算法设计与分析实验报告
学号:12018002065 姓名:田维安
一、实验内容(问题)
实现密度峰值的聚类算法,作为不同于经典聚类算法 K-means 是
通过指定聚类中心,再通过迭代的方式更新聚类中心的方式,论文所
提出的先新聚类算法的基本思想非常新颖,因为经典算法 K-means,
由于每个点都指被指派到距离最近的聚类中心,所以导致其不能检测
非球面类别的数据分布,而且 K-means 在指定聚类中心方面,对于一
些问题的处理较为复杂。而且,根据查资料了解到的 DBSCAN
(density-based spatial clusering of applications with noise)对于任意形
状分布的进行聚类,但是必须指定一个密度阀值,从而去除低于此密
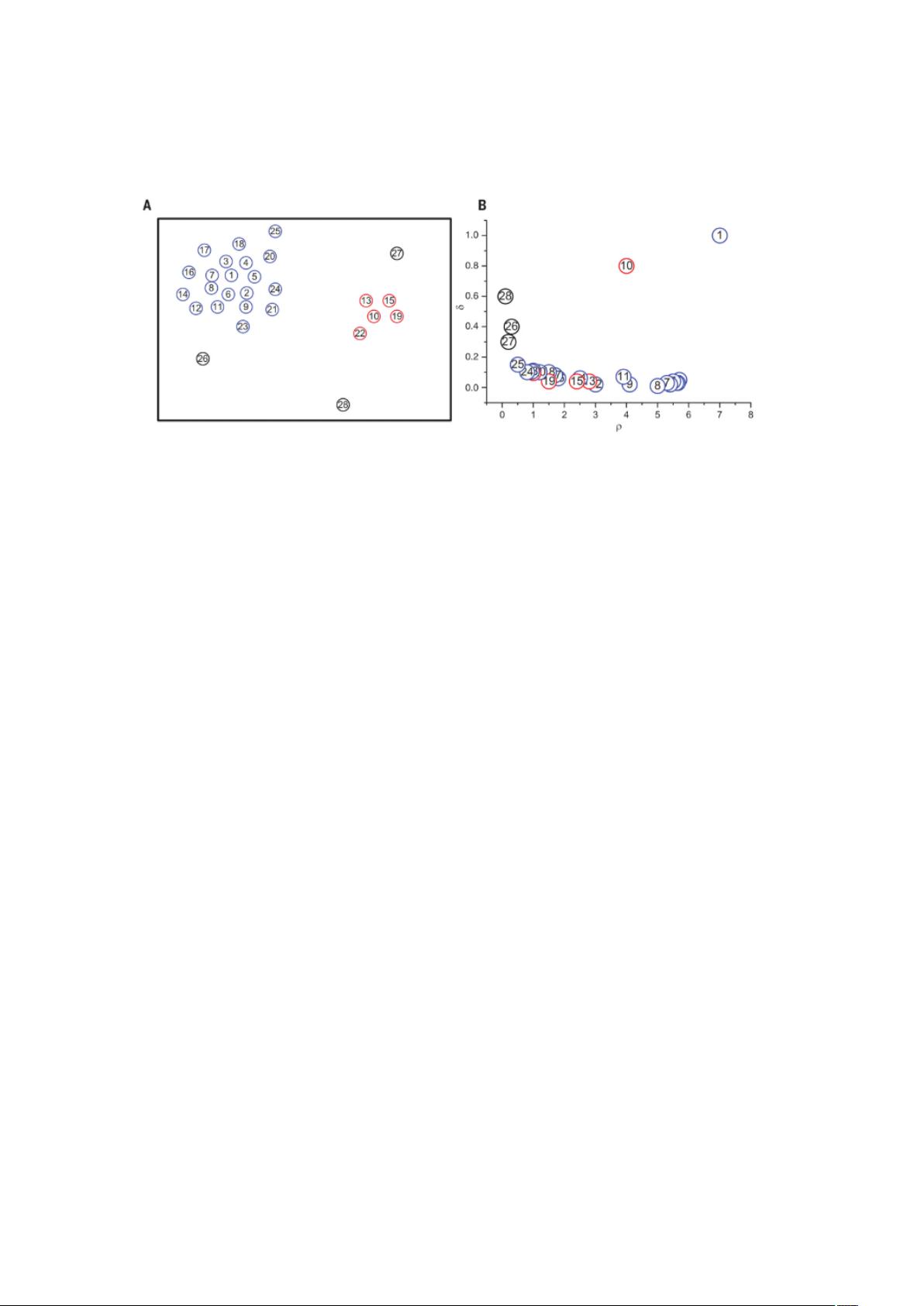
度阀值的噪音点。而论文中方法,给出了 CFDP 算法(clustering by fast
search and find of density peaks)的这样的假设:聚类中心周围都是密
度比其低的点,同时这些点距离该聚类中心的距离相比于其他聚类中
心来说是最近的。实现的问题,也就是基于这两个假设来识别和查找
聚类中心来实现这个算法的过程。
开发平台,先通过原文中作者给出的 matleb 算法的实例程序,
了解作者的算法思路,然后通过查找资料使用 pyhton 实现
开发平台:matleb,PyCharm。编程语言:MATLEB M 语言 Python