




解析过程详解
1 xmlDocPtr xmlParseFile(const char *filename)
1.1 函数主要功能说明
filename: 需要解析的 xml 文档的文件名。
return 返回所建立文档树的文档节点(即树的入口)的指针。
函数的功能是根据提供的 xml 文档建立一棵对应的文档树。
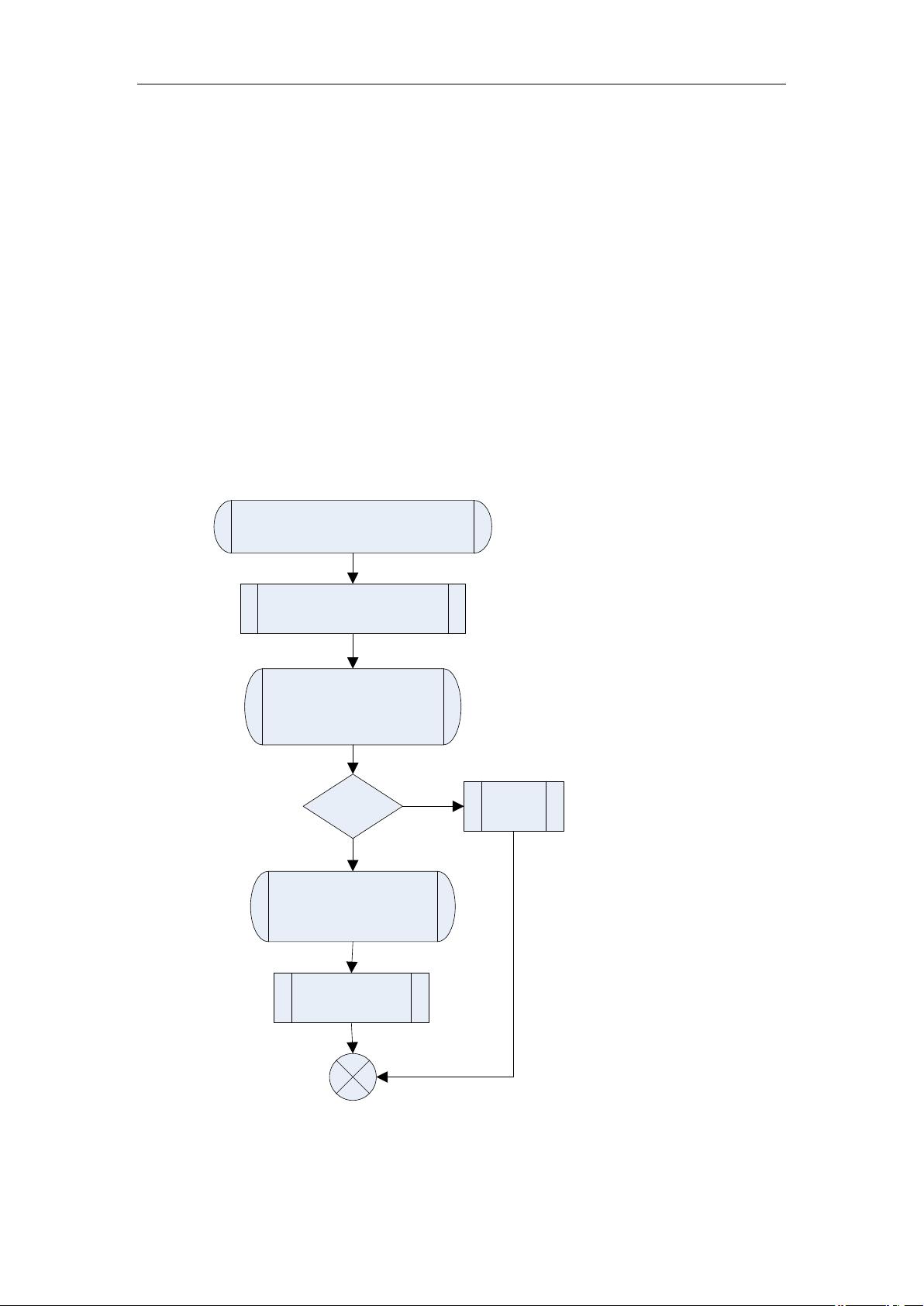
1.2 函数流程图
xmlParseFile(char *filename,char )
Create a xmlParserCtxtPtr
ctxt
Init ctxt
xmlCreateFileParserCtxt(
filename,options)
Ctxt=
NULL
N
Y
return
NULL
Do the parse
xmlParseDocument(ctxt
,options)
Return the result
xmlDocPtr

1.3 函数的详细描述
1.3.1 主要结构体和自定义变量的简单描述
typedef unsigned char xmlChar
_xmlParserCtxt 解析文本结构
struct _xmlParserCtxt
{
xmlDocPtr myDoc; /* the document being built */
int wellFormed; /* is the document well formed 是格式良好的*/
int replaceEntities; /* shall we replace entities ?是否要代替实体*/
const xmlChar *version; /* the XML version string */
const xmlChar *encoding; /* the declared encoding,声明的编码方式*/
/* Input stream stack 输入流栈的一些参数 */
xmlParserInputPtr input; /* Current input stream */
/* Node analysis stack only used for DOM building 用于 DOM 树的节点分析栈*/
xmlNodePtr node; /*当前解析的节点*/
int nodeNr; /* Depth of the parsing stack 节点栈的深度*/
int nodeMax; /* Max depth of the parsing stack */
xmlNodePtr* nodeTab; /*存放节点的栈*/
char * directory; /* the data directory 数据的目录*/
/* Node name stack 节点名字栈 */
const xmlChar *name; /* Current parsed Node 当前解析节点名 */
int nameNr; /* Depth of the parsing stack */
