
GPU BATCH NMS
YOLO 后处理的结构
1. Decoding 部分 目前 TRT yolo 层已经将输出结果转为了 x y w h,后续所作工作为筛选阈
值,pass 掉小于阈值的框,并且按照 class 分好类输出。
2. NMS 计算 IoU 矩阵。 NMS 算法发展至今已经迭代了许多版本,但是 NMS 的第一步依
旧都是计算 IoU 矩阵。
3. 过滤多余框。这一步是 NMS 算法迭代的主要优化点,出现了多种方法 Fast NMS,Cluster
NMS,Matrix NMS。
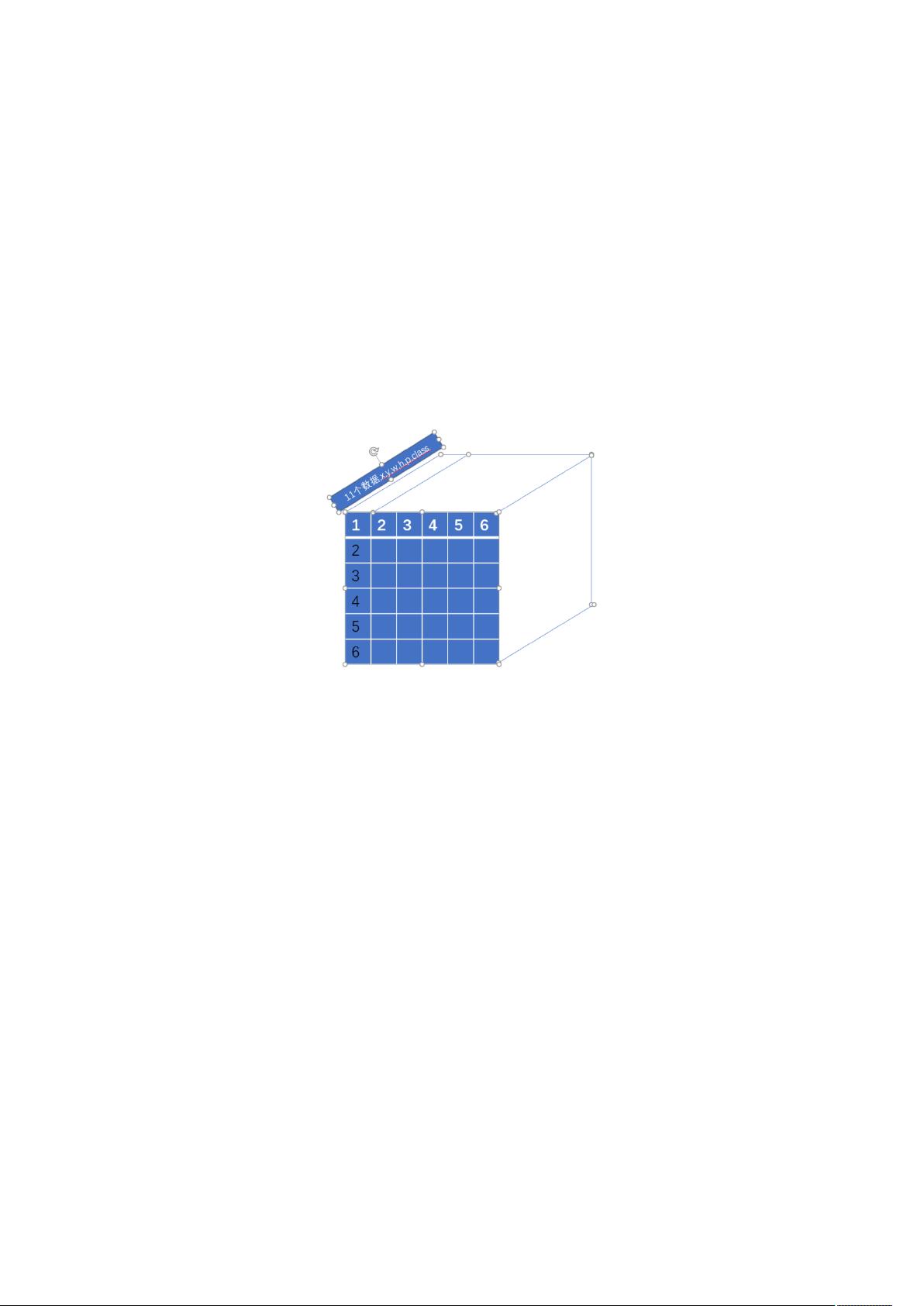
Decoding 部分,算法逻辑非常简单。目前有 64*64+32*32+16*16 个框数据需要做处理,建
立__goble__ Decoding()函数,设置 block 为(n , n),设置 gride 为(batch,3),使用 stream
并行处理三个尺度的 archors。
正视图上每一格为一个 bbox 框,每一个线程负责一个 bbox 从而起到加速效果。
另外新建同样大小的 Threshold 矩阵,class 矩阵,分别存放判断为 object 的框和类别。
另一部分为将 bbox 的 x y w h 还原为在原图的位置,这部分加速主要在这方面。
得出 Threshold 矩阵,class 矩阵之后,为每一个类别开辟相应大小的空间,将对应的数据整
理进去为计算 IoU 矩阵做准备。
__global__ void decode( float* yoloBoxs, float* boxLocation, float* classPreation ,
int gride_size, int threshold_index, int classNB,
int class_index, int archorsNB , int box_len, float threshold ,float alpha , float
beat ,const float *archor_w , const float *archor_h , const float w, const float h)
{
int threadIdX = threadIdx.x;
int threadIdY = threadIdx.y;
int archor_index = blockIdx.x;
int batchIndex = blockIdx.y;
