Aldebaro Klautau - 11/22/05. Page 1.
The MFCC
1- How are MFCCs used in speech recognition ?
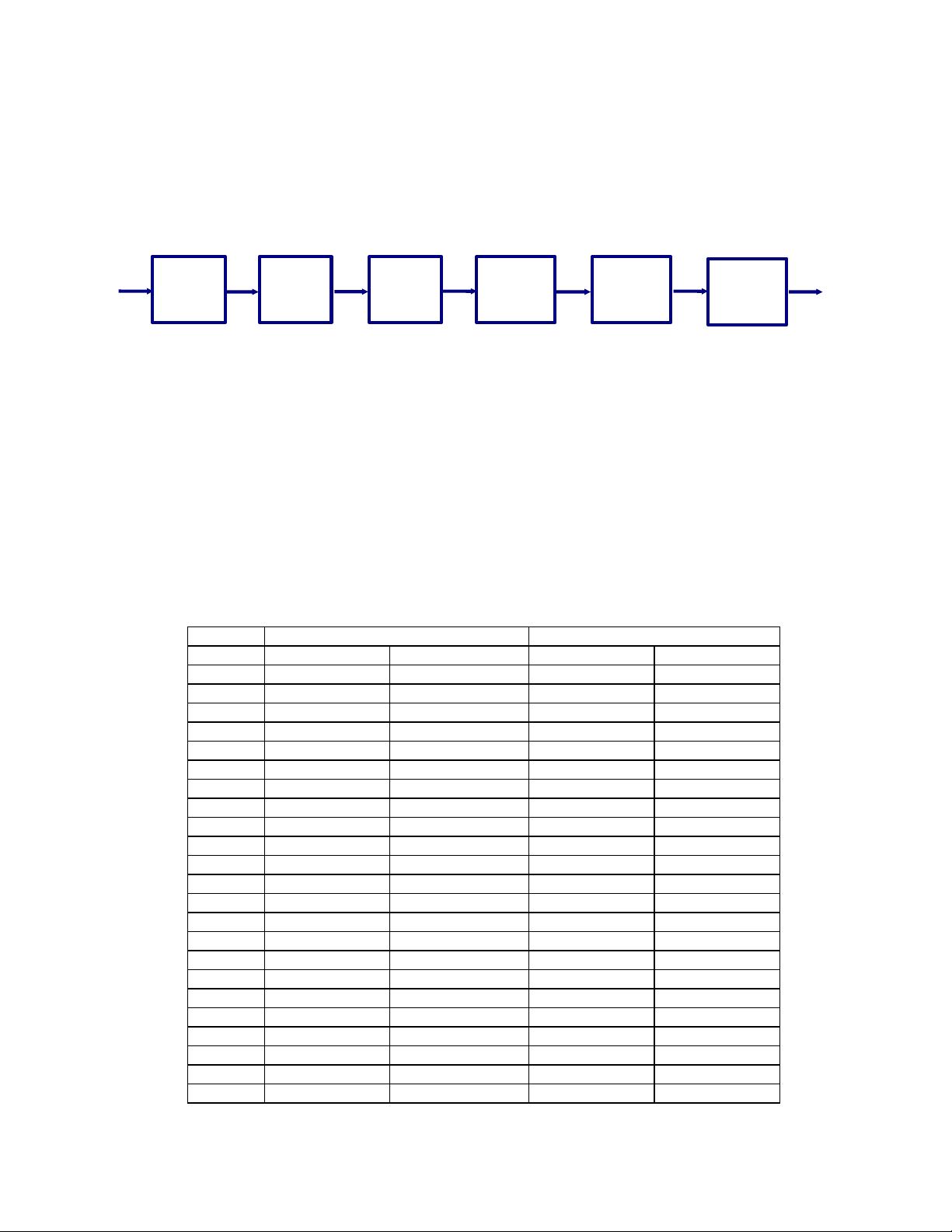
Generally speaking, a conventional automatic speech recognition (ASR) system can be
organized in two blocks: the feature extraction and the modeling stage. In practice, the
modeling stage is subdivided in acoustical and language modeling, both based on HMMs as
described in Figure 1.
Figure 1- Simple representation of a conventional ASR.
