

SPARK SUMMIT
EUROPE
2016
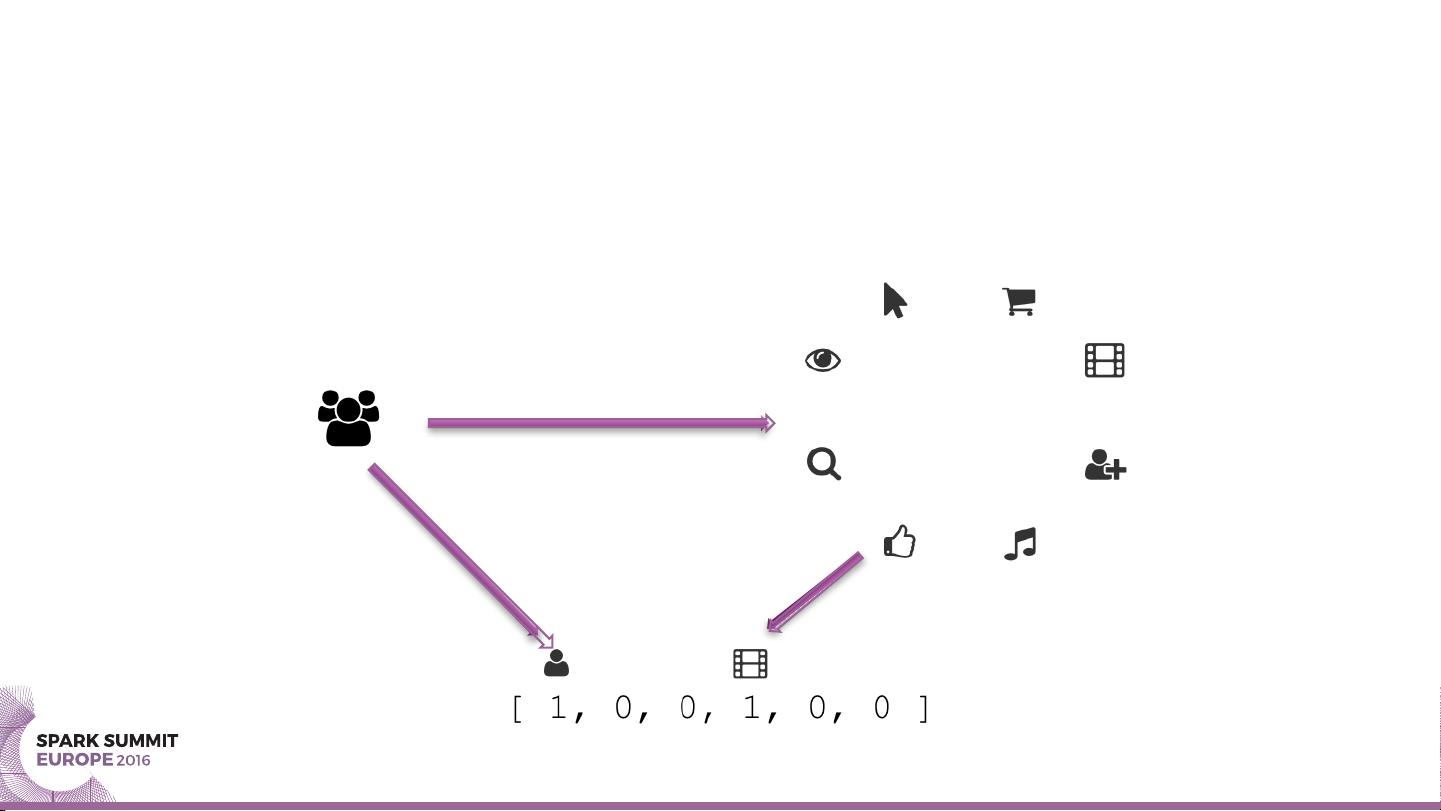
SCALING FACTORIZATION
MACHINES ON APACHE SPARK
WITH PARAMETER SERVERS
Nick Pentreath
Principal Engineer, IBM



剩余30页未读,继续阅读
资源评论


weixin_40191861_zj
- 粉丝: 84
- 资源: 1万+









最新资源
- js基础但是这个烂怂东西要求标题不能少于10个字才能上传然后我其实还没有写完之后再修订吧.md
- electron-tabs-master
- Unity3D 布朗运动算法插件 Brownian Motion
- 鼎微R16中控升级包R16-4.5.10-20170221及强制升级方法
- 鼎微R16中控升级包公版UI 2015及强制升级方法,救砖包
- 基于CSS与JavaScript的积分系统设计源码
- 生物化学作业_1_生物化学作业资料.pdf
- 基于libgdx引擎的Java开发连连看游戏设计源码
- 基于MobileNetV3的SSD目标检测算法PyTorch实现设计源码
- 基于Java JDK的全面框架设计源码学习项目
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


