



Oracle Real Application Clusters and Industry Trends
in Cluster Parallelism and Availability
James Hamilton, JamesRH@microsoft.com
Architect, Microsoft SQL Server
December 2004

The information contained in this document represents the current view of Microsoft
Corporation on the issues discussed as of the date of publication. Because Microsoft
must respond to changing market conditions, it should not be interpreted to be a
commitment on the part of Microsoft, and Microsoft cannot guarantee the accuracy of
any information presented after the date of publication.
This White Paper is for informational purposes only. MICROSOFT MAKES NO
WARRANTIES, EXPRESS, IMPLIED OR STATUTORY, AS TO THE
INFORMATION IN THIS DOCUMENT.
Complying with all applicable copyright laws is the responsibility of the user. Without
limiting the rights under copyright, no part of this document may be reproduced, stored in
or introduced into a retrieval system, or transmitted in any form or by any means
(electronic, mechanical, photocopying, recording, or otherwise), or for any purpose,
without the express written permission of Microsoft Corporation.
Microsoft may have patents, patent applications, trademarks, copyrights, or other
intellectual property rights covering subject matter in this document. Except as
expressly provided in any written license agreement from Microsoft, the furnishing of
this document does not give you any license to these patents, trademarks,
copyrights, or other intellectual property.
Unless otherwise noted, the example companies, organizations, products, domain names,
e-mail addresses, logos, people, places, and events depicted herein are fictitious, and no
association with any real company, organization, product, domain name, e-mail address,
logo, person, place, or event is intended or should be inferred.
© 2004 Microsoft Corporation. All rights reserved.
Active Directory, Microsoft, Visual Basic, Visual C++, Visual C%, Visual Studio,
Windows and Windows NT are either registered trademarks or trademarks of Microsoft
Corporation in the United States and/or other countries.
The names of actual companies and products mentioned herein may be the trademarks of their
respective owners.

1. Introduction
The Oracle Real Application Cluster (RAC) feature is frequently offered as a potential solution to many of
the problems faced by those deploying mission critical, data-centric applications. As is the case with most
important discussions, this one is being driven by many factors, some technical and some not, but all
relevant to those making a database (DB) technology decision. This paper explores some of the issues
driving the discussions surrounding RAC, investigates alternative technologies, and discusses some related
trends within the database management system (DBMS) development community.
Before continuing, let's review the author’s background and biases since they have some bearing on the
discussion that follows. James Hamilton is an architect on the Microsoft SQL Server development team,
where he has led many teams within the server including the SQL Language Compiler, Query Optimizer,
Query Execution Engine, DDL, metadata, and Catalog management groups, Security, XML, Client and
networking protocol teams, the Full-Text Search development group, and the Common Language Runtime
(CLR) integration effort. Prior to joining SQL Server, James spent 11 years at IBM where he was Lead
Architect on DB2 UDB, helping to ship many releases. Having helped customers successfully deploy
DB2 Parallel Edition (now a feature of DB2 Enterprise Edition), some will correctly point out that the
author has some biases towards shared nothing DB parallelism over shared disk-based solutions, which is
the core technology on which RAC is based. Certainly some of that concern is well founded, but
fortunately, this topic is much more complex than one that can be resolved through simple architectural
biases and preferences. All potential parallel clustering technologies have both advantages and
disadvantages, and each has successful deployment examples that can be referenced. This paper will focus
on what problems are being addressed by RAC, the alternatives available from Oracle and its competitors,
and compare and contrast the different approaches.
The RAC solution, some aspects of its implementation, its brand name, and how it is sold have evolved in
the decade since the technology was originally conceived as Oracle Parallel Server. [MORL02, YDNR02]
10G RAC is aimed squarely at solving two of the most important problems facing those deploying data-
centric applications: 1) application availability and 2) affordable performance. These requirements are
important to data management customers, and consequently, Oracle and the industry as a whole offer
features to address these requirements based on application design, requirements, and the deployment
scenario.
2. Application Availability
Before looking at the more exotic availability techniques, it’s worth first reviewing a few core engineering
tenets. Application availability, especially when focusing on unplanned downtime, comes from a few
general principles applied to all aspects of overall system design: simplicity, redundancy, and isolation.
