"随机森林汇报代码大全.pptx"
随机森林汇报代码大全.pptx是关于机器学习算法中的决策树和随机森林的综合性报告。该报告对决策树的结构、训练和测试进行了详细的介绍,并对熵的计算和信息增益进行了深入的分析。
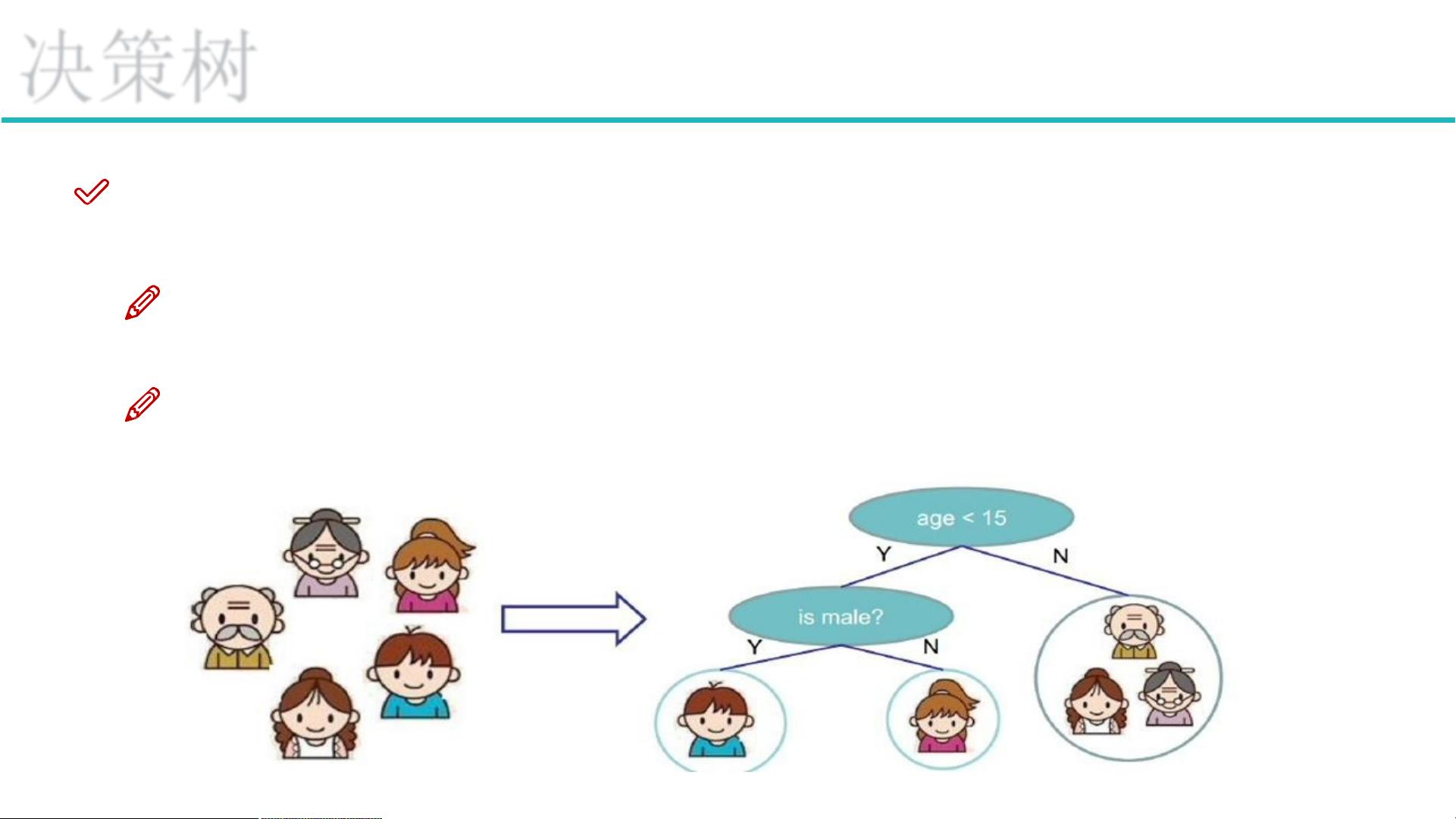
决策树是一种有监督学习算法,它通过对样本的特征进行多次判断(决策),从而分出样本类别。决策树的结构主要由根节点、非叶子节点和叶子节点组成。根节点是第一个决策点,非叶子节点是中间过程的决策点,而叶子节点是最终的决策结果。
决策树的构建主要有两步:训练阶段和测试阶段。在训练阶段,从给定的训练集构造出来一棵树,从跟节点开始选择特征,如何进行特征切分。问题是根节点的选择该用哪个特征呢?接下来呢?如何切分呢?决策树如何切分特征(选择节点)想象一下:我们的目标应该是根节点就像一个老大似的能更好的切分数据(分类的效果更好),根节点下面的节点自然就是二当家了。
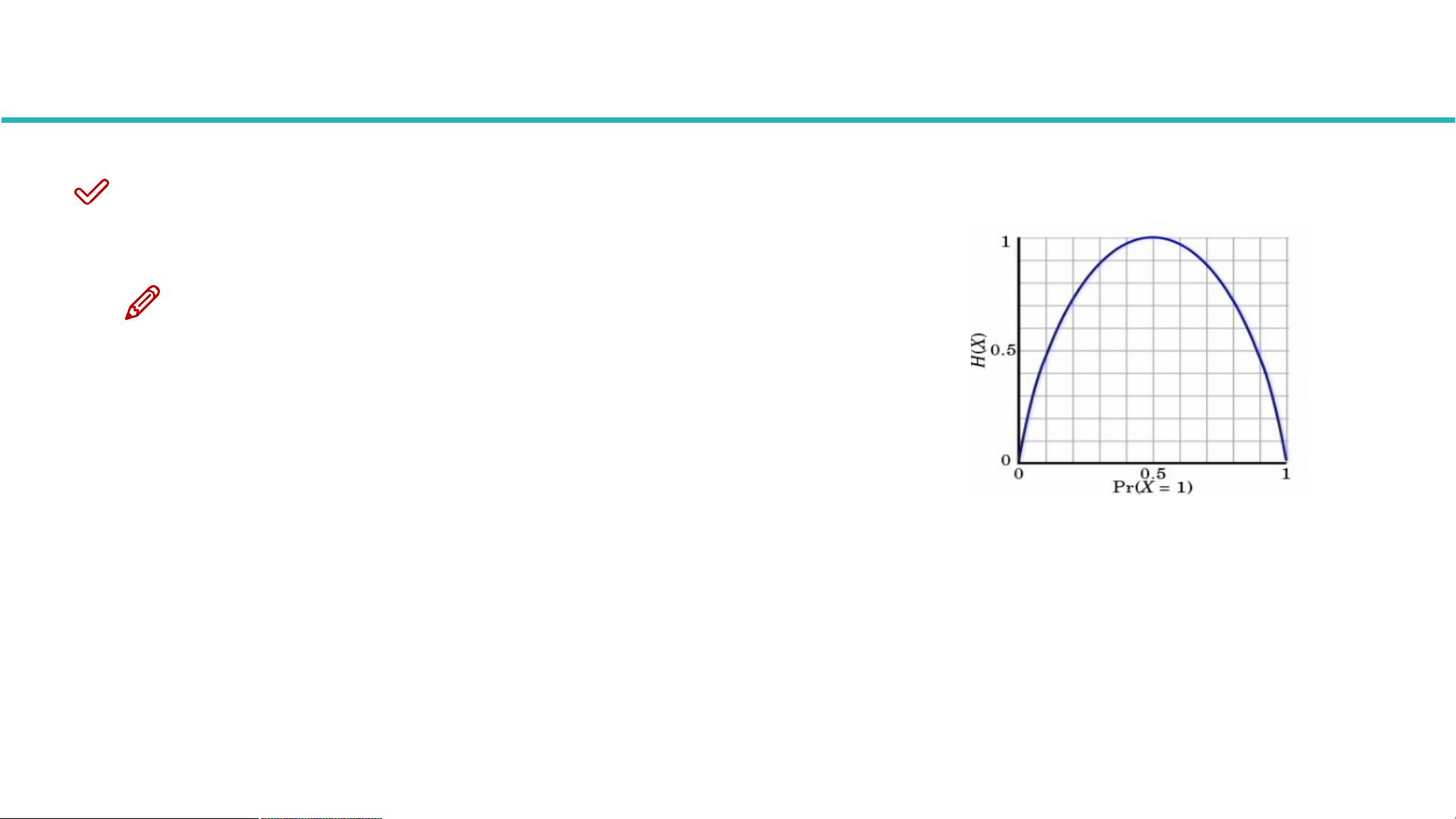
