
T5
/
T0
Filter Model
Reframing Human-AI Collaboration for
Generating Free-Text Explanations
Sarah Wiegreffe
♣
Jack Hessel
†
Swabha Swayamdipta
†
Mark Riedl
♣
Yejin Choi
令†
♣
School of Interactive Computing, Georgia Institute of Technology
†
Allen
Institute
for
Artificial
Intelligence
令
Paul G. Allen School of Computer Science and Engineering, University of Washington
saw@gatech.edu,
riedl@cc.gatech.edu,
{jackh,swabhas,yejinc}@allenai.org
Abstract
Large language models are increasingly capa-
ble of generating fluent-appearing text with rel-
atively little task-specific supervision. But can
these models accurately explain classification
decisions? We consider the task of generating
free-text explanations using human-written ex-
amples in a few-shot manner.
We find that
(1) authoring higher quality prompts results
in higher quality generations; and (2) surpris-
ingly, in a head-to-head comparison, crowd-
workers often prefer explanations generated by
GPT-3 to crowdsourced explanations in exist-
“Usually a hamburger with friends
indicates a good time.”
Select-
1
Explanation-
Level
Acceptability
Predictions
Crowdworker
Acceptability
ing datasets. Our human studies also show,
however, that while models often produce fac-
tual, grammatical, and sufficient explanations,
they have room to improve along axes such
greedy
stochastic
Labels
as providing novel information and supporting
the label. We create a pipeline that combines
GPT-3 with a supervised filter that incorpo-
rates binary acceptability judgments from hu-
mans in the loop. Despite the intrinsic subjec-
tivity of acceptability judgments, we demon-
strate that acceptability is partially correlated
with various fine-grained attributes of explana-
tions. Our approach is able to consistently fil-
ter GPT-3-generated explanations deemed ac-
ceptable by humans.
1 Introduction
As natural language understanding tasks have be-
come increasingly complex, the field of explainable
NLP has embraced explanations written in free-
form natural language. In contrast to extractive
explanations that highlight tokens in the input, free-
text explanations provide a natural interface be-
tween machine computation and human end-users
(Hendricks et al., 2016; Camburu et al., 2018). The
dominant paradigm for producing free-text expla-
nations is via direct supervision, i.e., training an
autoregressive, generative language model to pre-
dict human-authored explanations directly (Kim
et al., 2018; Park et al., 2018; Ehsan et al., 2018;
Narang et al., 2020; Wiegreffe et al., 2021, i.a.).
“When eating a hamburger with friends, what is
one trying to do?” have fun. Explanation: …
Instance + Explanation Prompt
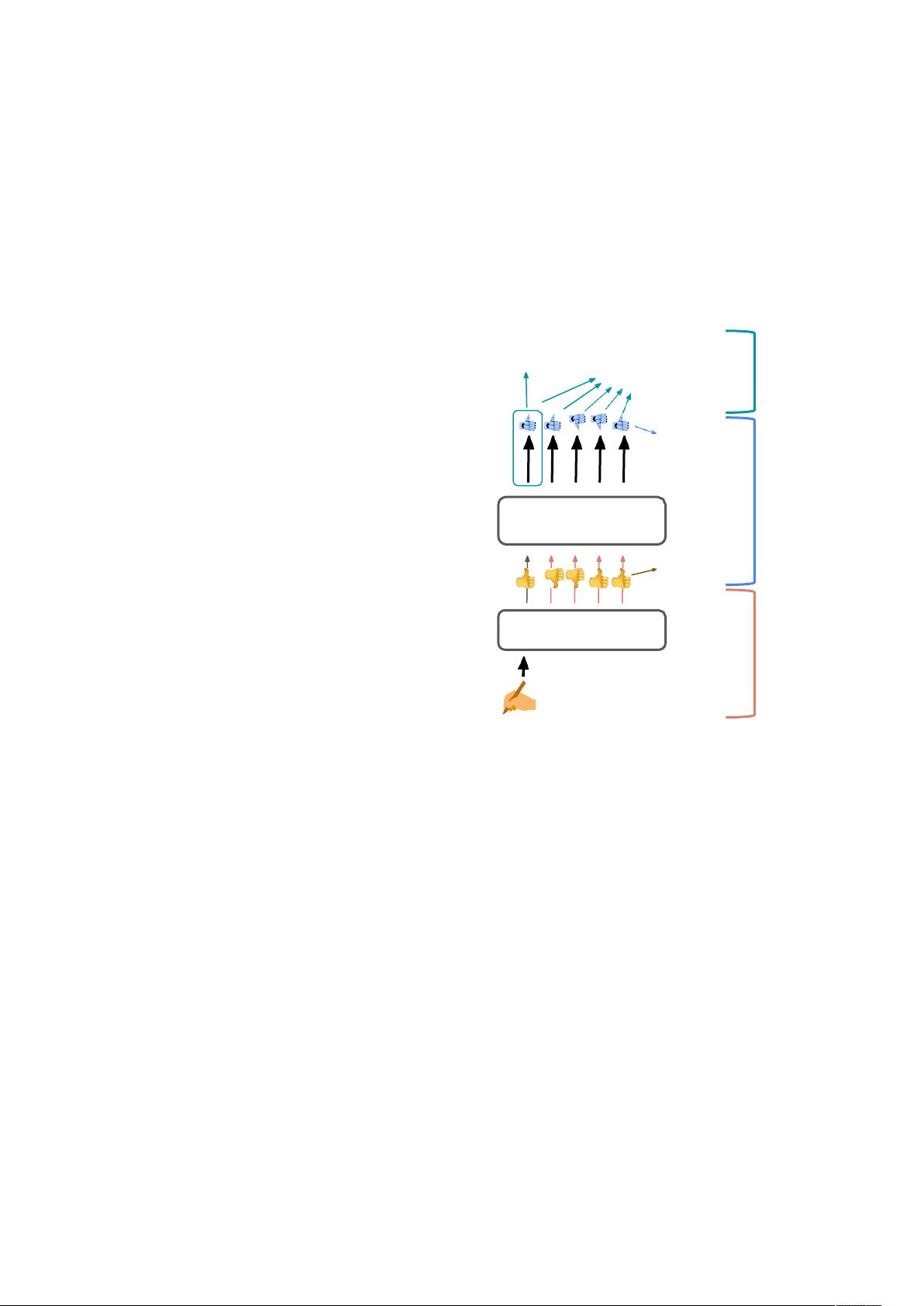
Figure 1: Illustration of our overgeneration + filtra-
tion pipeline for producing human acceptable explana-
tions for CommonsenseQA and SNLI (see examples in
Table 1). Authors of this work write explanations to
prompt GPT-3, generating 5 explanations per instance.
An acceptability filter, trained on human binary accept-
ability judgments, determines which of these generated
explanations are plausible. Evaluation is performed at
both the explanation and the instance level.
However, collecting high-quality written expla-
nations to serve as supervision is difficult and ex-
pensive. More than 70% of existing free-text ex-
planation datasets are crowdsourced (Wiegreffe
and Marasovic´, 2021), and even the most metic-
ulous crowdsourcing efforts frequently fail to elicit
logically consistent and grammatical explanations
(Narang et al., 2020). Furthermore, a lack of
standardized crowdsourcing design has resulted in
highly varied datasets, which are hard to compare
or combine (Tan, 2021).
632
Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics:
Human Language Technologies, pages 632 - 658
July 10-15, 2022 ©2022 Association for Computational Linguistics
GPT-3 DaVinci
top score
Overgenerating Explanation Filtering Acceptable
Evaluation
Candidates
Explanations



