
【原】十分钟搞定pandas
【原】十分钟搞定【原】十分钟搞定 pandas
本文是对pandas官方网站上《10 Minutes to pandas》的一个简单的翻译,原文在这里。这篇文章是对pandas的一个简单的介绍,详细的
介绍请参考:Cookbook 。习惯上,我们会按下面格式引入所需要的包:
一、一、 创建对象创建对象
可以通过 Data Structure Intro Setion 来查看有关该节内容的详细信息。
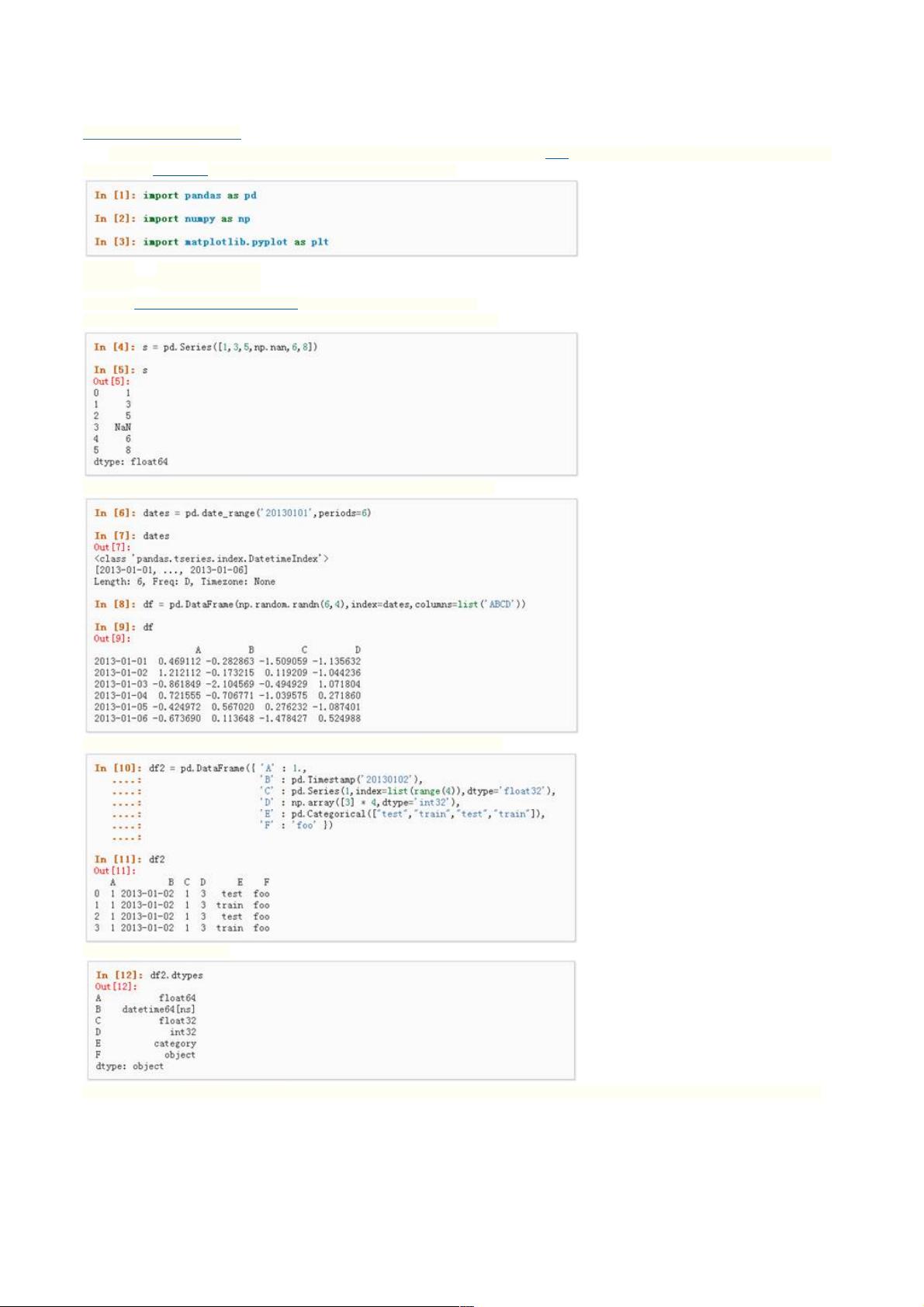
1、可以通过传递一个list对象来创建一个Series,pandas会默认创建整型索引:
2、通过传递一个numpy array,时间索引以及列标签来创建一个DataFrame:
3、通过传递一个能够被转换成类似序列结构的字典对象来创建一个DataFrame:
4、查看不同列的数据类型:
5、如果你使用的是IPython,使用Tab自动补全功能会自动识别所有的属性以及自定义的列,下图中是所有能够被自动识别的属性的一个子集:


剩余13页未读,继续阅读
资源评论

 weixin_436936552019-09-10很适合我这种菜鸟。
weixin_436936552019-09-10很适合我这种菜鸟。












