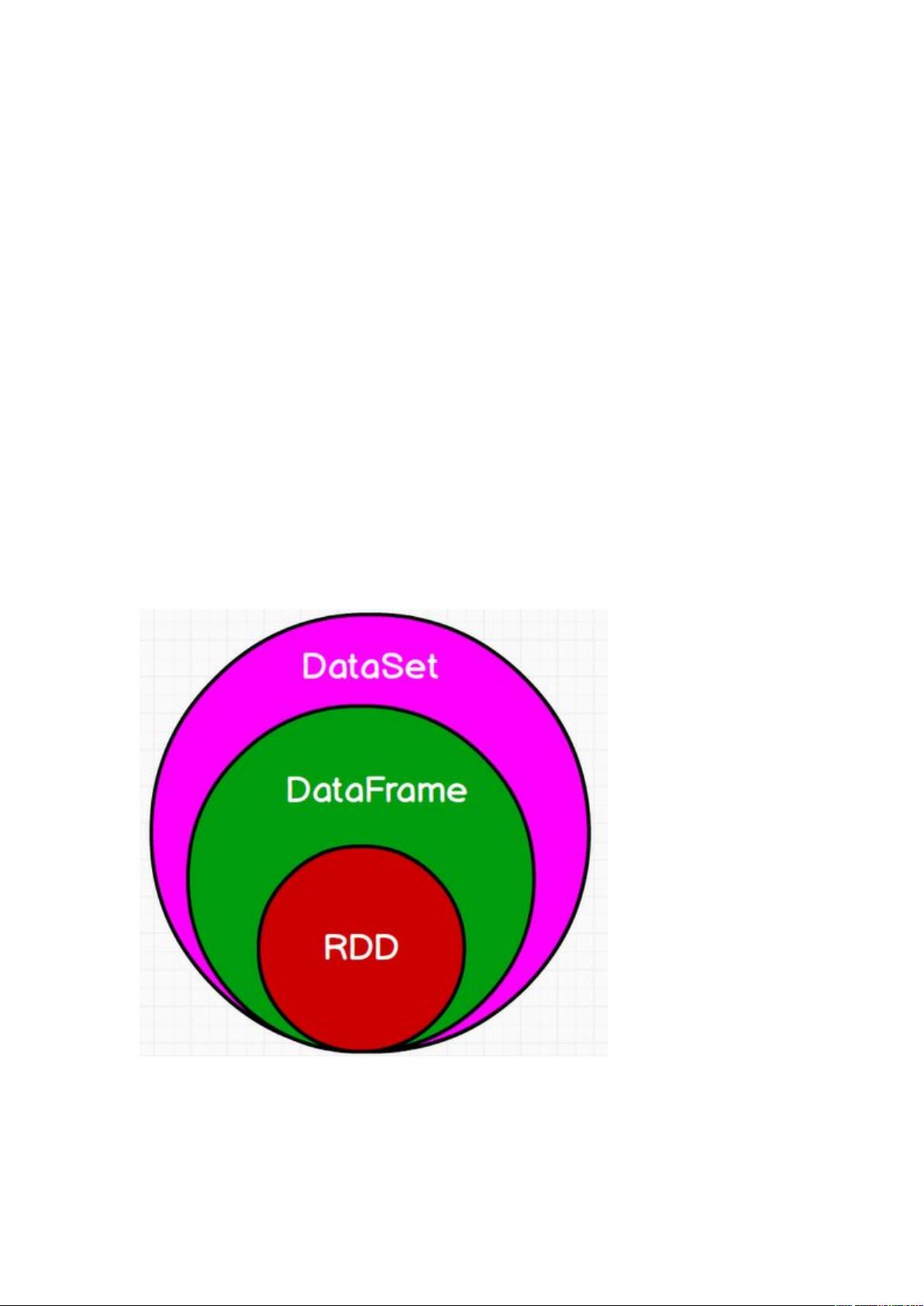
spark三大数据结构
需积分: 50 89 浏览量
2020-03-29
08:30:28
上传
评论
收藏 160KB DOCX 举报


spark 三大数据结构
1. Rdd
1.1 定义
数据集:存储的是数据的计算逻辑
分布式:数据的来源$计算$数据的存储
弹性:
血缘(依赖关系):spark 可以通过特殊的处理方案简化依赖关系
计算:spark 是基于内存的,所以性能非常高,可以和磁盘进行灵活切换
分区:spark 在创建默认分区后,可以通过指定的算子来改变分区数量
容错:spark 在执行计算时,如果发生错误,需要进行容错重试处理
数量
Spark 中数量,Executor:可以通过提交应用的参数进行设定
Paron:默认情况下,读取文件采用的是 hadoop 的切片规则,如果读取内存中的数据,
可以根据特定的算法进行设定,可以通过其他算子改变。
多个阶段的场合,下一个阶段的分区数量取决于上一个阶段最后 RDD 的分区数,但是可以
在相应的算子中进行修改
Stage:1(ResultStage)+Shue 依赖的数量(ShueMapStage),划分阶段的目的就是为了任务
执行的等待,因为 Shue 的过程需要落盘
Task:原则上是一个分区一个任务,但是实际应用中,可以动态调整

剩余19页未读,继续阅读
资源评论


weixin_41801538
- 粉丝: 2
- 资源: 2









最新资源
- 农村信用社联合社计算机信息系统投产与变更管理办.docx
- 农村信用社联合社计算机信息系统数据管理办法.docx
- 利用SPSS作临床效度分析线上计算网站介绍-医学研究部统计谘.(医学PPT课件).ppt
- 利用Zabbix监控mysqldump定时备份数据库状态.docx
- 利用计算机解决问题的基本过程.doc
- 化工铁路通信工程总结.doc
- 北京大学网络教育软件工程作业.docx
- 医药公司(连锁店)计算机操作规程未新系统的自行按照旧制修改-新系统过制的编号加修模版.doc
- 医药公司(连锁店)计算机系统操作规程模版.doc
- 医药连锁门店计算机系统的操作和管理程序未新系统的自行按照旧制修改-新系统过制的编号加修模版.docx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