int nameMax; /* Max depth of the parsing stack */
const xmlChar * *nameTab; /* array of nodes */
const xmlChar * *atts; /* array for the attributes 存放属性的数组*/
int maxatts; /* the size of the array */
};
_xmlDoc 文档节点结构
struct _xmlDoc
{
void *_private; /* application data */
xmlElementType type; /* XML_DOCUMENT_NODE, must be second */
char* name; /* name/filename/URI of the document */
struct _xmlNode *children; /* the document tree */
struct _xmlNode *last; /* last child link */
struct _xmlNode *next; /* next sibling link */
struct _xmlNode *prev; /* previous sibling link */
struct _xmlDoc *doc; /* autoreference to itself */
struct _xmlNs *oldNs; /* Global namespace, the old way */

void *ids; /* Hash table for ID attributes if any */
void *refs; /* Hash table for IDREFs attributes if any */
struct _xmlDict *dict; /* dict used to allocate names or NULL */
int properties; /* set of xmlDocProperties for this document
set at the end of parsing */
};
typedef enum
{
XML_ELEMENT_NODE= 1,
XML_ATTRIBUTE_NODE= 2,
XML_TEXT_NODE= 3,
XML_CDATA_SECTION_NODE= 4,
XML_ENTITY_REF_NODE= 5,
XML_ENTITY_NODE= 6,
XML_PI_NODE= 7,
XML_COMMENT_NODE= 8,
XML_DOCUMENT_NODE= 9,
XML_DOCUMENT_TYPE_NODE= 10,
XML_DOCUMENT_FRAG_NODE= 11,
XML_NOTATION_NODE= 12,
XML_HTML_DOCUMENT_NODE= 13,
XML_DTD_NODE= 14,
XML_ELEMENT_DECL= 15,
XML_ATTRIBUTE_DECL= 16,
XML_ENTITY_DECL= 17,
