



1
《编译原理》课程实验
一.实验目的:
设计、编写和调试一个具体的词法分析程序,加深对词法分析理论和自动词
法分析工具的理解、实践和掌握。
二. 实验要求:
① 学习和理解正则表达式理论,写出 C—语言的记号的完整的正则表达
式;(适当使用正则定义)
② 学习和理解有限机理论,根据前面的正则表达式,用基于经验的方法
画出 C—语言的记的 DFA 图;
③ 用基于 DFA 图的算法编写 C—语言的词法分析程序;
④ 学习词法分析程序的自动生成工具,使用 LEX 工具实现 C—语言的词
法分析程序.
三. 实验内容
正则表达式:id = letter (letter|digit)*
num = digit digit*
letter = [a-z] | [A-Z]
digit = [0-9]
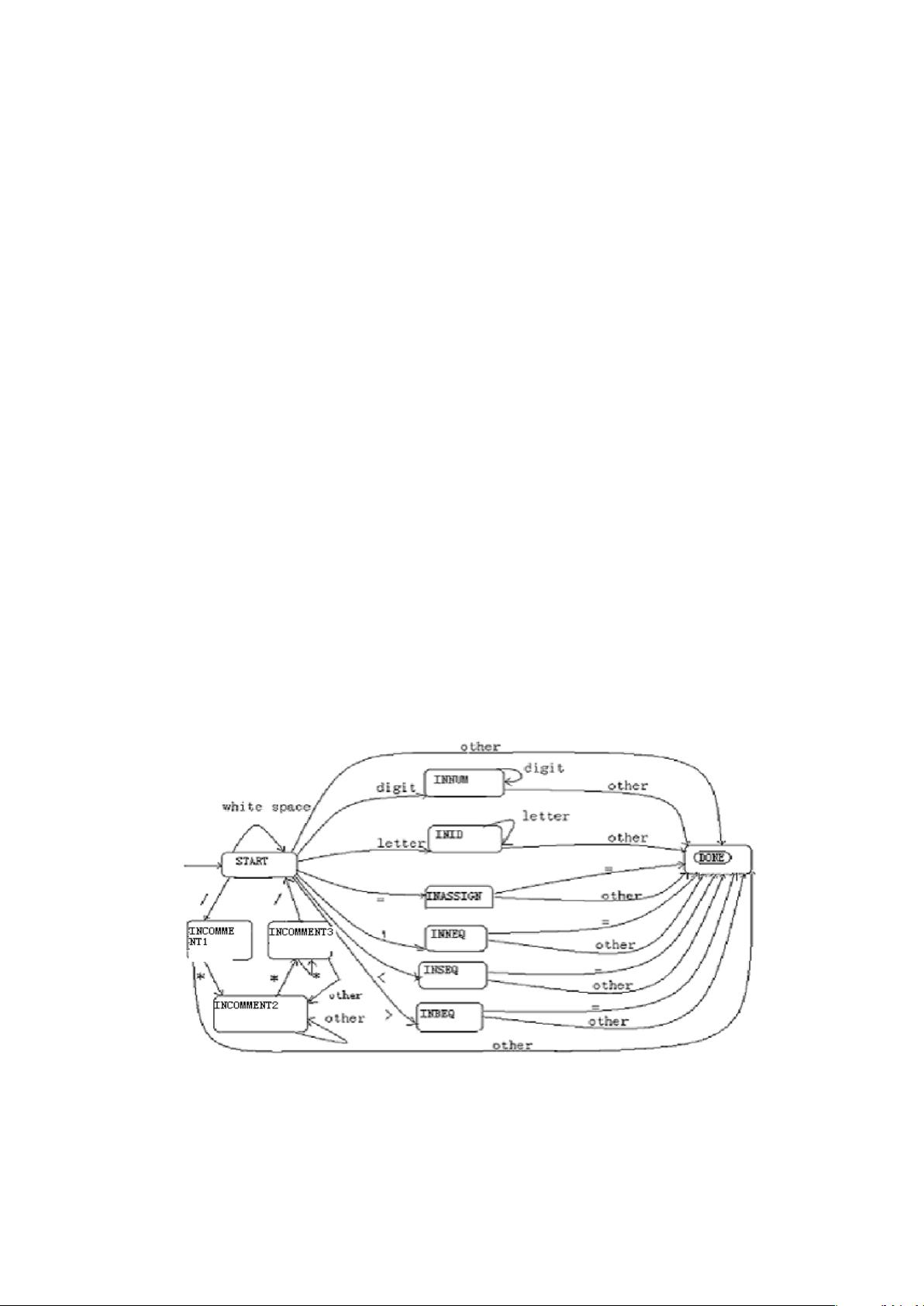
画 DFA:

