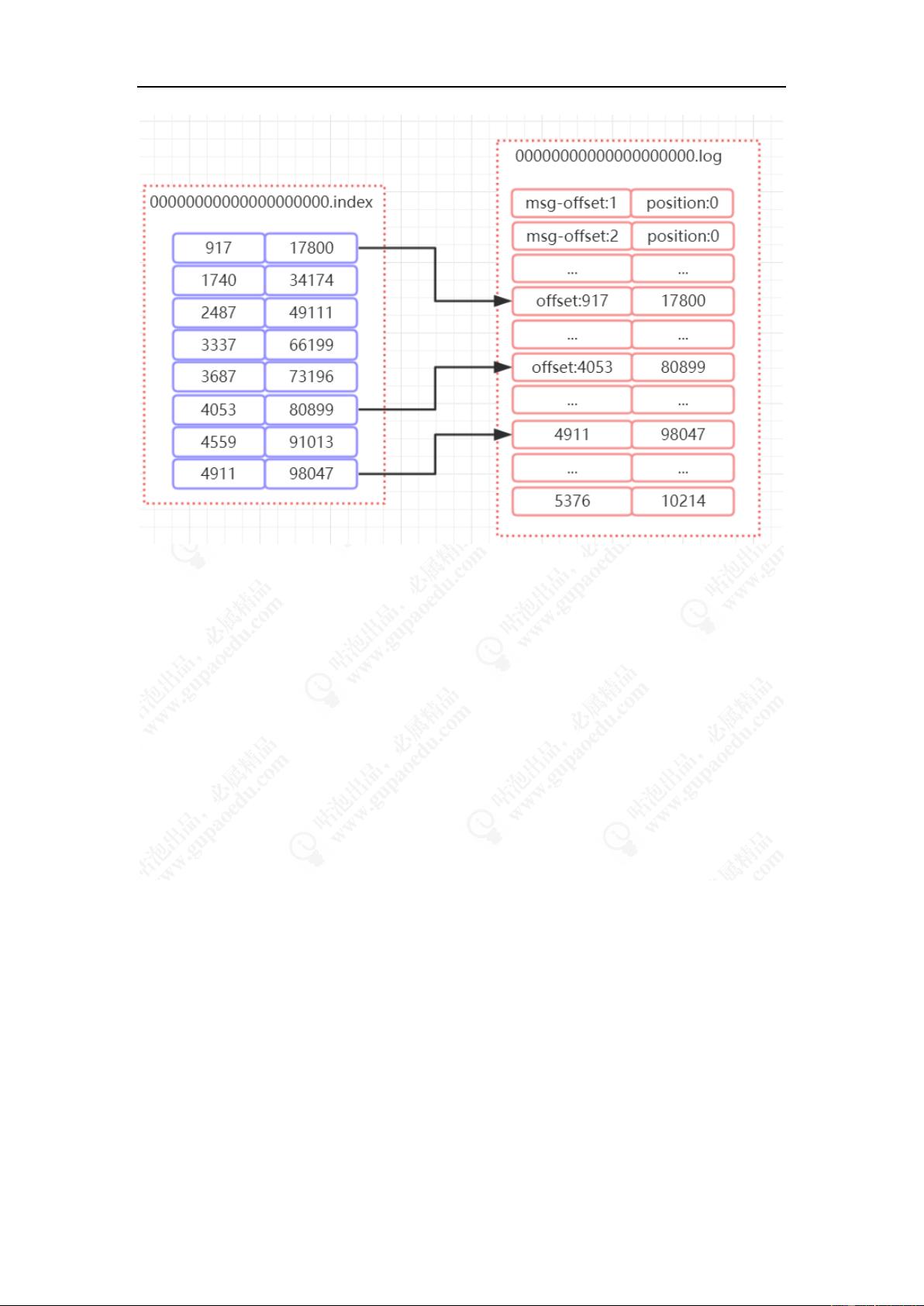
segment 中 index 和 log 的对应关系
从所有分段中,找一个分段进行分析
为了提高查找消息的性能,为每一个日志文件添加 2 个索
引索引文件:OffsetIndex 和 TimeIndex,分别对应*.index
以及*.timeindex, TimeIndex 索引文件格式:它是映射时间
戳和相对 offset
查 看 索 引 内 容 : sh kafka-run-class.sh
kafka.tools.DumpLogSegments --files /tmp/kafka-
logs/test-0/00000000000000000000.index --print-data-
log
做技术人的指路明灯,做职场生涯的精神导师
如图所示,index 中存储了索引以及物理偏移量。 log 存
储了消息的内容。索引文件的元数据执行对应数据文件中
message 的物理偏移地址。举个简单的案例来说,以
[4053,80899]为例,在 log 文件中,对应的是第 4053 条记
录, 物理 偏移量 ( position)为 80899. position 是
ByteBuffer 的指针位置
在 partition 中如何通过 offset 查找 message
查找的算法是
1. 根据 offset 的值,查找 segment 段中的 index 索引文
件。由于索引文件命名是以上一个文件的最后一个
offset 进行命名的,所以,使用二分查找算法能够根据
offset 快速定位到指定的索引文件。