int firstIndex = archor_index * box_len * gride_size + batchIndex * archorsNB *
box_len * gride_size;
int index_threshold = threadIdX + threshold_index* gride_size + firstIndex;
资源评论


极智视界
- 粉丝: 3w+
- 资源: 1770









最新资源
- 一个简单的更改所在目录文件名称的py脚本
- 基于Java的商务贸易管理系统设计与实现
- FANUC机器人折弯动作生成使用指南
- 非关系形数据库redis安装包
- 三款便捷高效的文件转换PDF转JPG、PPT转JPG、JPG转PDF小工具,支持右键、拖拽、批量互转工具.rar
- CorelDRAW vba cdr插件 带有中文译文的帮助文档
- Matlab 基于迁移学习的滚动轴承故障诊断 1.运行环境Matlab2021b及以上,该程序将一维轴承振动信号转为二维尺度图图像并使用预训练网络应用迁移学习对轴承故障进行分类,平均准确率在98%左右
- 锂电池Matlab仿真二阶RC等效电路模型 用m代码编写 两个工况:HPPC CC
- MATLAB四旋翼自适应控制仿真simulink simscape,可更成自己的无人机solidworks模型 有公式手册需MATLAB2017版本以上
- 六旋翼无人机PID模型,飞行器本体模型,位置控制,姿态控制,控制分配和电机控制
- 电动汽车定速巡航控制器 基于整车纵向动力学作为仿真模型 输入为目标车速,输出为驱动力矩、实际车速,包含PID模块 控制精度在0.2之内,定速效果非常好 自主开发,详细讲解,包含 资料内含.slx文件、
- 实验6 学生成绩管理系统实验报告(综合性实验).doc
- 通过动态规划优化PHEV能量管理
- 04fd6daf697bd9edabccfefd333fe2b4.zip
- C#上位机与omron欧姆龙 Fins TCP通信以太网通讯实例 源码 通过和PLC用网络连接,可以读取写入欧姆龙PLC的数据寄存器DM(批量也可以)、输入输出CIO、辅助继电器WR,H保持继电器等
- 90°180°旋转滚轮滚筒输送线sw12可编辑全套技术资料100%好用.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


