
SpringCloud 面试准备
前言
这周,我一位朋友在面试被问到了 Spring Cloud,然后结合他的反馈,今天
我们继续走起 SpringCloud 面试连环炮。
Spring Cloud 核心知识总结
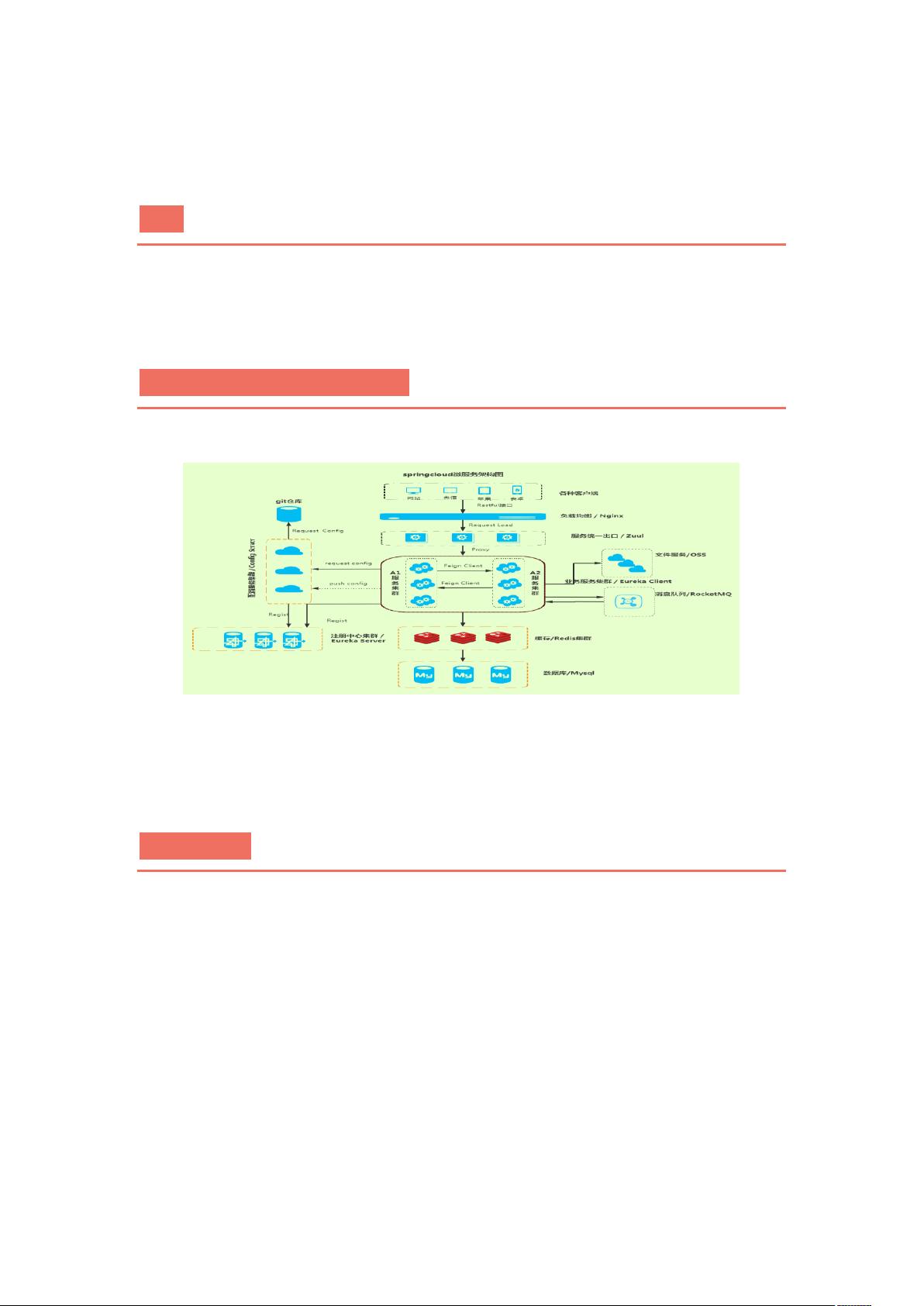
下面是一张 Spring Cloud 核心组件关系图:
从这张图中,其实我们是可以获取很多信息的,希望大家细细品尝。
话不多说,我们直接开始 Spring Cloud 连环炮。
连环炮走起
1、什么是 Spring Cloud ?
Spring cloud 流应用程序启动器是基于 Spring Boot 的 Spring 集成应用
程序,提供与外部系统的集成。Spring cloud Task,一个生命周期短暂的微
服务框架,用于快速构建执行有限数据处理的应用程序。
2、什么是微服务?


剩余10页未读,继续阅读
资源评论


唐伯虎点蚊香1997
- 粉丝: 0
- 资源: 13









最新资源
- 【独家首发】金枪鱼算法TSO优化Transformer-BiLSTM负荷数据回归预测【含Matlab源码 6558期】.zip
- 【独家首发】混沌博弈算法CGO优化Transformer-LSTM负荷数据回归预测【含Matlab源码 6382期】.zip
- 【独家首发】混沌博弈算法CGO优化Transformer-LSTM负荷数据回归预测【含Matlab源码 6382期】.zip
- 【独家首发】灰狼算法GWO优化Transformer-LSTM负荷数据回归预测【含Matlab源码 6381期】.zip
- 【独家首发】遗传算法GATransformer-LSTM负荷数据回归预测【含Matlab源码 6410期】.zip
- 【独家首发】灰狼算法GWO优化Transformer-LSTM负荷数据回归预测【含Matlab源码 6381期】.zip
- 【独家首发】鲸鱼算法WOA优化Transformer-BiLSTM负荷数据回归预测【含Matlab源码 6559期】.zip
- 【独家首发】鲸鱼算法WOA优化Transformer-BiLSTM负荷数据回归预测【含Matlab源码 6559期】.zip
- 【JCR一区级】被囊群算法TSA-Transformer-GRU负荷数据回归预测【含Matlab源码 6309期】.zip
- 【JCR一区级】被囊群算法TSA-Transformer-GRU负荷数据回归预测【含Matlab源码 6309期】.zip
- 【JCR1区】海洋捕食者算法MPA-CNN-SVM故障诊断分类预测【含Matlab源码 5790期】.zip
- 【JCR1区】海洋捕食者算法MPA-CNN-SVM故障诊断分类预测【含Matlab源码 5790期】.zip
- 多模型视角下的煤层瓦斯运移:双孔时变扩散模型与Comsol数值模拟复现研究,基于多孔介质时变扩散模型的煤层瓦斯运移研究:从双孔扩散模型到comsol数值模拟复现与参数确定,双孔扩散、时变扩散模型文献模
- MATLAB环境下一维时间序列信号的同步压缩变换算法实践:小波与短时傅里叶变换的探索与应用 该算法在R2018A环境中运行,涵盖模拟与真实信号案例,适用于金融、地震、语音、生理等多领域一维时间序列信
- 台达DVP EH3与三菱E700高效通讯程序集成包:实现频率设定、启停控制及读取实际频率的稳定程序,台达DVP EH3与三菱E700高效通讯程序集:功能丰富,稳定可靠的PLC变频控制与触摸屏交互实现指
- 【独家首发】减法平均算法SABO优化Transformer-BiLSTM负荷数据回归预测【含Matlab源码 6556期】.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