剩余26页未读,继续阅读
资源评论


百态老人
- 粉丝: 1w+
- 资源: 2万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP









最新资源
- 手机数据恢复技术及其商业运作模式探析
- 大模型安全实践(2024)
- dotnet-csharp.pdf
- 副业创收策略:高性价比内存卡销售及市场定位分析
- dotnet-csharp-language-reference.pdf
- dotnet-csharp-specification.pdf
- 副业指南之本地流量变现方案:针对宝妈群体的社区团购运营策略
- 负债人群零成本抖音快手知识传播创富指南
- 2021mathorcup数学建模A题论文(后附代码).docx
- 基于SEO优化的高收益写真站点搭建与运营指南
- 基于MATLAB m编程的发动机最优工作曲线计算程序(OOL),在此工作曲线下,发动机燃油消耗最小 hot 文件内含:1、发动机最优工作曲线计算程序m文件;2、发动机万有特性数据excel文件
- 基于Yunzai机器人框架的群互动插件 Gi-plugin 设计源码
- ziyuanaaaaaaaaaa
- 基于Vue框架的JavaScript、TypeScript、CSS网络货运平台移动端小程序设计源码
- 基于HTML、TypeScript、JavaScript的全面运动健康手环App设计源码
- 抖音平台明星周边产品营销策略与获利方法探讨
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


