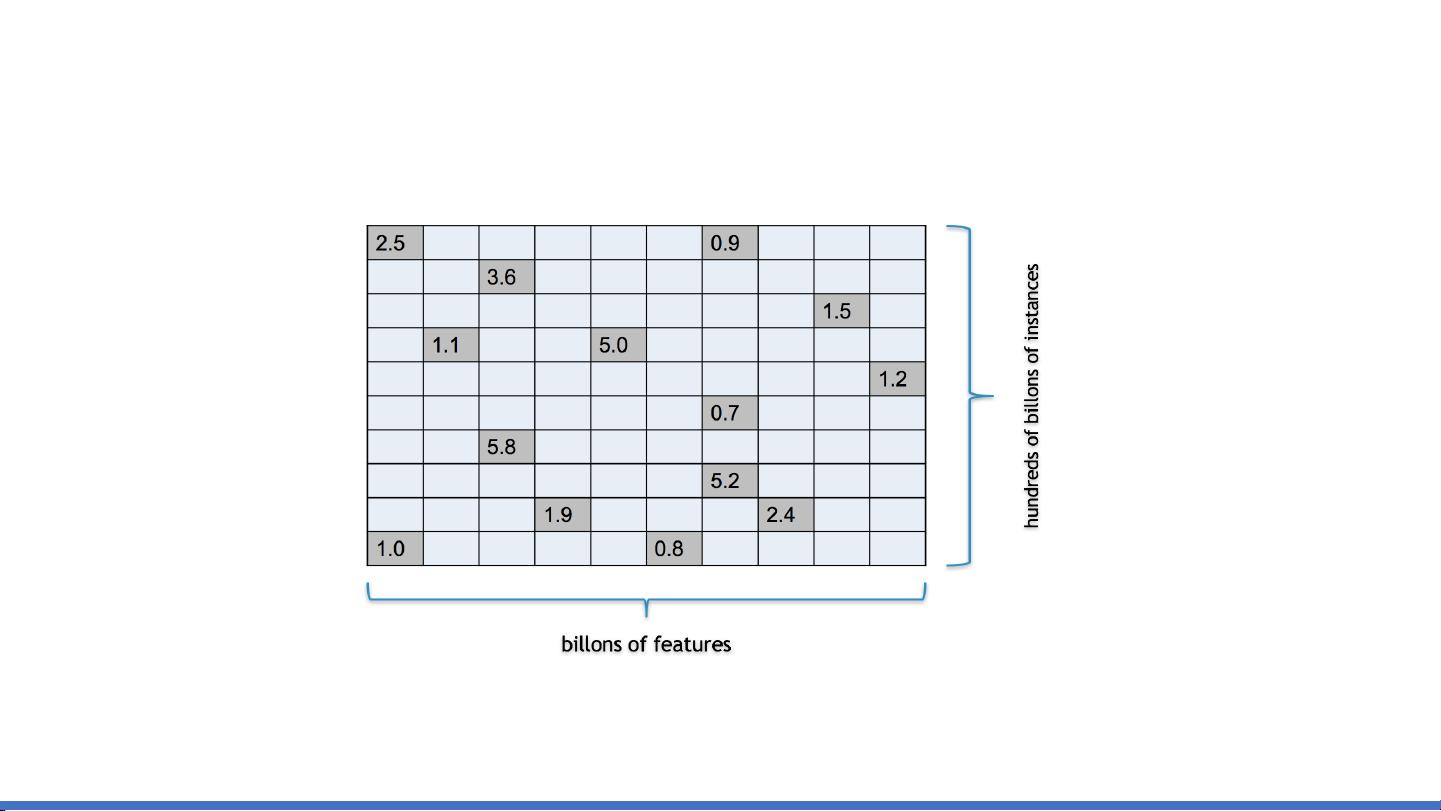
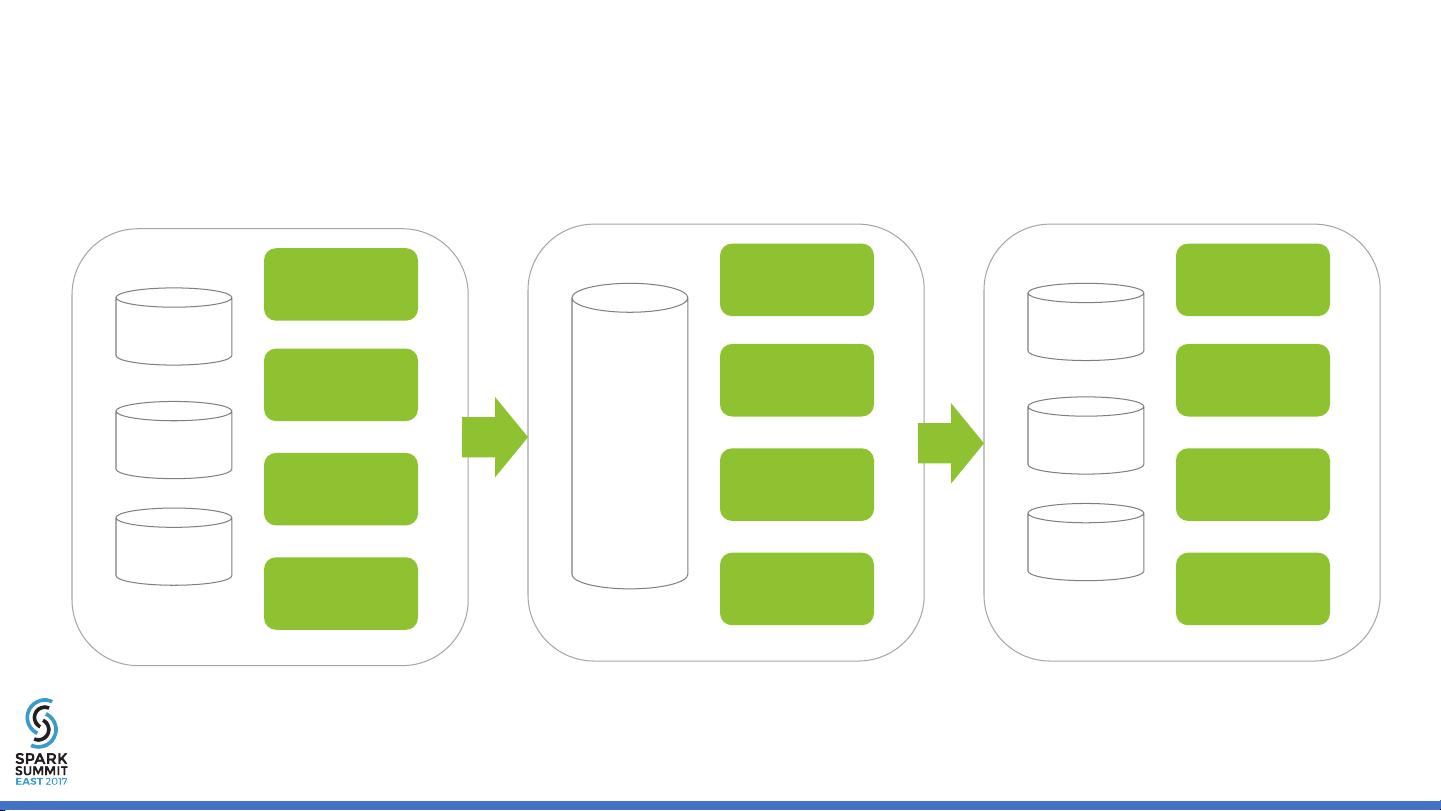
大规模机器学习基于Spark的面向十亿级别特征的知识点 大规模机器学习概述 大规模机器学习是指使用大规模数据集和模型来进行机器学习的过程。这种方法可以提高机器学习模型的准确性和泛化能力。随着大数据的出现,大规模机器学习变得越来越重要。Spark是Apache开源的大数据处理引擎,可以用于大规模机器学习。 基于Spark的大规模机器学习 Spark提供了高效的数据处理能力,可以用于大规模机器学习。Spark MLlib是Spark提供的一个机器学习库,提供了常见的机器学习算法,例如逻辑回归、决策树、Gradient Boosting等。Spark MLlib可以与其他机器学习库集成,例如TensorFlow、PyTorch等。 Vector-free L-BFGS on Spark Vector-free L-BFGS是基于Spark的机器学习算法,可以处理大规模数据集。L-BFGS是Quasi-Newton优化算法的变种,可以用来解决大规模优化问题。Vector-free L-BFGS on Spark可以处理十亿级别特征的大规模机器学习问题。 Logistic Regression on Vector-free L-BFGS 逻辑回归是常见的机器学习算法,可以用于二元分类问题。基于Vector-free L-BFGS on Spark的逻辑回归可以处理大规模数据集,并且可以与其他机器学习算法集成。 CTR Pipeline CTR Pipeline是大规模机器学习的常见应用之一。