
ViDA-MAN: Visual Dialog with Digital Humans
Tong Shen
1
, Jiawei Zuo
1
, Fan Shi
1
, Jin Zhang
2
, Liqin Jiang
2
,
Meng Chen
1
, Zhengchen Zhang
1
, Wei Zhang
1
, Xiaodong He
1
, Tao Mei
1
1
JD AI Research, Beijing, China,
2
Migu Culture Technology, Beijing, China
ABSTRACT
We demonstrate ViDA-MAN, a digital-human agent for multi-modal
interaction, which oers realtime audio-visual responses to instant
speech inquiries. Compared to traditional text or voice-based sys-
tem, ViDA-MAN oers human-like interactions (e.g, vivid voice,
natural facial expression and body gestures). Given a speech re-
quest, the demonstration is able to response with high quality
videos in sub-second latency. To deliver immersive user experi-
ence, ViDA-MAN seamlessly integrates multi-modal techniques
including Acoustic Speech Recognition (ASR), multi-turn dialog,
Text To Speech (TTS), talking heads video generation. Backed with
large knowledge base, ViDA-MAN is able to chat with users on a
number of topics including chit-chat, weather, device control, News
recommendations, booking hotels, as well as answering questions
via structured knowledge.
CCS CONCEPTS
• Computing methodologies → Computer vision
;
Natural lan-
guage processing
;
• Human-centered computing → Human
computer interaction (HCI).
KEYWORDS
Multimodal Interaction, Digital Human, Dialog System, Speech
Recognition, Text to Speech, Talking-head Generation
ACM Reference Format:
Tong Shen
1
, Jiawei Zuo
1
, Fan Shi
1
, Jin Zhang
2
, Liqin Jiang
2
,, Meng Chen
1
,
Zhengchen Zhang
1
, Wei Zhang
1
, Xiaodong He
1
, Tao Mei
1
. 2021. ViDA-
MAN: Visual Dialog with Digital Humans. In Proceedings of the 29th ACM
Int’l Conference on Multimedia (MM ’21), Oct. 20–24, 2021, Virtual Event,
China. ACM, New York, NY, USA, 3 pages. https://doi.org/10.1145/3474085.
3478560
1 INTRODUCTION
Digital humans are virtual avatars backed by Articial Intelligence
(AI), which are designed to behave like a real human. Agents pow-
ered by such systems can be applied in a wide range of scenarios
such as personal assistant, customer service and News broadcasting.
In this paper, we present ViDA-MAN, a multi-modal interaction
system for digital humans. The system is complex by nature, inte-
grating multimodal techniques such as ASR, TTS, dialog system,
visual synthesis.
Permission to make digital or hard copies of all or part of this work for personal or
classroom use is granted without fee provided that copies are not made or distributed
for prot or commercial advantage and that copies bear this notice and the full citation
on the rst page. Copyrights for components of this work owned by others than ACM
must be honored. Abstracting with credit is permitted. To copy otherwise, or republish,
to post on servers or to redistribute to lists, requires prior specic permission and/or a
