
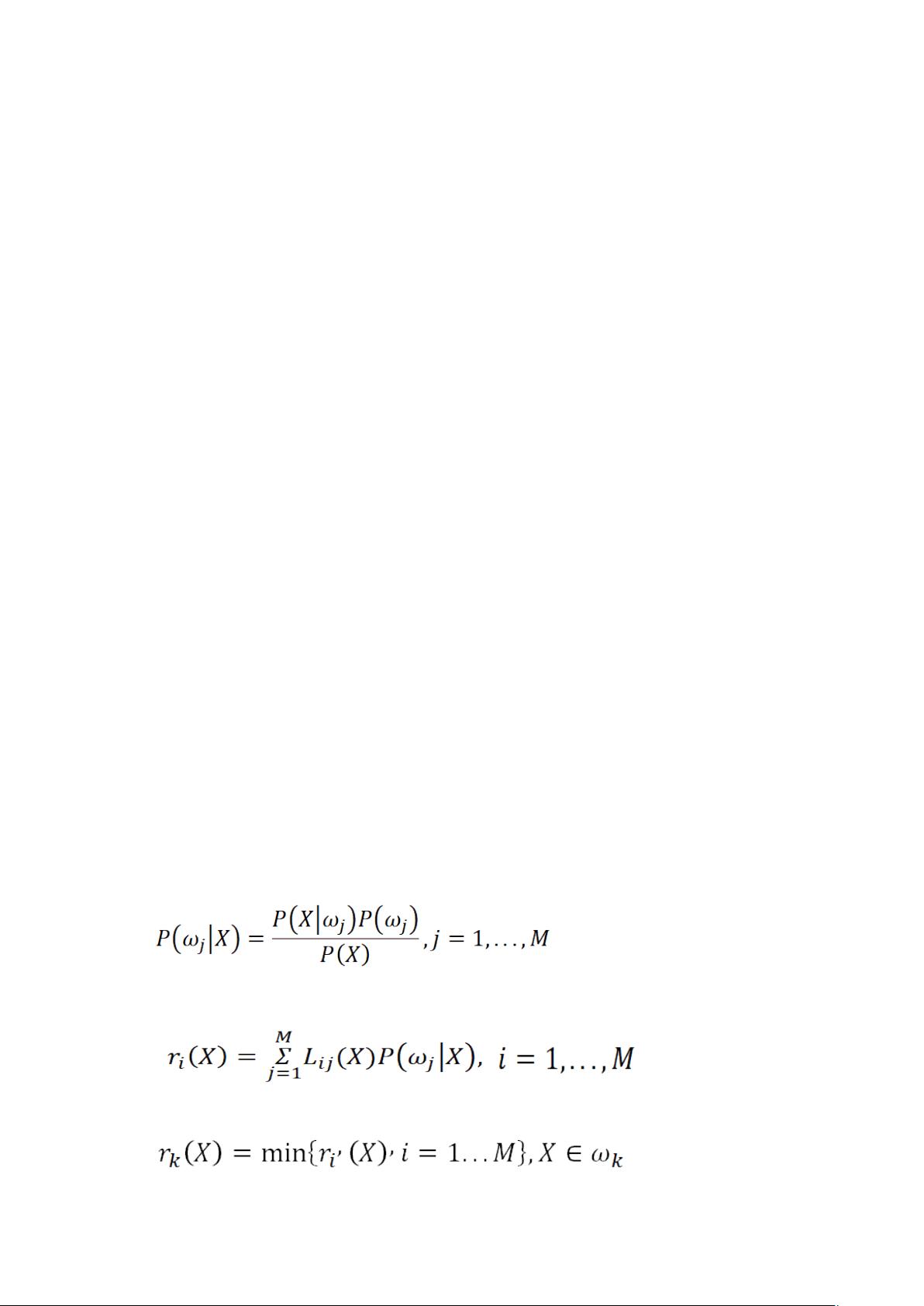
1 贝叶斯分类器的介绍及实现
1.1 主要研究内容
(1)本小组主要完成的任务是介绍 3 种贝叶斯分类器(最小错误率贝叶斯
分类器、最小风险贝叶斯分类器以及朴素贝叶斯分类器)的原理,然后利用这 3
种分类器分别对公开的鸢尾花数据集进行预测分类。
(2)本人主要负责最小风险贝叶斯分类器原理和计算步骤的介绍,整理资
料并制作最小风险贝叶斯分类器相关部分的 PPT。
1.2 最小风险贝叶斯分类器原理介绍
1.2.1 基本思想
在决策中,除了关心决策的正确与否,有时我们更关心错误的决策将带来怎
样的损失。比如在判断细胞是否为癌细胞的决策中,若把正常细胞判定为癌细胞,
将会增加患者的负担和不必要的治疗,但若把癌细胞判定为正常细胞,将会导致
患者错过治疗癌症的机会,甚至会影响患者的生命。这两种类型的决策错误所产
生的代价是不同的。
考虑到某一类的错判要比对另一类的错判更为关键,把最小错误率的贝叶斯
判决做一些修改,提出了“条件平均风险”的概念。最小风险贝叶斯决策基本思
想是以各种错误分类所造成的平均风险最小为规则,进行分类决策。
1.2.2 计算步骤
(1)利用贝叶斯公式计算后验概率:
(2)计算条件风险:
(3)选择风险最小的决策:
资源评论


李逍遥敲代码
- 粉丝: 2992
- 资源: 277









最新资源
- ShellTransition学习笔记
- 5G+AI智慧高校大数据顶层规划设计及应用方案(67页PPT).pptx
- 基于PWM的 三色灯RGB模块调色 标准库 代码
- 基于Simulink仿真的光储并网直流微电网模型研究:MPPT最大功率输出与混合储能系统的协同优化,基于Simulink仿真的光储并网直流微电网模型研究:MPPT最大功率输出与混合储能系统的协同优化
- JAVA实现有趣的迷宫小游戏(附源码).zip