2
四. 手工编程源代码如下:
/****************************************************/
/* File: scan.c */
/* The scanner implementation for the TINY compiler */
/* Compiler Construction: Principles and Practice */
/* Kenneth C. Louden */
/****************************************************/
#include "globals.h"
#include "util.h"
#include "scan.h"
/* states in scanner DFA */
typedef enum
{ START,NUMBER,INID,EQUAL,NEQUAL,LTOREQ,LGORLT,
INCOMMENT2,INCOMMENT3,INCOMMENT4,DONE }
StateType;
/*lexeme of identifier or reserved word */
char tokenString[MAXTOKENLEN+1];
/*BUFLEN = length of the input buffer for
source code lines */
#define BUFLEN 256
static char lineBuf[BUFLEN]; /* holds the current line */
static int linepos = 0; /* current position in LineBuf */
static int bufsize = 0; /* current size of buffer string */
static int EOF_flag = FALSE; /* corrects ungetNextChar behavior on EOF */
/* getNextChar fetches the next non-blank character
from lineBuf, reading in a new line if lineBuf is exhausted */
static char getNextChar(void)
{ if (!(linepos < bufsize))
{ lineno++;
if (fgets(lineBuf,BUFLEN-1,source))
{ if (EchoSource) fprintf(listing,"%4d: %s",lineno,lineBuf);
bufsize = strlen(lineBuf);
linepos = 0;
return lineBuf[linepos++];
}
else

3
{ EOF_flag = TRUE;
return EOF;
}
}
else return lineBuf[linepos++];
}
/* ungetNextChar backtracks one character
in lineBuf */
static void ungetNextChar(void)
{ if (!EOF_flag) linepos-- ;}
/* lookup table of reserved words */
static struct
{ char* str;
TokenType tok;
} reservedWords[MAXRESERVED]
= {{"if",IF},{"else",ELSE},{"int",INT},
{"return",RETURN},{"void",VOID},{"while",WHILE}
};
/* lookup an identifier to see if it is a reserved word */
/* uses linear search */
static TokenType reservedLookup (char * s)
{ int i;
for (i=0;i<MAXRESERVED;i++)
if (!strcmp(s,reservedWords[i].str))
return reservedWords[i].tok;
return ID;
}
/****************************************/
/* the primary function of the scanner */
/****************************************/
/* function getToken returns the
* next token in source file
*/
TokenType getToken(void)
{ /* index for storing into tokenString */
int tokenStringIndex = 0;
/* holds current token to be returned */
TokenType currentToken;
/* current state - always begins at START */
StateType state = START;

4
/* flag to indicate save to tokenString */
int save;
while (state != DONE)
{ int c = getNextChar();
save = TRUE;
switch (state)
{ case START:
if (isdigit(c))
state = NUMBER;
else if (isalpha(c))
state = INID;
else if (c == '<')
state = LTOREQ;
else if (c=='>')
state= LGORLT;
else if (c=='=')
state=EQUAL;
else if (c=='!')
state=NEQUAL;
else if ((c == ' ') || (c == '\t') || (c == '\n'))
save = FALSE;
else if (c == '/')
state =INCOMMENT1;
else
{ state = DONE;
switch (c)
{ case EOF:
save = FALSE;
currentToken = ENDFILE;
break;
case '=':
currentToken = EQ;
break;
case '<':
currentToken = LT;
break;
case '+':
currentToken = PLUS;
break;
case '-':
currentToken = MINUS;
break;
case '*':
currentToken = TIMES;

5
break;
case '/':
currentToken = OVER;
break;
case '(':
currentToken = LPAREN;
break;
case ')':
currentToken = RPAREN;
break;
case ';':
currentToken = SEMI;
break;
case '>':
currentToken = LA;
case '[':
currentToken = LRECT;
case ']':
currentToken = RRECT;
case '{':
currentToken = LBRAN;
case '}':
currentToken = RBRAN;
case ',':
currentToken = COMMA;
default:
currentToken = ERROR;
break;
}
}
break;
case INCOMMENT1:
save = FALSE;
if (c == '*')
{ state = DONE;
state=INCOMMENT2;}
else{ ungetNextChar();
state = DONE;
currentToken =OVER; }
break;
case INCOMMENT2:
save=FALSE;
if(c=='*')
state=INCOMMENT3;













