论文《Spell:大型非结构化系统日志的在线流式解析》翻译
需积分: 0 140 浏览量
2023-08-27
19:51:03
上传
评论 1
收藏 1.56MB DOCX 举报


Spell: Online Streaming Parsing of Large Unstructured System Logs
Spell:大型非结构化系统日志的在线流式解析
Abstract—System event logs have been frequently used as a valuable resource in data-
driven approaches to enhance system health and stability. A typical procedure in system
log analytics is to first parse unstructured logs to structured data, and then apply data
mining and machine learning techniques and/or build workflow models from the resulting
structured data. Previous work on parsing system event logs focused on offline, batch
processing of raw log files. But increasingly, applications demand online monitoring and
processing. As a result, a streaming method to parse unstructured logs is needed. We
propose an online streaming method Spell, which utilizes a longest common subsequence
based approach, to parse system event logs. We show how to dynamically extract log
patterns from incoming logs and how to maintain a set of discovered message types in
streaming fashion. An enhancement to find more accurate message types is also proposed.
We also propose and evaluate a method to automatically discover semantic meanings for
parameter fields identified by Spell. We compare Spell against state-of-the-art methods to
extract patterns from system event logs on large real data. The results demonstrate that,
compared with other log parsing alternatives, Spell shows its superiority in terms of both
efficiency and effectiveness.
Index Terms—Log parsing, log data, system logs
摘要—系统事件日志作为一种有价值的资源,在数据驱动的方法中被频繁地使用,
以增强系统的健康和稳定性。系统日志分析的一个典型过程是首先将非结构化日志
解析为结构化数据,然后应用数据挖掘和机器学习技术和/或从构建结构化数据中建
立工作流模型。 以前解析系统事件日志的工作主要集中在脱机、批处理原始日志文
件上。 但越来越多的应用程序需要在线监控和处理。 因此,需要一种流式方法来
解析非结构化日志。 提出了一种基于最长公共子序列的在线流方法 Spell,用于解



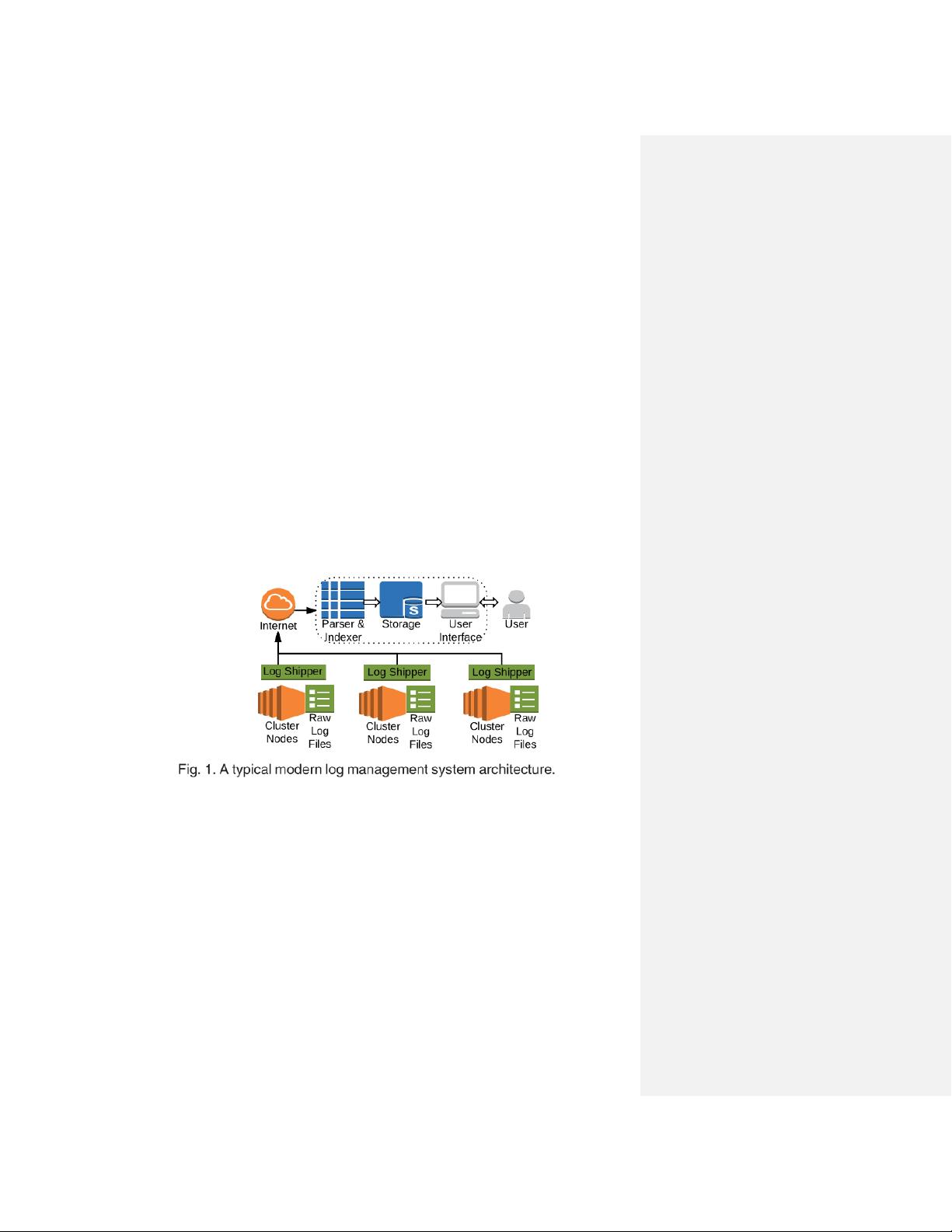
剩余66页未读,继续阅读
资源评论


ProgrammerMonkey
- 粉丝: 43
- 资源: 37









最新资源
- vue自定义指令( 复制、拖动、权限)
- json格式文件备份redis数据库 工具
- Multi-Agent-Flocking.zip
- 指标公式未来函数检测工具V1.2
- projectData
- SQL Server 性能监视器,它旨在提供开箱即用的全面监控,并作为您自己的项目或应用程序的监控框架 它在本地数据库中收集性能
- Python 程序语言设计模式思路-并发模式:线程池模式:管理线程池,优化线程创建和销毁
- 股事汇投资工具-实时新闻、财经日历、市场快讯、持仓查询、外汇兑换、换算工具、大盘云图、江恩工具、指标检测等
- webrtc-streamer
- html+css+'青春献礼二十大 红色旅游助乡村'为主题的网页设计 2022年参与学校网页设计比赛时完成的
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