fee. Request permissions from permissions@acm.org.
MM ’21, October 20–24, 2021, Virtual Event, China.
© 2021 Association for Computing Machinery.
ACM ISBN 978-1-4503-8651-7/21/10... $15.00
https://doi.org/10.1145/3474085.3478560
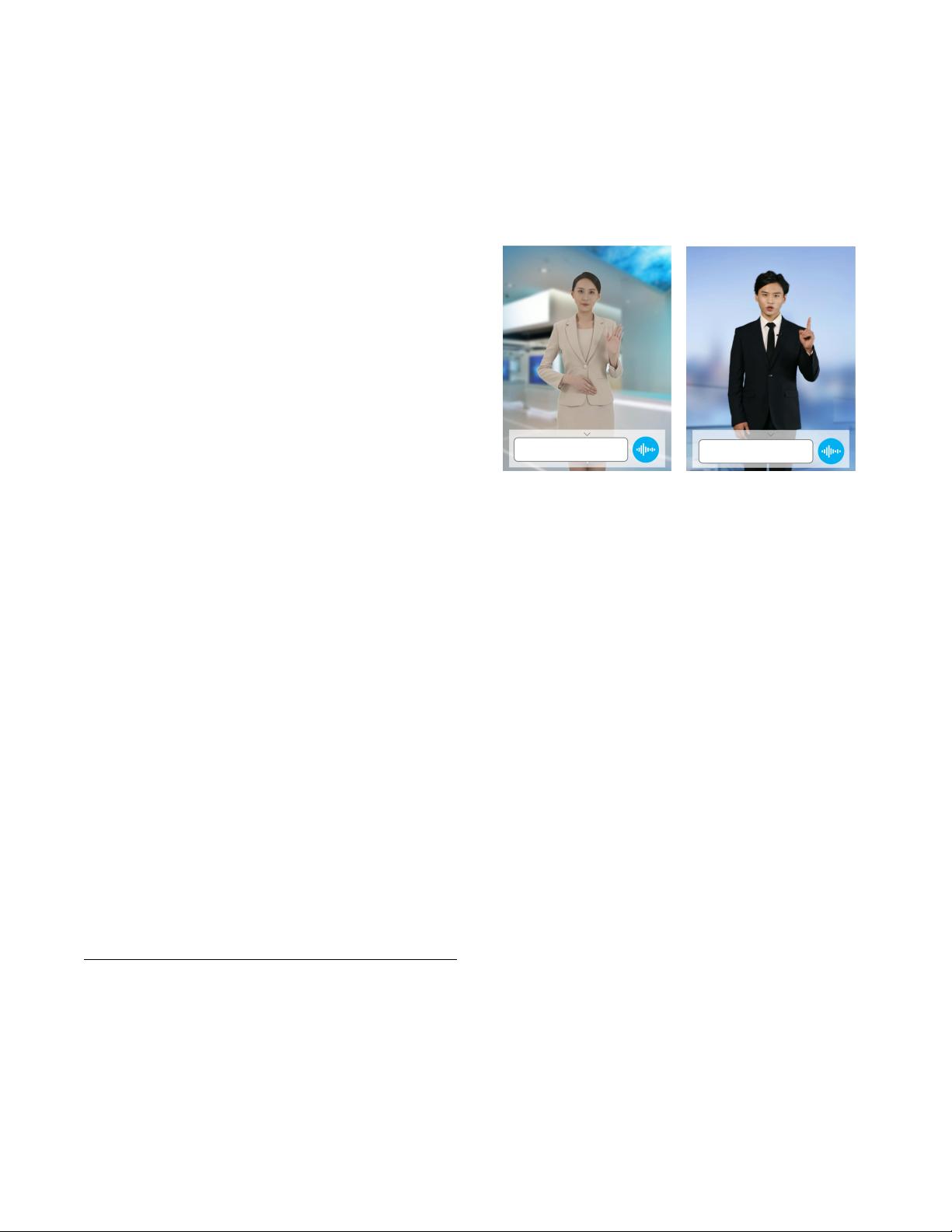
Figure 1: Illustration of our interactive demo. The digital
characters have realistic appearance, voice, natural facial ex-
pression and body motions, oering lifelike interaction ex-
periences.
One of the core parts of a digital human system is the ability
to receive signals from the user and output the corresponding
feedback, which can be viewed as a chatbot. We develop a multi-
type spoken dialogue system that can handle user requests by
multiple dialog skills, such as chit-chat, task-oriented dialog, and
question answering based on knowledge graph.
What makes our ViDA-MAN dierent from a pure chatbot is its
concrete visual appearance and voice, which expresses far more
information than a pure text-based system, e.g. body language
or facial expressions. The voice is empowered by a high quality
TTS system, consisting a novel Duration Informed Auto-regressive
Network (DIAN)[
13
] and a speaker-specic neural vocoder LPCNet.
The appearance is powered by neural rendering techniques [
3
,
5
,
8
–
10
,
15
]. Dierent from a graphics rendering engines [
1
,
2
],
neural renderers do not require a specic high-quality 3D model
and are able to produce far more realistic visual results. Figure 1
demonstrates some examples. In this paper, we present our digital
human system, ViDA-MAN, to draw more attention on multi-modal
interaction systems.
2 SYSTEM ARCHITECTURE
The whole system is designed to pursue low latency and high visual
delity, seeking intelligent and real-time interactions with a lifelike
digital character. As shown in Figure 2, the system mainly consists
of six modules. The system accepts human voice by an ASR module
and feeds it to a dialog system. The response is further translated to
realistic voice using TTS. A driving system and a rendering system
are responsible for updating the appearance. A streaming service
is adopted to integrate everything and encode it into media stream
back to the user.
arXiv:2110.13384v1 [cs.CV] 26 Oct 2021
资源评论


百态老人
- 粉丝: 6952
- 资源: 2万+

下载权益

C知道特权

VIP文章

课程特权
开通VIP









最新资源
- 动物位移小游戏Java实现,强行使用上了SQLite和MyBatis.zip
- 叠罗汉游戏,安卓java实现,自定义Framlayout,属性动画.zip
- java项目实战练习.zip
- java桌面小程序,主要为游戏.zip学习资料
- 2021级大三上学期计算机体系结构-期末大作业复现代码.zip
- ember前端框架,一键部署到云开发平台.zip
- kero is a front-end model framework. - kero是一个前端模型框架,做为MVVM架构中Model层的增强,提供多维数据模型.zip
- PandaUi 是PandaX的前端框架,PandaX 是golang(go)语言微服务开发架构.zip
- v8垃圾回收机制 一篇技术分享文章
- libre后台管理系统前端,使用vue2开发.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


