

IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 26, NO. 5, MAY 2017 2545
Semi-Supervised Sparse Representation Based
Classification for Face Recognition With
Insufficient Labeled Samples
Yuan Gao, Jiayi Ma, and Alan L. Yuille, Fellow, IEEE
Abstract—This paper addresses the problem of face recogni-
tion when there is only few, or even only a single, labeled examples
of the face that we wish to recognize. Moreover, these examples
are typically corrupted by nuisance variables, both linear (i.e.,
additive nuisance variables, such as bad lighting and wearing
of glasses) and non-linear (i.e., non-additive pixel-wise nuisance
variables, such as expression changes). The small number of
labeled examples means that it is hard to remove these nuisance
variables between the training and testing faces to obtain good
recognition performance. To address the problem, we propose a
method called semi-supervised sparse representation-based clas-
sification. This is based on recent work on sparsity, where faces
are represented in terms of two dictionaries: a gallery dictionary
consisting of one or more examples of each person, and a variation
dictionary representing linear nuisance variables (e.g., different
lighting conditions and different glasses). The main idea is that:
1) we use the variation dictionary to characterize the linear
nuisance variables via the sparsity framework and 2) prototype
face images are estimated as a gallery dictionary via a Gaussian
mixture model, with mixed labeled and unlabeled samples in
a semi-supervised manner, to deal with the non-linear nuisance
variations between labeled and unlabeled samples. We have done
experiments with insufficient labeled samples, even when there is
only a single labeled sample per person. Our results on the AR,
Multi-PIE, CAS-PEAL, and LFW databases demonstrate that
the proposed method is able to deliver significantly improved
performance over existing methods.
Index Terms— Gallery dictionary learning, semi-supervised
learning, face recognition, sparse representation based classifi-
cation, single labeled sample per person.
I. INTRODUCTION
F
ACE Recognition is one of the most fundamental prob-
lems in computer vision and pattern recognition. In the
Manuscript received September 12, 2016; revised January 3, 2017; accepted
February 13, 2017. Date of publication February 28, 2017; date of current
version April 1, 2017. This work was supported in part by the National
Natural Science Foundation of China under Grant 61503288, in part by
the China Postdoctoral Science Foundation under Grant 2016T90725, and
in part by the NSF Award CCF under Grant 1317376. The associate editor
coordinating the review of this manuscript and approving it for publication was
Prof. Amit K. Roy Chowdhury. (Corresponding author: Jiayi Ma.)
Y. Gao is with the Electronic Information School, Wuhan University, Wuhan
430072, China, and also with the Tencent AI Laboratory, Shenzhen 518057,
China (e-mail: ethan.y.gao@gmail.com).
J. Ma is with the Electronic Information School, Wuhan University, Wuhan
430072, China (e-mail: jyma2010@gmail.com).
A. L. Yuille is with the Department of Statistics, University of California
at Los Angeles, Los Angeles, CA 90095 USA, and also with the Department
of Cognitive Science, Department of Computer Science, Johns Hopkins
University, Baltimore, MD 21218 USA (e-mail: yuille@stat.ucla.edu).
Color versions of one or more of the figures in this paper are available
online at http://ieeexplore.ieee.org.
Digital Object Identifier 10.1109/TIP.2017.2675341
past decades, it has been extensively studied because of its
wide range of applications, such as automatic access con-
trol system, e-passport, criminal recognition, to name just
a few. Recently, the Sparse Representation based Classifi-
cation (SRC) method, introduced by Wright et al. [1], has
received a lot of attention for face recognition [2]–[5]. In SRC,
a sparse coefficient vector was introduced in order to represent
the test image by a small number of training images. Then
the SRC model was formulated by jointly minimizing the
reconstruction error and the
1
-norm on the sparse coefficient
vector [1]. The main advantages of SRC have been pointed
out in [1] and [6]: i) it is simple to use without carefully
crafted feature extraction, and ii) it is robust to occlusion and
corruption.
One of the most challenging problems for practical face
recognition application is the shortage of labeled samples [7].
This is due to the high cost of labeling training samples by
human effort, and because labeling multiple face instances
may be impossible in some cases. For example, for terrorist
recognition, there may be only one sample of the terrorist,
e.g. his/her ID photo. As a result, nuisance variables (or
so called intra-class variance) can exist between the testing
images and the limited amount of training images, e.g. the
ID photo of the terrorist (the training image) is a standard
front-on face with neutral lighting, but the testing images
captured from the crime scene can often include bad lighting
conditions and/or various occlusions (e.g. the terrorist may
wear a hat or sunglasses). In addition, the training and testing
images may also vary in expressions (e.g. neutral and smile) or
resolution. The SRC methods may fail in these cases because
of the insufficiency of the labeled samples to model nuisance
variables [8]–[12].
