自动驾驶中的强化学习:从虚拟到现实
184 浏览量
2021-01-27
12:47:25
上传
评论
收藏 408KB PDF 举报

自动驾驶中的强化学习:从虚拟到现实自动驾驶中的强化学习:从虚拟到现实
1、前言
强化学习(Reinforcement Learning)是机器学习的一个热门研究方向。强化学习较多的研究情景主要在机器人、游戏与棋牌
等方面,自动驾驶的强化学习研究中一大问题是很难在现实场景中进行实车训练。因为强化学习模型需要成千上万次的试错来
迭代训练,而真实车辆在路面上很难承受如此多的试错。
所以目前主流的关于自动驾驶的强化学习研究都集中在使用虚拟驾驶模拟器来进行代理(Agent)的仿真训练,但这种仿真场
景和真实场景有一定的差别,训练出来的模型不能很好地泛化到真实场景中,也不能满足实际的驾驶要求。
加州大学伯克利分校的 Xinlei Pan 等人提出了一种虚拟到现实(Virtual to Real)的翻译网络,可以将虚拟驾驶模拟器中生成
的虚拟场景翻译成真实场景,来进行强化学习训练,取得了更好的泛化能力,并可以迁移学习应用到真实世界中的实际车辆,
满足真实世界的自动驾驶要求。
下面为《Virtual to Real Reinforcement Learning for Autonomous Driving》一文的翻译,编者对文章有一定的概括与删改。
2、简介
强化学习被认为是推动策略学习的一个有前途的方向。然而,在实际环境中进行自动驾驶车辆的强化学习训练涉及到难以负担
的试错。更可取的做法是先在虚拟环境中训练,然后再迁移到真实环境中。本文提出了一种新颖 的现实翻译网络(Realistic
Translation Network),使虚拟环境下训练的模型在真实世界中变得切实可行。提出的网络可以将非真实的虚拟图像输入转换
到有相似场景结构的真实图像。以现实的框架为输入,通过强化学习训练的驾驶策略能够很好地适应真实世界的驾驶。实验表
明,我们提出的虚拟到现实的强化学习效果很好。据我们所知,这是首次通过强化学习训练的驾驶策略可以适应真实世界驾驶
数据的成功案例。
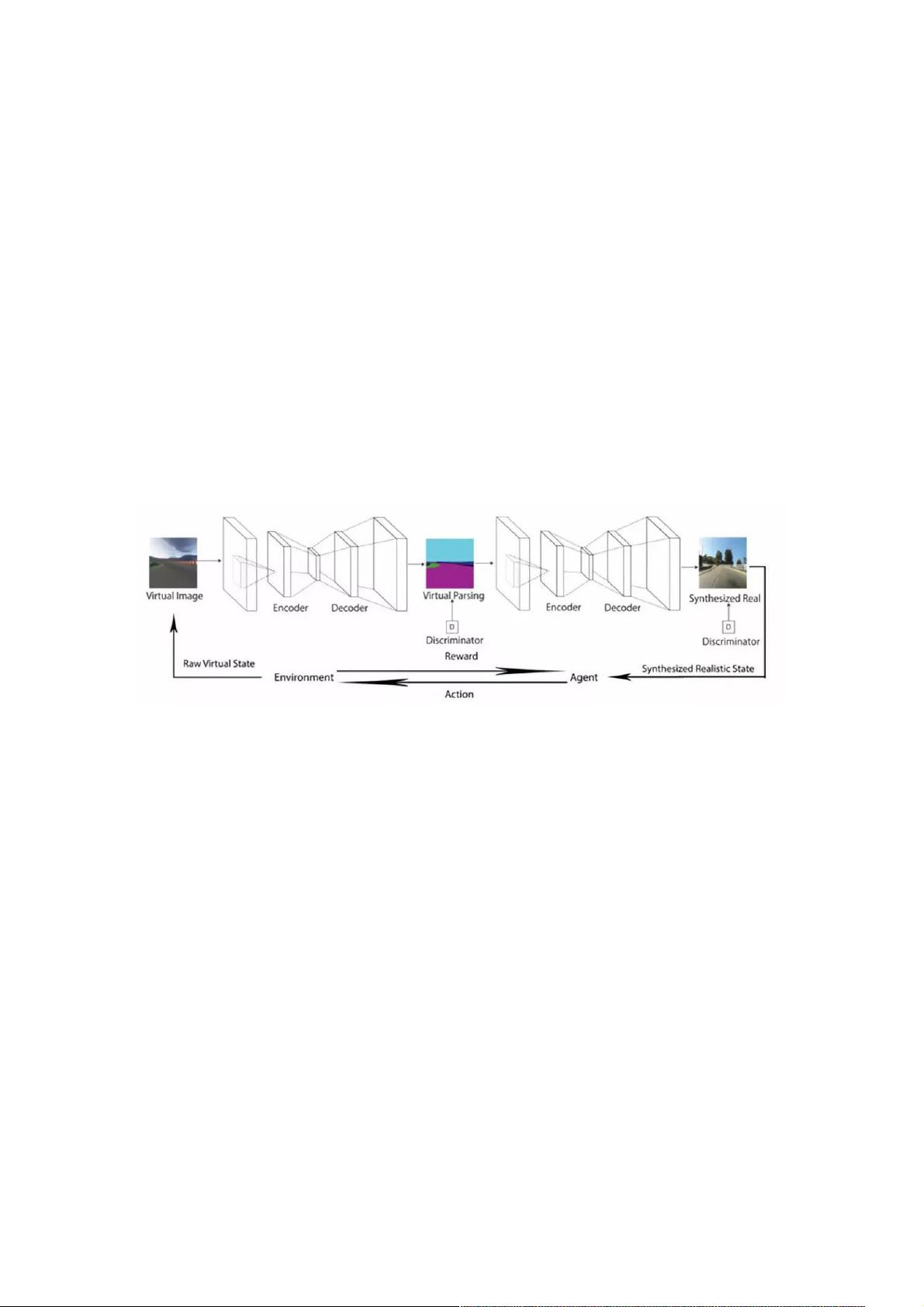
图 1 自动驾驶虚拟到现实强化学习的框架。由模拟器(环境)渲染的虚拟图像首先被分割成场景解析的表现形式,然后通过
提出的图像翻译网络(VISRI)将其翻译为合成的真实图像。代理(Agent)观察合成的真实图像并执行动作。环境会给
Agent 奖励。由于 Agent 是使用可见的近似于真实世界的图像来训练,所以它可以很好地适应现实世界的驾驶。
