淘宝母婴商品分析-Python

淘宝母婴商品分析淘宝母婴商品分析-Python
1.项目背景:
今年来母婴的消费逐渐增加,这是一份关于淘宝天猫的一份母婴的销售数据。分析该数据集有利于了解目前市场的销售情况,便于做出运营决策,提高销
售额。
数据集来自天池:https://tianchi.aliyun.com/dataset/dataDetail?dataId=45
该数据集有两个表,(sample)sam_tianchi_mum_baby_trade_history.csv包含了:
user_id:用户ID
auction_id:
cat_id:类别ID
cat1:跟类别ID
property:相关属性(这里的数据比较多,直接忽略,不做分析)
buy_mount:购买数量
day:购买日期
表(sample)sam_tianchi_mum_baby.csv:
user_id:用户ID
birthday:出生日期
gender:性别 0:女 ,1:男 , 2:未知
2.分析目的:
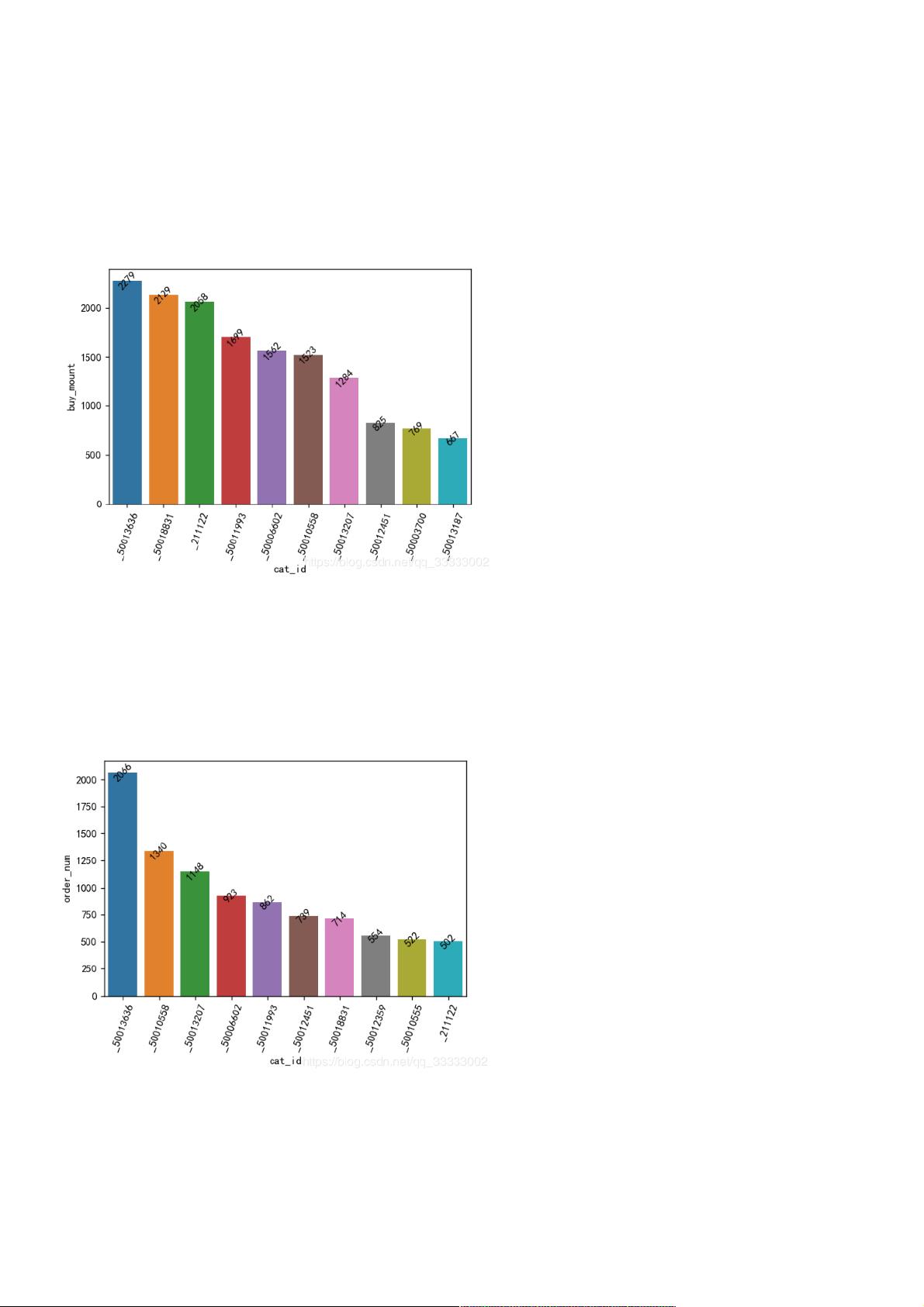
2.1.销售数量前10的的类别ID
2.2.订单量前10的类别ID
2.3.跟类别的销售数量
2.4.跟类别的订单量
2.5.年的销售数量
2.6.年的订单量
2.7.月的销售数量
2.8.月的订单量
2.9.每年各跟类别的销售数量占比
2.10.每年各各跟类别的订单量占比
2.11.用户性别分布情况
2.12.各性别的销售数量
2.13.各性别的订单量
2.14.各性别销售数量中的跟类别占比
2.15.各性别订单量中的跟类别占比
2.16.各年龄层人数分布
2.17.各年龄层销售数量情况
3.数据清洗
3.1导入包和查看数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei'