XML_NAMESPACE_DECL= 18,
XML_XINCLUDE_START= 19,
XML_XINCLUDE_END= 20
} xmlElementType;
1.3.2 主要函数的简单描述
xmlParserCtxtPtr xmlCreateFileParserCtxt(const char *filename)
filename 需要解析的 xml 文档的文件名
return 指向一个解析文本结构的指针
函数功能是根据文件建立一个相应的解析文本,主要是给一个_xmlParserCtxt 结构分配
空间,给_xmlParserCtxt 输入缓冲区分配空间并初始化,详见 3。
int xmlParseDocument(xmlParserCtxtPtr ctxt)
ctxt 当前的解析文本的指针
return 成功返回 0,错误返回 1
函数的功能是针对 xml 文档解析建树。详见 2。
void xmlFreeDoc(xmlDocPtr cur)

cur 当前的文档节点指针
函数的功能是实现释放这个文档结构,包括它所包含的子树。
void xmlFreeParserCtxt(xmlParserCtxtPtr ctxt)
ctxt 当前的解析文本的指针
函数的功能是释放这个 ctxt 所占用的内存,但是 ctxt->mydoc 部分所占用的内存不释放。
也就是保留了所构建的 xml 文档树。
2 int xmlParseDocument(xmlParserCtxtPtr ctxt)
2.1 函数的主要功能说明
ctxt 当前的解析文本指针
return 成功返回 0,错误返回-1
函数的功能是建立解析 xml 文档建立相应的文档树。
2.2 函数流程图
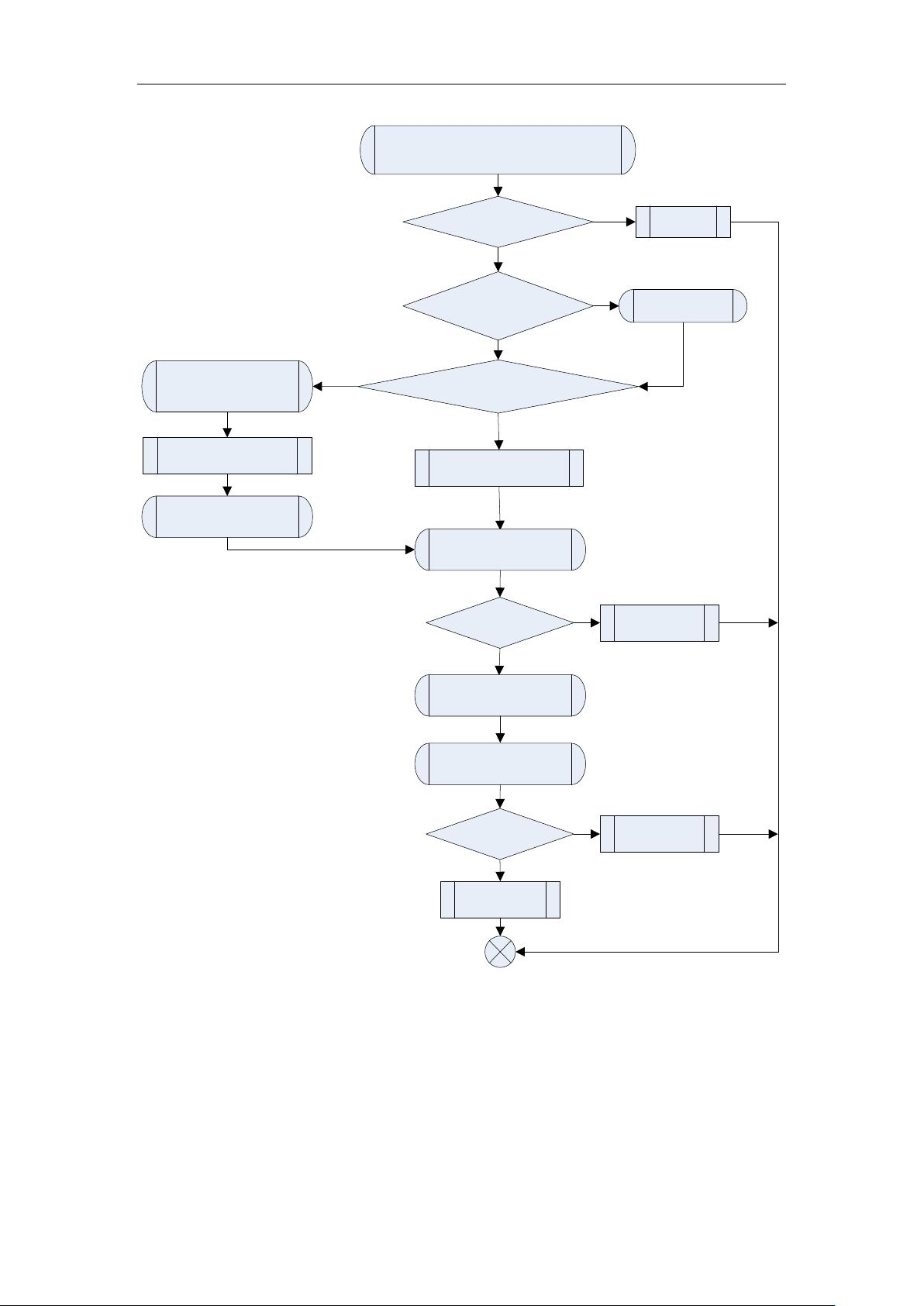
xmlParseDocument(xmlParserCtxtPtr ctxt)
ctxt == NULL ||
ctxt->input == NULL
Y
Return -1
(NXT(0)==0xEF)&&
(NXT(1)==0xBB)&&
(NXT(2)==0xBF)
Y
SKIP(ctxt,3)
N
CMP5(CUR_PTR, '<', '?', 'x', 'm', 'l')
N
parse an XML
declaration header
xmlParseXMLDecl(ctxt)
ctxt->standalone =
ctxt->input->standalone
SKIP_BLANKS
ctxt->version =”1.0”
Parse the comment
xmlParseMisc(ctxt)
Y
CUR!='<'
Y
N
Return -1
Parse the element
xmlParseElement(ctxt)
Parse the comment
xmlParseMisc(ctxt)
CUR!='0'
Y
N
Return -1
Return 0
N
2.3 函数的详细描述
2.3.1 主要结构体和自定义变量的简单描述
CUR













