
Python使用使用PDFMiner解析解析PDF代码实例代码实例
本篇文章主要介绍了Python使用PDFMiner解析PDF代码实例,小编觉得挺不错的,现在分享给大家,也给大家做个参考。一起跟随小编过来看
看吧
近期在做爬虫时有时会遇到网站只提供pdf的情况,这样就不能使用scrapy直接抓取页面内容了,只能通过解析PDF的方式处理,目前的解决方案大致只有pyPDF
和PDFMiner。因为据说PDFMiner更适合文本的解析,而我需要解析的正是文本,因此最后选择使用PDFMiner(这也就意味着我对pyPDF一无所知了)。
首先说明的是解析PDF是非常蛋疼的事,即使是PDFMiner对于格式不工整的PDF解析效果也不怎么样,所以连PDFMiner的开发者都吐槽PDF is evil. 不过这些并
不重要。官方文档在此:http://www.unixuser.org/~euske/python/pdfminer/index.html
一一.安装:安装:
1.首先下载源文件包 http://pypi.python.org/pypi/pdfminer/,解压,然后命令行安装即可:python setup.py install
2.安装完成后使用该命令行测试:pdf2txt.py samples/simple1.pdf,如果显示以下内容则表示安装成功:
Hello World Hello World H e l l o W o r l d H e l l o W o r l d
3.如果要使用中日韩文字则需要先编译再安装:
# make cmap
python tools/conv_cmap.py pdfminer/cmap Adobe-CNS1 cmaprsrc/cid2code_Adobe_CNS1.txtreading 'cmaprsrc/cid2code_Adobe_CNS1.txt'...writing 'CNS1_H.py'......(this may take several minutes)
# python setup.py install
二.使用二.使用
由于解析PDF是一件非常耗时和内存的工作,因此PDFMiner使用了一种称作lazy parsing的策略,只在需要的时候才去解析,以减少时间和内存的使用。要解析
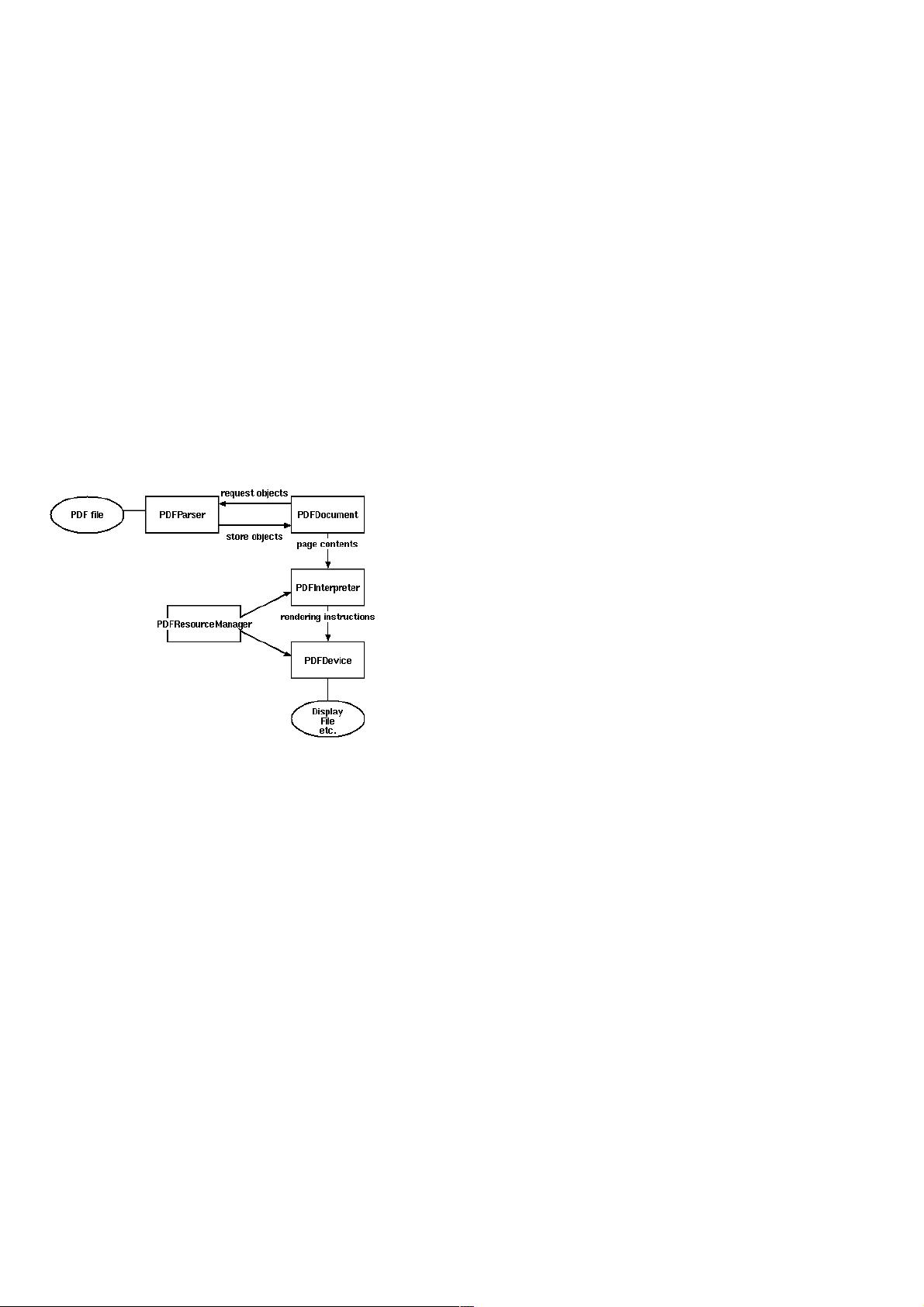
PDF至少需要两个类:PDFParser 和 PDFDocument,PDFParser 从文件中提取数据,PDFDocument保存数据。另外还需要PDFPageInterpreter去处理页面内
容,PDFDevice将其转换为我们所需要的。PDFResourceManager用于保存共享内容例如字体或图片。
Figure 1. Relationships between PDFMiner classes
比较重要的是Layout,主要包括以下这些组件:
LTPage
Represents an entire page. May contain child objects like LTTextBox, LTFigure, LTImage, LTRect, LTCurve and LTLine.
LTTextBox
Represents a group of text chunks that can be contained in a rectangular area. Note that this box is created by geometric analysis and does not necessarily
represents a logical boundary of the text. It contains a list of LTTextLine objects. get_text() method returns the text content.