Simplicity
Any product or feature designed to improve overall application availability needs to be simple to administer
since operations and administrative error remains, by many measures, the single largest source of
application downtime. For example, a recent Oracle RAC white paper reported that administrative error
was the driver of 36% of the unplanned downtime experienced by a typical server side system [ORCL02].
David Patterson confirmed this result in his study, A Simple Way to Estimate the Cost of Downtime, where
he found that human error was responsible for 53% of the downtime [PATT01].
System complexity leads to administrative errors, and even where errors aren’t the eventual result, the
database administrator (DBA) time consumed by excessive system complexity is often substantial. These
day-to-day fire fights are often what prevent an administrative team from being able to focus more on long
term planning and improving the overall operations infrastructure. On this last point, that of administrative

complexity, there is considerable variability between the major DBMS providers, and this is worth studying
closely. However, ignoring these variations between competitors and just looking at the Oracle offerings,
RAC is far more complicated than their single node offering [FORE02]. A long time Oracle consultant
reports that a typical, well managed, single node Oracle system can easily achieve 99.9% reliability
whereas the same application workload running on a two node Oracle RAC, with the same level of
administrative investment, will typically achieve lower availability, often as low as 98% [YDNR02].
There is much room for debate on these reported results since they are all a product of the workload and the
quality of the DBAs managing the respective systems. However, there is little debate that complexity
either consumes high quality DBA time or leads to availability problems, and often both.
Operational and administrative simplicity is the strongest driver of application availability.
Redundancy
Components will fail, and there must be sufficient redundancy throughout the system to survive these
inevitable component failures in hardware, software, and administration. Any highly reliable system must
be composed of redundant components since avoiding single points of failure is the only reliable way to
achieve application availability in the presence of inevitable failures. Hardware and software components
will fail and, without sufficient redundancy in the system, component failure yields to loss of system
availability.
Over the last 15 years, considerable agreement has emerged on the best technology for database data
redundancy: log shipping among independent database nodes. IBM IMS Remote Site Recovery was one of
the first products, to implement this technique. The first public description of it known by the author was
by Burkes and Treiber at the 1989 High Performance Transaction Systems Workshop in Asilomar, CA.
[BURK89]. Oracle, DB2, and SQL Server all have similar, log shipping-based solutions with Oracle
offering DataGuard [ORCL01], IBM providing DB2 Log Shipping [DB203], and Microsoft offering SQL
Server 2000 Log Shipping [SQLS01] and the SQL Server 2005 Database Mirroring feature [SQLS02].
Database Mirroring will be used as an example to discuss some of the advantages of this approach to
database availability. Looking at Figure 1, it can be seen that with Database Mirroring (log shipping), the
primary node and the secondary node share no resources with the only connections between the two
systems being the low-level transaction log format. It should be noted that logging and recovery, the
components that interact with the transaction log, are the most tested and trusted code paths in a relational
database system.
In a log shipping configuration, the two systems are maintaining 100% independent hardware, software,
and copies of the data, and failure of any hardware or software component will not render the data
unavailable.