自动驾驶的目标是使车辆感知它的环境和在没有人参与下的行驶。实现这个目标最重要的任务是学习根据观察到的环境自动输
出方向盘、油门、刹车等控制信号的驾驶策略。最直接的想法是端到端的有监督学习,训练一个神经网络模型直接映射视觉输
入到动作输出,训练数据被标记为图像-动作对。然而,有监督的方法通常需要大量的数据来训练一个可泛化到不同环境的模
型。获得如此大量的数据非常耗费时间且需要大量的人工参与。相比之下,强化学习是通过一种反复试错的方式来学习的,不
需要人工的明确监督。最近,由于其在动作规划方面的专门技术,强化学习被认为是一种有前途的学习驾驶策略的技术。
然而,强化学习需要代理(Agent)与环境的相互作用,不符规则的驾驶行为将会发生。在现实世界中训练自动驾驶汽车会对
车辆和周围环境造成破坏。因此目前的自动驾驶强化学习研究大多集中于仿真,而不是在现实世界中的训练。一个受过强化学
习训练的代理在虚拟世界中可以达到近人的驾驶性能,但它可能不适用于现实世界的驾驶环境,这是因为虚拟仿真环境的视觉
外观不同于现实世界的驾驶场景。
虽然虚拟驾驶场景与真实驾驶场景相比具有不同的视觉外观,但它们具有相似的场景解析结构。例如虚拟和真实的驾驶场景可
能都有道路、树木、建筑物等,尽管纹理可能有很大的不同。因此将虚拟图像翻译成现实图像是合理的,我们可以得到一个在
场景解析结构与目标形象两方面都与真实世界非常相似的仿真环境。最近,生成对抗性网络(GAN)在图像生成方面引起了很
多关注。[1] 等人的工作提出了一种可以用两个域的配对数据将图像从一个域翻译到另一个域的翻译网络的设想。然而,很难
找到驾驶方向的虚拟现实世界配对图像。这使得我们很难将这种方法应用到将虚拟驾驶图像翻译成现实图像的案例中。
本文提出了一个现实翻译网络,帮助在虚拟世界中训练自动驾驶车辆使其完全适应现实世界的驾驶环境。我们提出的框架(如
图 1 所示)将模拟器渲染的虚拟图像转换为真实图像,并用合成的真实图像训练强化学习代理。虽然虚拟和现实的图像有不
同的视觉外观,但它们有一个共同的场景解析表现方式(道路、车辆等的分割图)。因此我们可以用将场景解析的表达作为过
渡方法将虚拟图像转化为现实图像。这种见解类似于自然语言翻译,语义是不同语言之间的过渡。
具体来说,我们的现实翻译网络包括两个模块:
第一个是虚拟解析或虚拟分割模块,产生一个对输入虚拟的图像进行场景解析的表示方式。
第二个是将场景解析表达方式翻译为真实图像的解析到真实网络。通过现实翻译网络,在真实驾驶数据上学习得到的强化学习













评论0