


Mapreduce實現KNN算法和K-means算法
⼀.使⽤平台及算法介紹
①hadoop
Hadoop是⼀個這合⼤數據的分布式存儲和計算平臺。框架主要由HDFS和MapReduce組
成︔
HDFS:Hadoop Distributed File System分布式⽂件系統,⽤來管理⽂件的,在hdfs上存儲的數
據是分散很多服務器之上的,但是⽤⼾感覺不到,⽂件真的分布在很多臺機器上,就像壹臺機器
上似的。
MapReduce:分布式並⾏計算框架.實現的是分布式計算,⼤數據分布在很多臺服務器上,需
要它去並⾏地去執⾏。
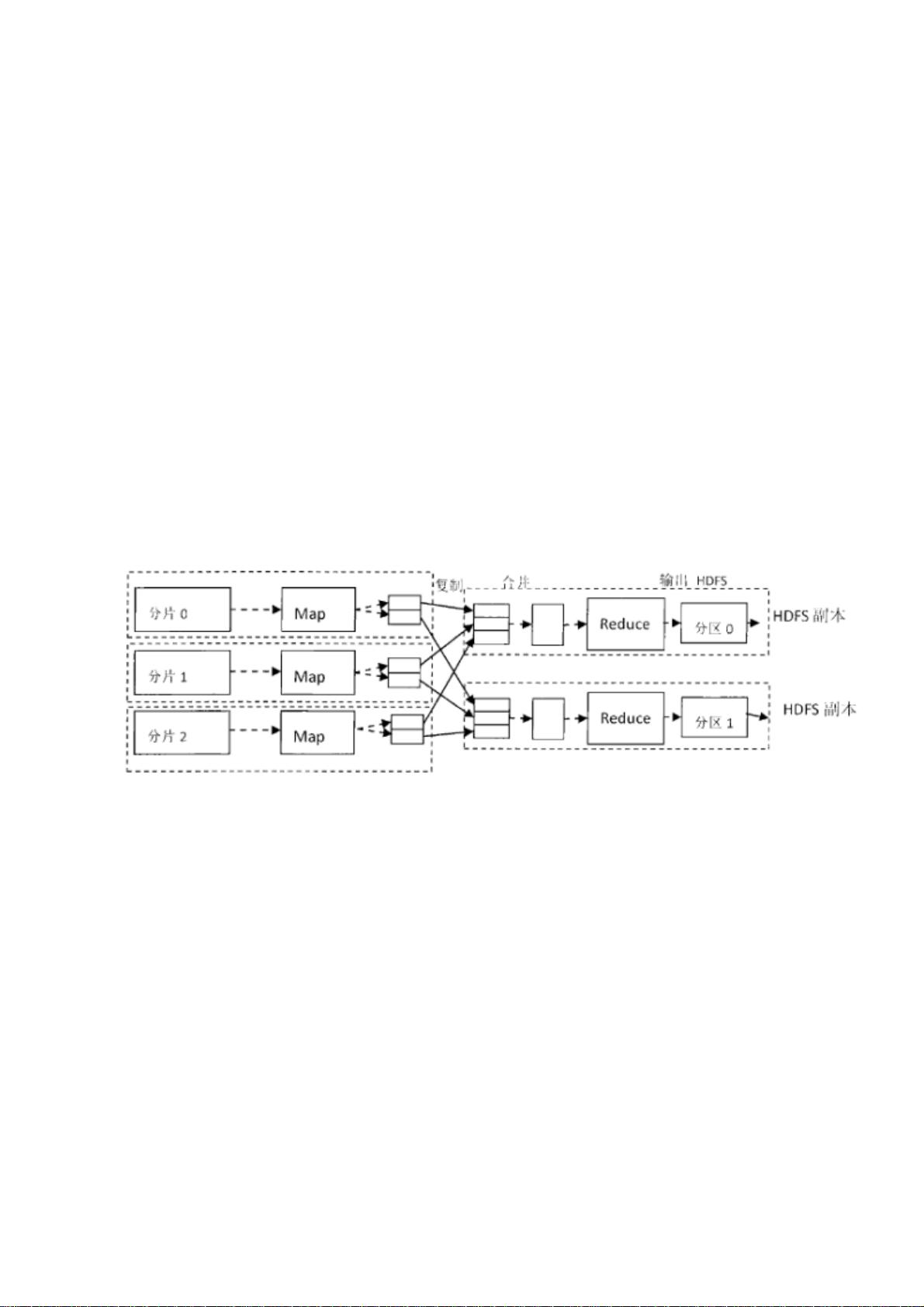
運⾏原理:
!
MapReduce程序的執⾏過程分为兩個階段:Mapper階段和Reducer階段。
其中Mapper階段可以分為6個步驟:
第壹階段:先將 HDFS中的輸入⽂件 file按照壹定的標準進⾏切⽚,默認切⽚的類為
FileInputFormat,通過切⽚輸入⽂件將會變成split1、split2、split3……︔隨後對輸入切⽚split
按照⼀定的規則解析成鍵值對<k1,v1>,默認處理的類為TextInputFormat。其中k1就是我們常說
的起始偏移量,v1就是⾏⽂本的內容。
第⼆階段:調⽤⾃⼰編寫的map邏輯,將輸入的鍵值對<k1,v1>變成<k2,v2>。在這裏要注
意:每⼀個鍵值對<k1,v1>都會調⽤⼀次map函數。
第三階段:按照⼀定的規則對輸出的鍵值對<k2,v2>進⾏分區:分區的規則是針對k2進⾏的,
比如說k2如果是省份的話,那麽就可以按照不同的省份進⾏分區,同⼀個省份的k2劃分到⼀
個區。注意:默認分區的類是HashPartitioner類,這個類默認只分為⼀個區,因此Reducer任
務的數量默認也是1.
第四階段:對每個分區中的鍵值對進⾏排序。註意:所謂排序是針對k2進⾏的,v2是不參與
排序的,如果要讓v2也參與排序,需要⾃定義排序的類,具體過程可以參看博主⽂章。





















