
RedisCluster分区实现原理分区实现原理
摘要
Redis Cluster本身提供了自动将数据分散到Redis Cluster不同节点的能力,分区实现的关键点问题包括:如何将数据自动地打
散到不同的节点,使得不同节点的存储数据相对均匀;如何保证客户端能够访问到正确的节点和数据;如何保证重新分片的过
程中不影响正常服务。这篇文章通过了解这些问题来认识Redis Cluster分区实现原理。
认识Redis Cluster
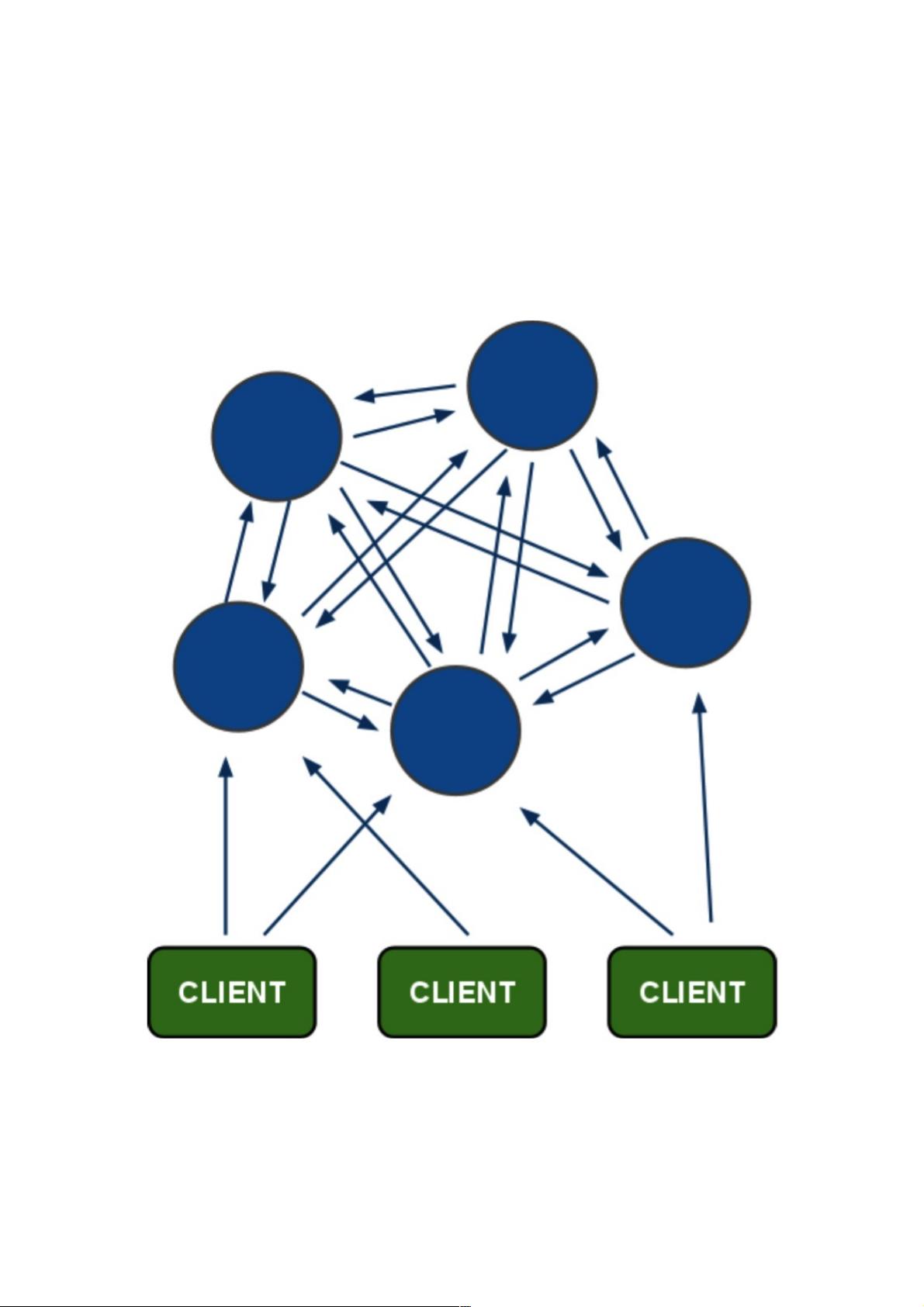
Redis Cluster是由多个同时服务于一个数据集合的Redis实例组成的整体,对于用户来说,用户只关注这个数据集合,而整个
数据集合的某个数据子集存储在哪个节点对于用户来说是透明的。Redis Cluster具有分布式系统的特点,也具有分布式系统如
何实现高可用性与数据一致性的难点,由多个Redis实例组成的Redis Cluster结构通常如下:
Redis Cluster
Redis Cluster特点如下:
所有的节点相互连接;
集群消息通信通过集群总线通信,,集群总线端口大小为客户端服务端口+10000,这个10000是固定值;
节点与节点之间通过二进制协议进行通信;
客户端和集群节点之间通信和通常一样,通过文本协议进行;
资源评论