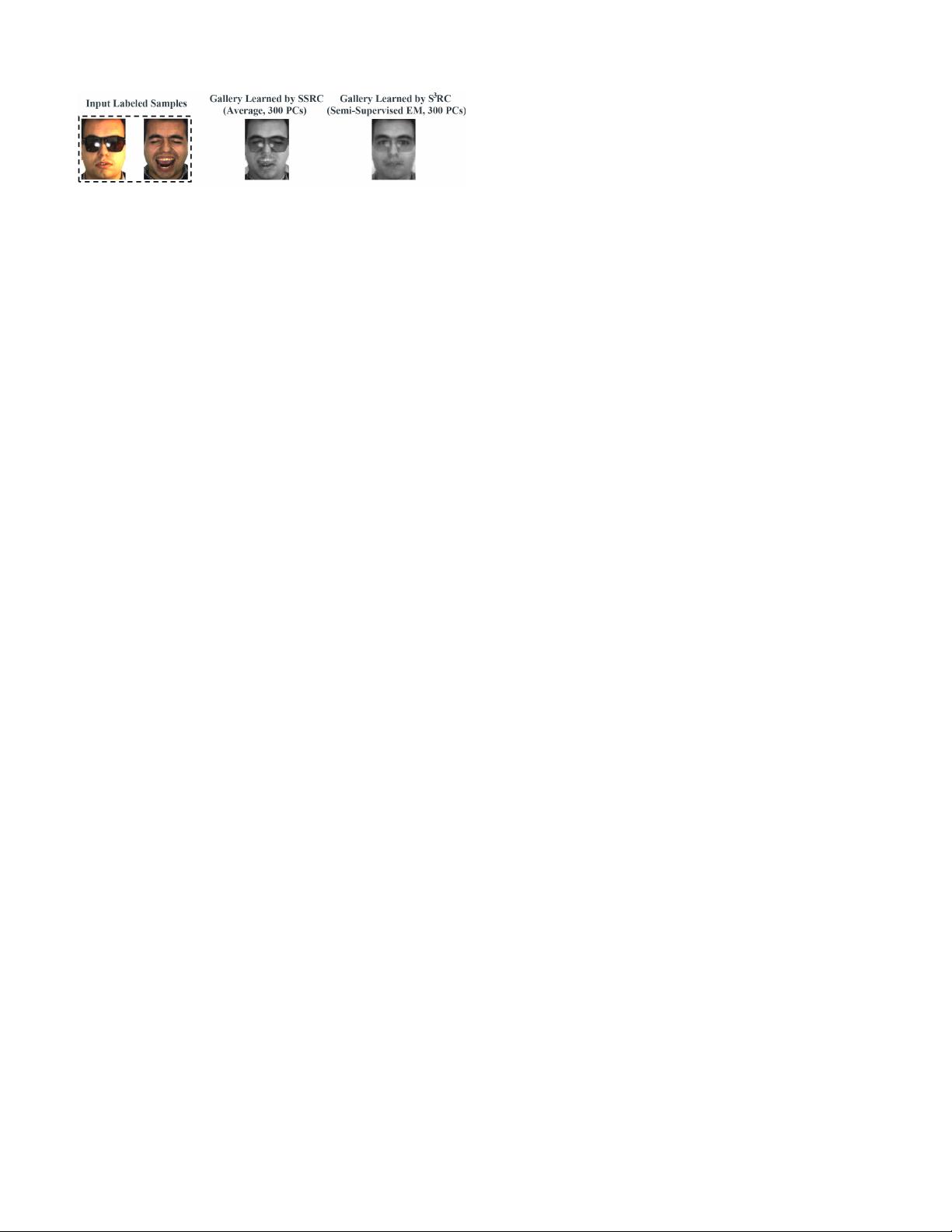
In order to address the insufficient labeled samples problem,
Extended SRC (ESRC) [13] assumed that a testing image
equals a prototype image plus some (linear) variations. For
example, a image with sunglasses is assumed to equal to
the image without sunglasses plus the sunglasses. Therefore,
ESRC introduced two dictionaries: (i) a gallery dictionary con-
taining the prototype of each person (these are the persons to
be recognized), and (ii) a variation dictionary which contains
nuisance variations that can be shared by different persons
(e.g. different persons may wear the same sunglasses). Recent
improvements on ESRC can give good results for this problem
even when the subject only has a single labeled sample
(namely the Single Labeled Sample Per Person problem,
i.e. SLSPP) [14]–[17].
1057-7149 © 2017 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission.
See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.

剩余15页未读,继续阅读
资源评论