LTTextLine
Contains a list of LTChar objects that represent a single text line. The characters are aligned either horizontaly or vertically, depending on the text's writing
mode. get_text() method returns the text content.
LTChar
LTAnno
Represent an actual letter in the text as a Unicode string. Note that, while a LTChar object has actual boundaries, LTAnno objects does not, as these are
"virtual" characters, inserted by a layout analyzer according to the relationship between two characters (e.g. a space).
LTFigure
Represents an area used by PDF Form objects. PDF Forms can be used to present figures or pictures by embedding yet another PDF document within a page.
Note that LTFigure objects can appear recursively.
LTImage
Represents an image object. Embedded images can be in JPEG or other formats, but currently PDFMiner does not pay much attention to graphical objects.
LTLine
Represents a single straight line. Could be used for separating text or figures.
LTRect
资源评论


weixin_38723691
- 粉丝: 3
- 资源: 940









最新资源
- 新年主题-3.花生采摘-猴哥666.py
- (6643228)词法分析器 vc 程序及报告
- mysql安装配置教程.txt
- 动手学深度学习(Pytorch版)笔记
- mysql安装配置教程.txt
- mysql安装配置教程.txt
- 彩页资料 配变智能环境综合监控系统2025.doc
- 棉花叶病害图像分类数据集5类别:健康的、蚜虫、粘虫、白粉病、斑点病(9000张图片).rar
- (176205830)编译原理 词法分析器 lex词法分析器
- 使用Python turtle库绘制哈尔滨亚冬会特色图像-含可运行代码及详细解释
- 2023年全国职业院校技能大赛GZ033大数据应用开发赛题答案(2).zip
- 【天风证券-2024研报-】水利部发布《对‘水利测雨雷达’的新质生产力研究》,重点推荐纳睿雷达.pdf
- 【国海证券-2024研报-】海外消费行业周更新:LVMH中国市场挑战严峻,泉峰控股发布盈喜.pdf
- 【招商期货-2024研报-】2024、25年度新疆棉花调研专题报告:北疆成本倒挂,南疆出现盘面利润.pdf
- 【宝城期货-2024研报-】宝城期货股指期货早报:IF、IH、IC、IM.pdf
- 【国元证券(香港)-2024研报-】即时点评:9月火电和风电增速加快,电力运营商盈利有望改善.pdf
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