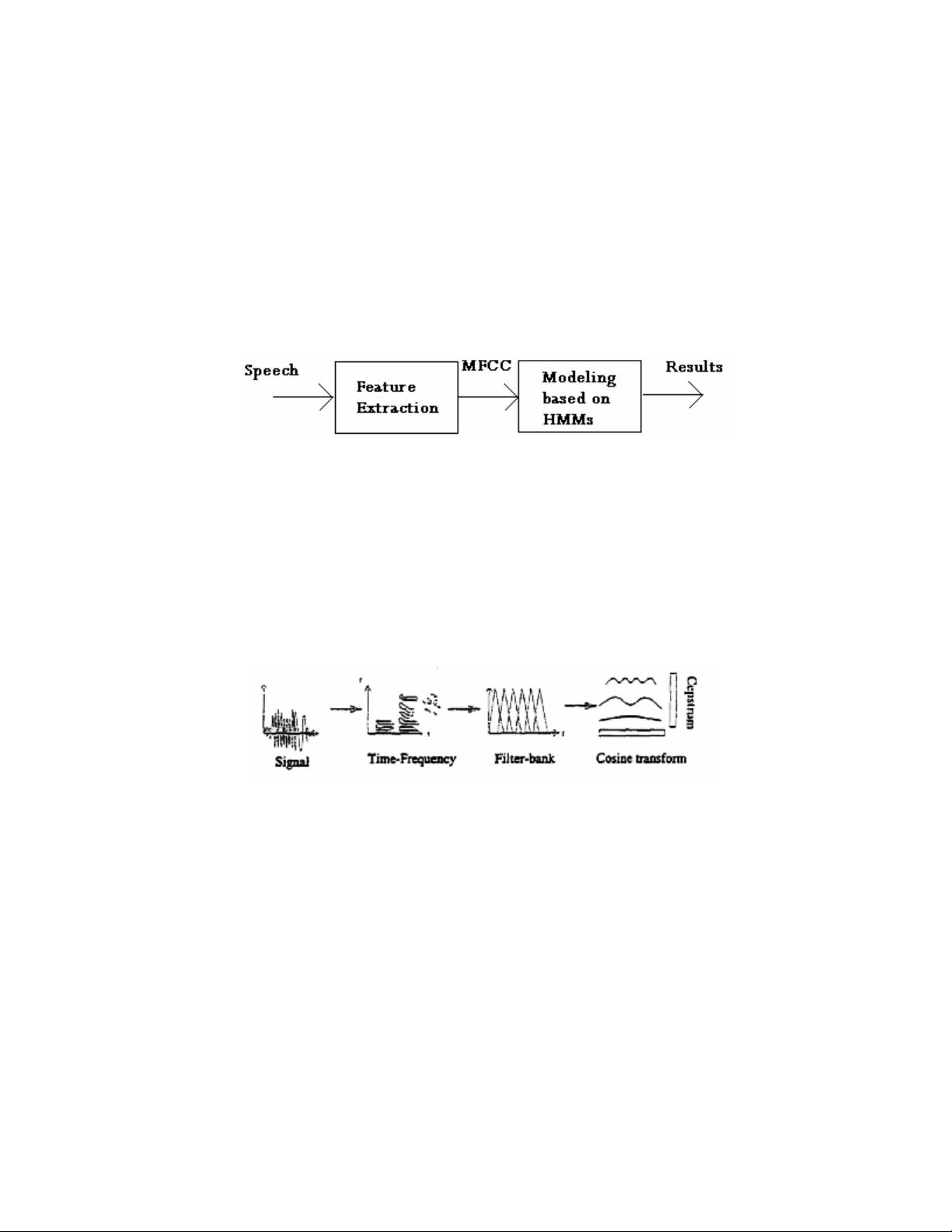
The feature extraction is usually a non-invertible (lossy) transformation, as the MFCC
described pictorially in Figure 2. Making an analogy with filter banks, such transformation does
not lead to perfect reconstruction, i.e., given only the features it is not possible to reconstruct
the original speech used to generate those features.
Computational complexity and robustness are two primary reasons to allow loosing
information. Increasing the accuracy of the parametric representation by increasing the
number of parameters leads to an increase of complexity and eventually does not lead to a
better result due to robustness issues. The greater the number of parameters in a model, the
greater should be the training sequence.
Figure 2- Pictorial representation of mel-frequency cepstrum (MFCC) calculation.
Speech is usually segmented in frames of 20 to 30 ms, and the window analysis is
shifted by 10 ms. Each frame is converted to 12 MFCCs plus a normalized energy parameter.
The first and second derivatives (∆’s and ∆∆’s) of MFCCs and energy are estimated, resulting in
39 numbers representing each frame. Assuming a sample rate of 8 kHz, for each 10 ms the
feature extraction module delivers 39 numbers to the modeling stage. This operation with
overlap among frames is equivalent to taking 80 speech samples without overlap and
representing them by 39 numbers. In fact, assuming each speech sample is represented by
one byte and each feature is represented by four bytes (float number), one can see that the
parametric representation increases the number of bytes to represent 80 bytes of speech (to
136 bytes). If a sample rate of 16 kHz is assumed, the 39 parameters would represent 160
samples. For higher sample rates, it is intuitive that 39 parameters do not allow to reconstruct
the speech samples back. Anyway, one should notice that the goal here is not speech
compression but using features suitable for speech recognition.