- 基于NRBO-Transformer-BILSTM的深度学习模型:多特征分类预测与性能评估的Matlab实现,基于NRBO-Transformer-BILSTM的多特征分类预测模型与性能评估的Matl
- 磁链观测器在VESC中的应用方法及其代码、文档、仿真模型的对应关系以及附送翻译的Lawicel CANUSB驱动,磁链观测器在VESC中的应用:实现0速闭环启动,代码、文档、仿真模型供学习,磁链观测器
- 基于多智能体一致性算法的电力系统分布式经济调度策略:迭代优化与仿真验证,基于多智能体一致性算法与迭代计算的电力系统分布式经济优化调度策略(MATLAB实现),MATLAB代码基于多智能体系统一致性算
- 2013.8.5-2025.3.5碳排放权交易数据(日度).xlsx
- 中断上下文详细解析PDF详细内容
- VC-redist.x64-14.42.34438.0.7z
- MATLAB实现基于BiGRU-AdaBoost双向门控循环单元结合AdaBoost多输入分类预测(含模型描述及示例代码)
- Matlab实现KOA-CNN-GRU-selfAttention多特征分类预测(自注意力机制)(含模型描述及示例代码)
- MATLAB实现SSA-CNN-BiLSTM-Attention多变量时间序列预测(SE注意力机制)(含模型描述及示例代码)
- 基于磁耦合谐振的无线电能传输设计:MATLAB仿真中的PWM控制与过零检测模块探讨及二极管与同步整流技术的结合应用 ,基于Matlab Simulink仿真的无线电能传输设计:磁耦合谐振与PWM MO
- 博图16立体车库控制系统:PLC运行效果视频展示与接线图详解,深度解析:4x5立体车库控制系统的博图16版本,含PLC运行效果视频、详细接线图及IO表,4x5立体车库控制系统 博图16 带PLC运行效
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


