Andrew Ng
Notation:
m = Number of training examples
x’s = “input” variable / features
y’s = “output” variable / “target” variable
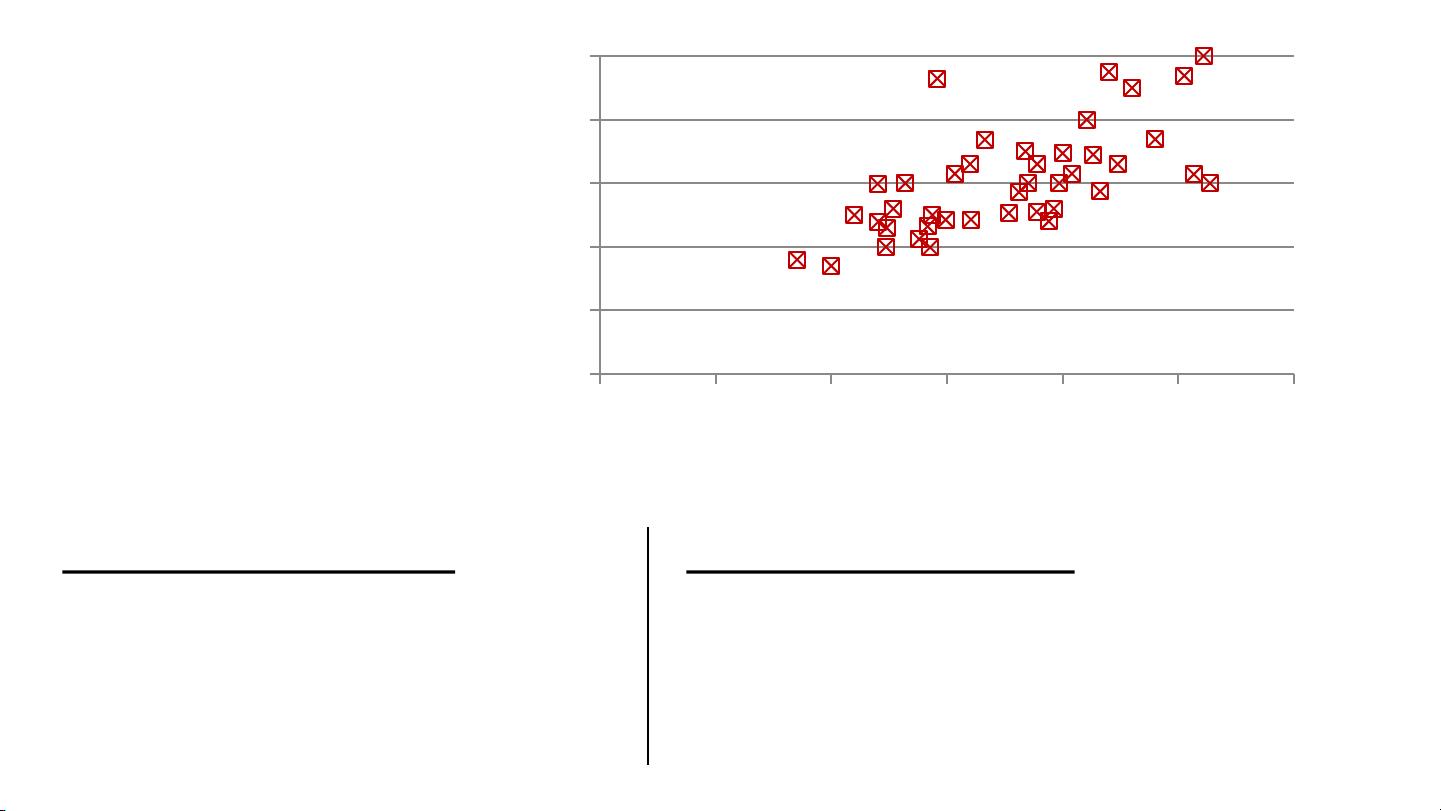
Size in feet
2
(x) Price ($) in 1000's (y)
2104 460
1416 232
1534 315
852 178
… …
Training set of
housing prices
(Portland, OR)