熵是表示随机变量不确定性的度量公式为Ent(D)=∑ -pi * logpi, i=1,2, ... , n。熵的计算可以用来衡量决策树的分类效果。例如,A集合[1,1,1,1,1,1,1,1,2,2]的熵为-0.8xlog0.8-0.2xlog0.2=0.722,而B集合[1,2,3,4,5,6,7,8,9,1]的熵为-0.2xlog0.2+8*(-0.1xlog0.1)=3.122。
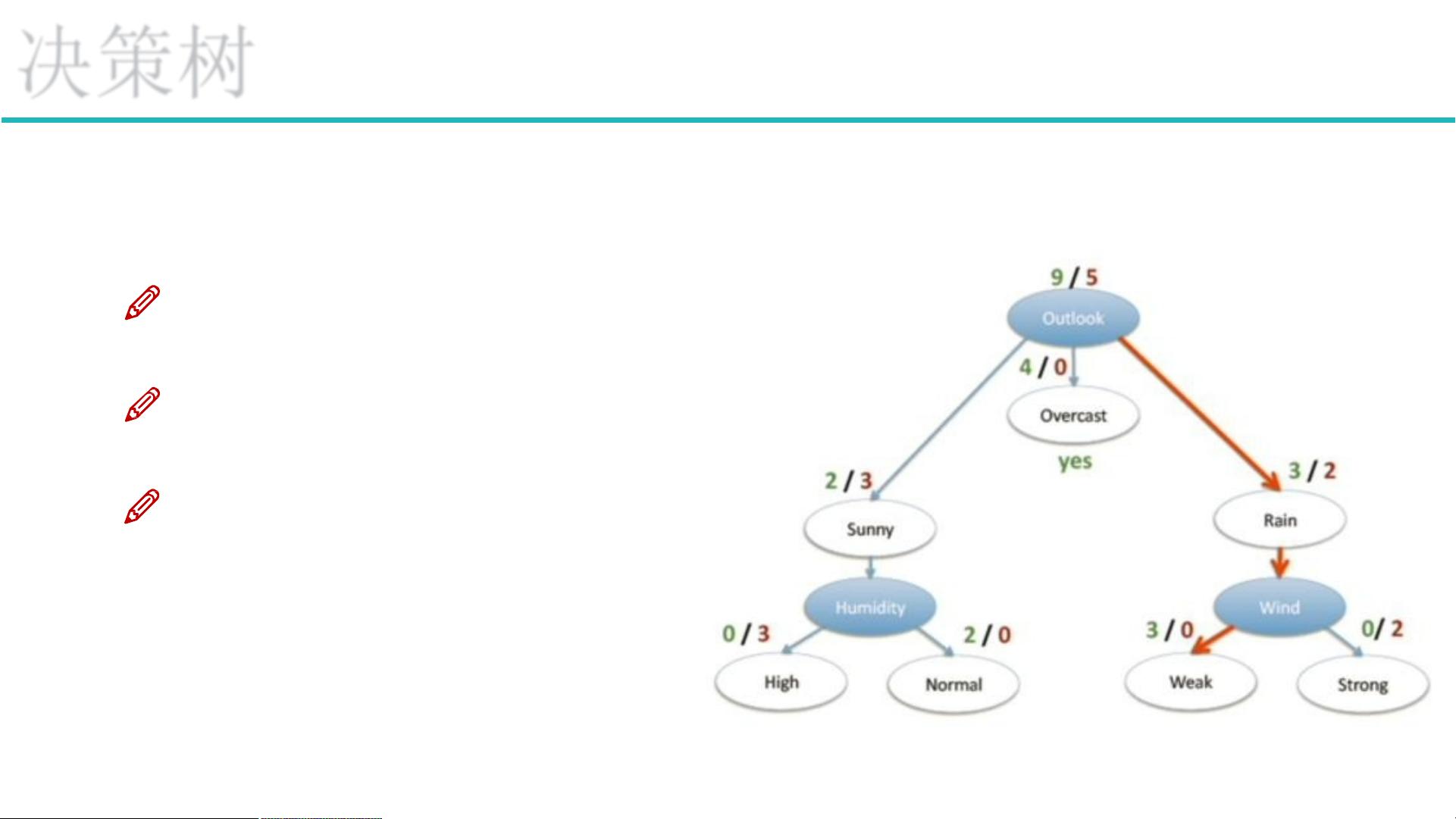
ID3算法是决策树构造的一种方法,通过信息增益来选择特征。例如,在历史数据中(14天)有9天打球,5天不打球,所以此时的熵应为:熵值计算:5/14 * 0.971 + 4/14 * 0 + 5/14 * 0.971 = 0.693(gain(temperature)=0.029 gain(humidity)=0.152 gain(windy)=0.048)。信息增益:系统的熵值从原始的0.940下降到了0.693,增益为0.247。
然而,ID3算法也存在一些缺点,例如,如果把编号1—14也算为特征,那么按照公式,Ent(D|A)=1/14 X (-1*log1) X 14 = 0Gain(D,A)=0.940-0=0.940一步就分完类,但这显然是不正确的。因此,需要对ID3算法进行改进,例如C4.5算法。
CART分类树算法和CART回归树算法是决策树的两种形式,它们都可以用来分类和回归。决策树与随机森林的关系是,随机森林是多棵决策树的集合,它可以提高分类和回归的准确性。
处理连续值是决策树的一个重要问题,离散化区间划分熵值分割是其中的一种方法。连续值的处理可以通过离散化来实现,例如,将连续值分为多个离散的区间,然后计算每个区间的熵值。
随机森林汇报代码大全.pptx对决策树和随机森林进行了深入的介绍,涵盖了决策树的结构、训练和测试、熵的计算和信息增益、ID3算法和其缺点、CART分类树算法和CART回归树算法、决策树与随机森林的关系、处理连续值等方面的知识点。









评论0
最新资源