

Fast Online Incremental Learning on Mixture Streaming Data
Yi Wang, Xin Fan, Zhongxuan Luo
School of Software
Dalian University of Technology
& Key Laboratory for Ubiquitous Network
and Service Software of Liaoning Province
Dalian, China
{dlutwangyi, xin.fan, zxluo}@dlut.edu.cn
Tianzhu Wang
No. 254, Deta Leisure Town
Jinzhou New District
Dalian, China
wangtz@126.com
Maomao Min
School of Software
Dalian University of Technology
Dalian, China
neilfvhv@gmail.com
Jiebo Luo
Department of Computer Science
University of Rochester
Rochester, NY 14627, USA
jluo@cs.rochester.edu
Abstract
The explosion of streaming data poses challenges to fea-
ture learning methods including linear discriminant anal-
ysis (LDA). Many existing LDA algorithms are not effi-
cient enough to incrementally update with samples that se-
quentially arrive in various manners. First, we propose a
new fast batch LDA (FLDA/QR) learning algorithm that
uses the cluster centers to solve a lower triangular system
that is optimized by the Cholesky-factorization. To take ad-
vantage of the intrinsically incremental mechanism of the
matrix, we further develop an exact incremental algorithm
(IFLDA/QR). The Gram-Schmidt process with reorthogonal-
ization in IFLDA/QR significantly saves the space and time
expenses compared with the rank-one QR-updating of most
existing methods. IFLDA/QR is able to handle streaming data
containing 1) new labeled samples in the existing classes, 2)
samples of an entirely new (novel) class, and more signifi-
cantly, 3) a chunk of examples mixed with those in 1) and
2). Both theoretical analysis and numerical experiments have
demonstrated much lower space and time costs (2 ∼ 10 times
faster) than the state of the art, with comparable classification
accuracy.
Introduction
Streaming data are explosive with the boom of mobile net-
works, social media, and video cameras in this decade.
To analyze this type of data, an efficient and incremen-
tal learning strategy is necessary. Moreover, these data are
mixed with known or novel class labels, arriving one by
one or chunk by chunk. These characteristics greatly chal-
lenge the existing learning methods. We aim at developing
an extremely fast incremental learning method for mixture
streaming data.
Copyright
c
2017, Association for the Advancement of Artificial
Intelligence (www.aaai.org). All rights reserved.
Classical linear discriminant analysis (LDA) (Chen et al.
2000) and its recent variants (Sharma and Paliwal 2015;
Kong and Ding 2014; Luo, Ding, and Huang 2011) can ef-
fectively extract features for classification. Recently, incre-
mental LDA (ILDA) methods have been emerging to address
the above challenges arisen from streaming data. Some of
these ILDA methods attempt to modify the objective func-
tion, while others use new optimization strategies to accel-
erate the calculation speed. The method of IDR/QR (Ye et
al. 2005) uses the QR-decomposition to update the within-
class scatter matrix (S
w
) and between-class scatter matrix
(S
b
). The methods of ICLDA (Lu, Zou, and Wang 2012),
IDR/new (Lu, Jian, and Wang 2015) and ILDA/QR (Chu et
al. 2015) also follow the idea of using QR-decomposition,
and employ various techniques to reduce the matrix size for
the decomposition. However, their updating schemes, the
key to any incremental algorithms, are not space and time
efficient for online learning.
Researchers also resort to the approximation of scattering
matrices for efficiency improvements. Liu et al. (Liu, Jiang,
and Zhou 2009) give the least-square solution of LDA (LS-
ILDA), but the incrementally update of the pseudo-inverse
of the data matrix is still time consuming. Kim et al. (Kim et
al. 2011) leverage the sufficient spanning set approximation
to S
b
and the total scatter matrix S
t
by updating the princi-
pal eigenvectors and eigenvalues of these two matrices. The
time complexity significantly decreases, but there exists an
evident gap between the accuracies of incremental and batch
versions.
In this paper, we devise an online incremental LDA al-
gorithm that requires much (2 ∼ 10 times) less computa-
tion complexity and smaller space than the state-of-the-art
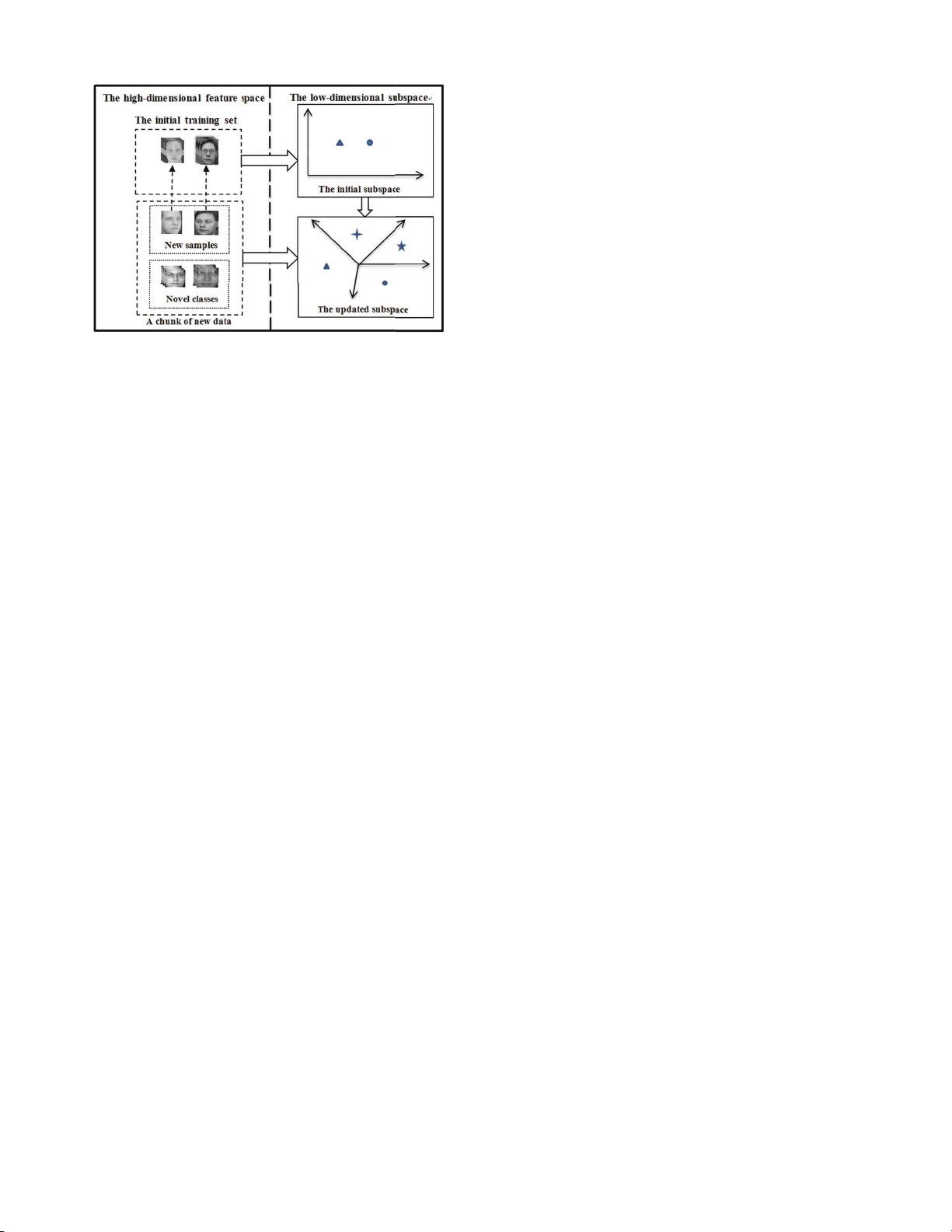
for mixture streaming data. The algorithm is illustrated in
Fig. 1. Specifically, our contributions are twofold:
1. We take advantage of the QR-decomposition on a lower
triangular matrix (Chu et al. 2015), and propose a new
Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence (AAAI-17)
2739
剩余6页未读,继续阅读
资源评论