%matplotlib inline
df = pd.read_csv('./(sample)sam_tianchi_mum_baby_trade_history.csv',
engine='python', parse_dates=['day'])
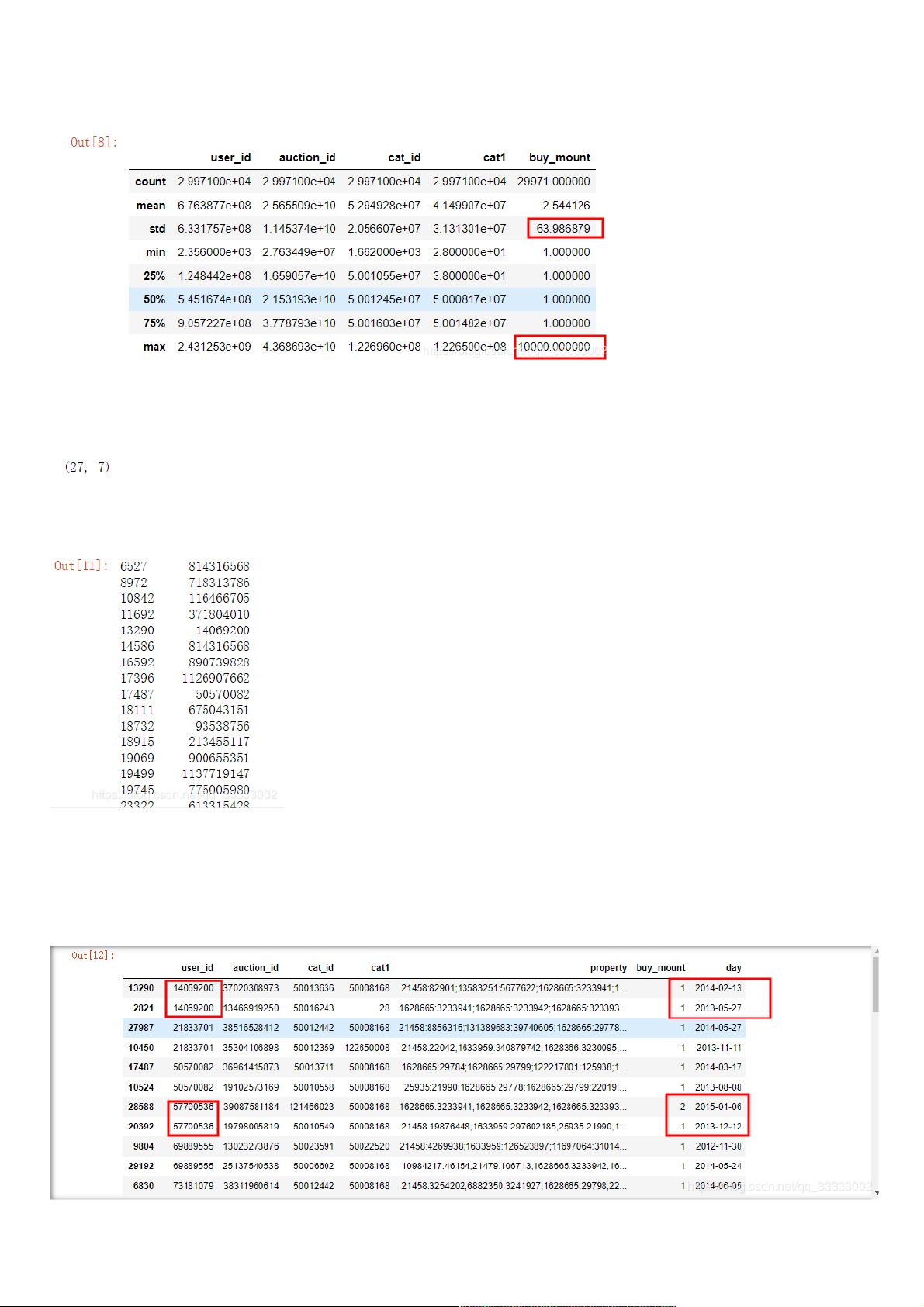
df.shape
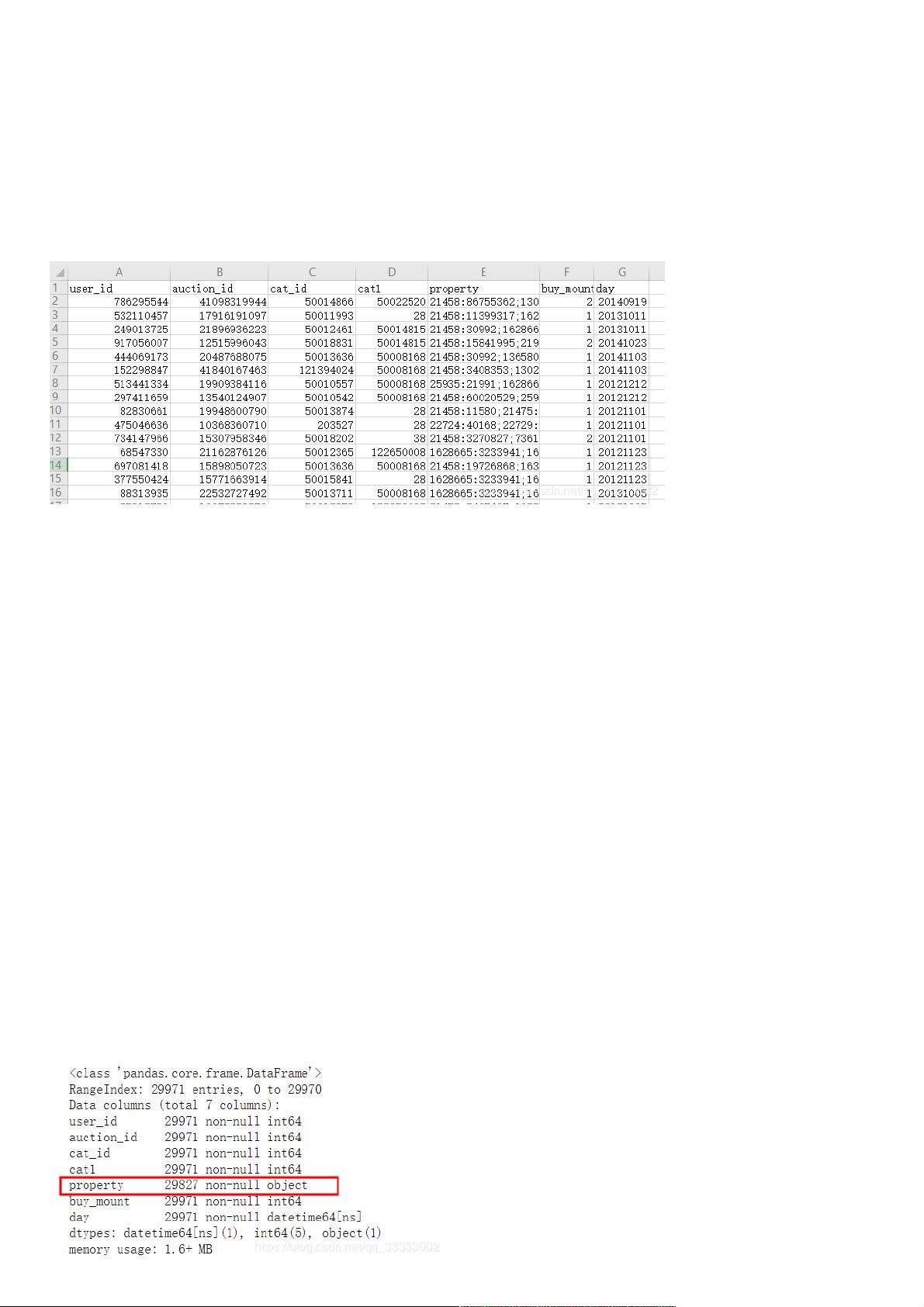
3.2查看列的信息
# 这里只有property这列的数据有异常,只有29827条数据,其他的数据都没异常,
# property这列的数据不做处理,这列的数据较分散,难以分析
df.info()
输出:
剩余12页未读,继续阅读

weixin_38727062
- 粉丝: 4
- 资源: 978












评论5