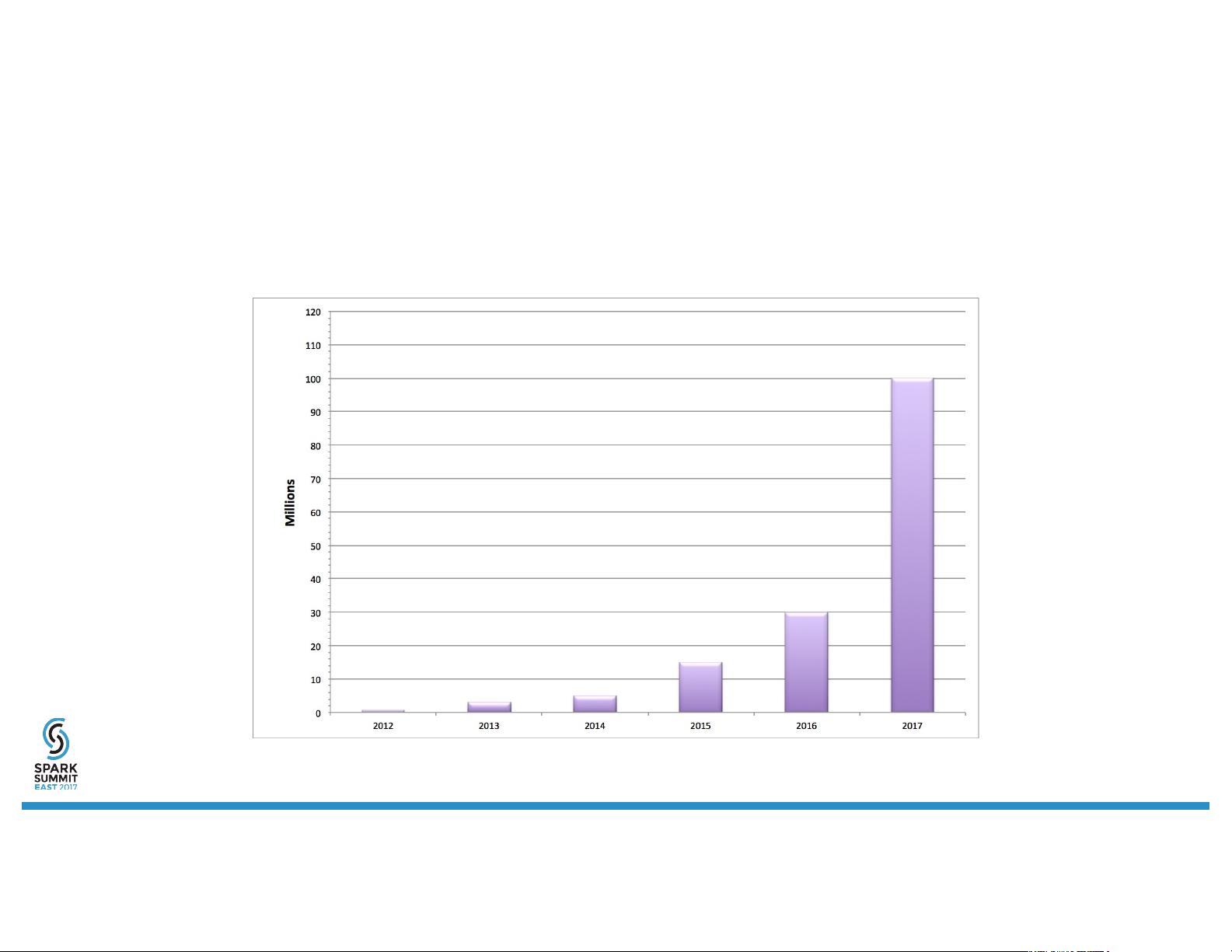
Search growth in last couple of years
• Product Catalog is growing exponentially
• Product updates by merchants happen almost real time
• Price update happens almost real time
• Inventory update happens almost real time
• Data used for relevance signals increased 10 times
• Number of functionalities/business use cases to support increased a lot
• Need for real time analytics increased to analyze data quickly to make faster
business decisions