CTR Pipeline可以用于CTR预测,例如广告点击率预测。CTR Pipeline涉及到多个步骤,例如特征选择、模型训练、模型评估等。 Feature Selection 特征选择是机器学习的重要步骤,目的是选择最相关的特征以提高模型的准确性。Feature Selection可以使用多种方法,例如Filter方法、Wrapper方法、Embedded方法等。 Model Training 模型训练是机器学习的核心步骤,目的是使用训练数据训练模型。模型训练可以使用多种算法,例如Gradient Descent、Stochastic Gradient Descent、Momentum等。 Model Evaluation 模型评估是机器学习的重要步骤,目的是评估模型的性能。模型评估可以使用多种方法,例如Mean Squared Error、Mean Absolute Error、R-Squared等。 Spark的优点 Spark是Apache开源的大数据处理引擎,具有多种优点,例如: * 高效的数据处理能力 * 可扩展性强 * 支持多种编程语言 * 可与其他大数据处理引擎集成 大规模机器学习的挑战 大规模机器学习面临着多种挑战,例如: * 大规模数据集的处理 * 模型的训练和评估 * 硬件资源的限制 * 并行计算的实现 Future Work 未来的大规模机器学习工作包括: * 更好的优化算法 * 更高效的数据处理 * 更好的模型评估方法 * 更好的并行计算方法
剩余44页未读,继续阅读
评论星级较低,若资源使用遇到问题可联系上传者,3个工作日内问题未解决可申请退款~