weixin_38729108
- 粉丝: 5
- 资源: 896









最新资源
- 12-【培训PPT】-25-销售部员工入职培训销售培训技巧.pptx
- 12-【培训PPT】-26-新员工入职安全教育培训.pptx
- 12-【培训PPT】-29-新员工入职学习培训.pptx
- 12-【培训PPT】-28-新员工质量培训PPT.ppt
- weixin小程序项目家庭大厨微信小程序+ssm.zip
- weixin小程序项目家庭事务管理微信小程序+ssm.zip
- Web前端大作业-个人网页设计html+css+javascript(高分项目)
- weixin小程序项目家庭记账本的设计与实现+ssm.zip
- weixin小程序项目家具购物小程序+php.zip
- weixin小程序项目计算机实验室排课与查询系统+ssm.zip
- weixin小程序项目家庭财务管理系统的设计与实现+ssm.zip
- weixin小程序项目基于小程序的购物系统设计与实现+ssm.zip
- weixin小程序项目基于移动平台的远程在线诊疗系统+ssm.zip
- weixin小程序项目基于小程序的老孙电子点菜系统开发设计与实现+ssm.zip
- weixin小程序项目基于微信小程序的网上商城+ssm.zip
- weixin小程序项目基于微信小程序的影院选座系统+ssm.zip
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