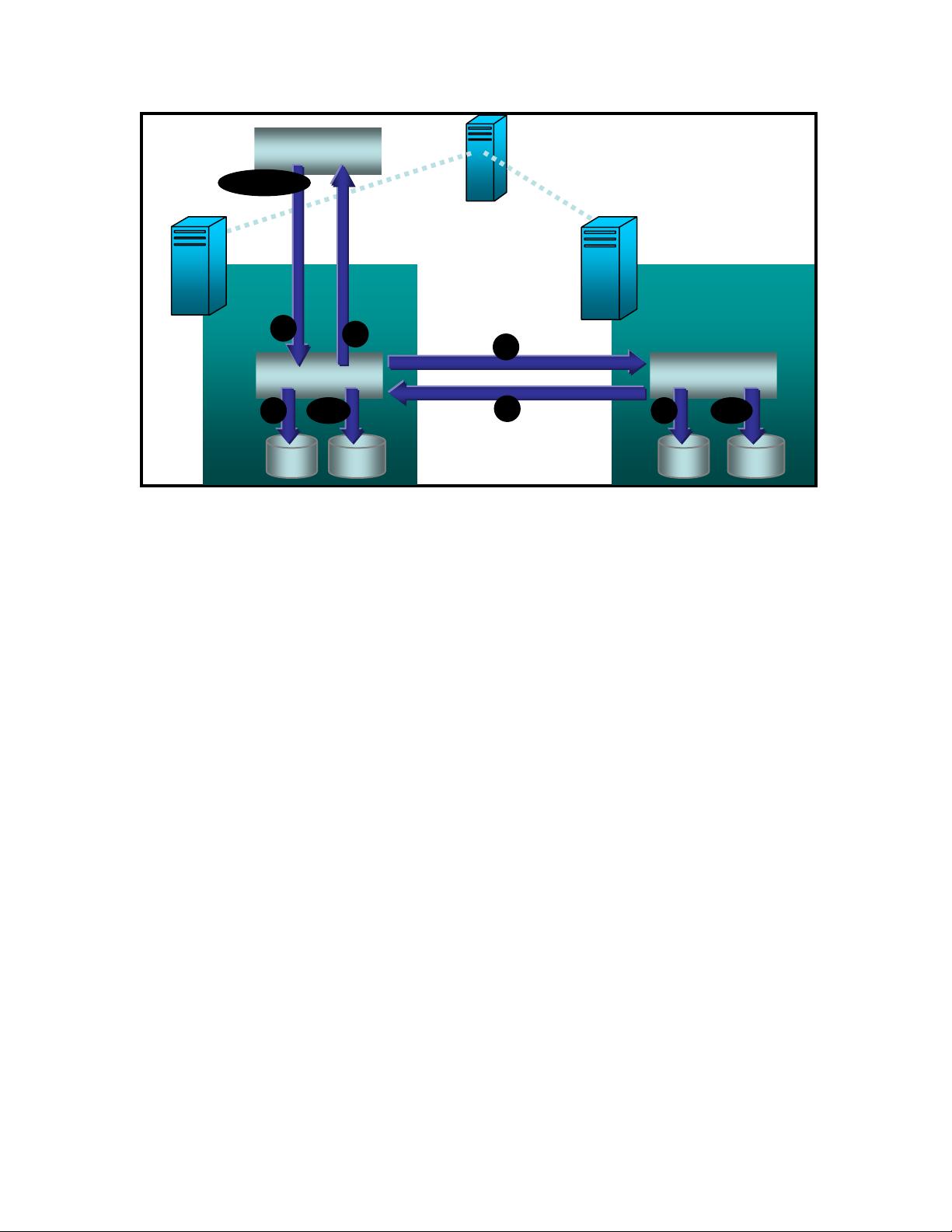
Figure 1 Database Mirroring
The Oracle RAC system (Figure 2) below lacks the degree of redundancy found in the log shipping design
shown above and all nodes in the cluster share the storage sub-system. With RAC, the database compute
nodes are redundant and interchangeable which is a good thing. However, there is only one copy of the
database itself which is to say that if part of the database gets damaged, data will become unavailable and
the entire cluster may be brought down.
Data redundancy is easy to achieve in any RAC deployment by using a RAID-based storage subsystem, but
this only provides protection against physical storage system failures. If there is corruption, data damage or
loss of data integrity logically “above” the storage subsystem, the SAN will dutifully redundantly store this
damaged data in multiple copies and the data will no longer be available to any node in the cluster.
However, with a log shipping solution such as DataGuard or Database Mirroring, the data is protected
against these failures since the redundant copy is made logically above the storage subsystem, the HBA, the
device drivers, and the operating system.
The key point to keep in mind is that a SAN can redundantly store multiple copies of the data that it
receives but can provide little protection against failures of other software and hardware components in
database, operating system, and storage stack.
M
M
i
i
r
r
r
r
o
o
r
r
P
P
r
r
i
i
n
n
c
c
i
i
p
p
a
a
l
l
W
W
i
i
t
t
n
n
e
e
s
s
s
s
Log
A
pp
lication
SQL Serve
r
SQL Serve
r
2
2
4
5
1
Data DataLog
3 >2 >3
Commit













