
Java 堆排序实例堆排序实例(大顶堆、小顶堆大顶堆、小顶堆)
下面小编就为大家分享一篇Java 堆排序实例(大顶堆、小顶堆),具有很好的参考价值,希望对大家有所帮助。
一起跟随小编过来看看吧
堆排序(堆排序(Heapsort))是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积
的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
堆排序的平均时间复杂度为Ο(nlogn) 。
算法步骤:算法步骤:
1. 创建一个堆H[0..n-1]
2. 把堆首(最大值)和堆尾互换
3. 把堆的尺寸缩小1,并调用shift_down(0),目的是把新的数组顶端数据调整到相应位置
4. 重复步骤2,直到堆的尺寸为1
堆:堆:
堆实际上是一棵完全二叉树,其任何一非叶节点满足性质: Key[i]<=key[2i+1]&&Key[i]<=key[2i+2]或者
Key[i]>=Key[2i+1]&&key>=key[2i+2] 即任何一非叶节点的关键字不大于或者不小于其左右孩子节点的关键字。 堆分为大顶堆
和小顶堆,满足Key[i]>=Key[2i+1]&&key>=key[2i+2]称为大顶堆,满足 Key[i]<=key[2i+1]&&Key[i]<=key[2i+2]称为小顶堆。由
上述性质可知大顶堆的堆顶的关键字肯定是所有关键字中最大的,小顶堆的堆顶的关键字是所有关键字中最小的。
堆排序思想:堆排序思想:
利用大顶堆(小顶堆)堆顶记录的是最大关键字(最小关键字)这一特性,使得每次从无序中选择最大记录(最小记录)变得简单。
其基本思想为(大顶堆): 1)将初始待排序关键字序列(R1,R2….Rn)构建成大顶堆,此堆为初始的无序区; 2)将堆顶元素R[1]与
最后一个元素R[n]交换,此时得到新的无序区(R1,R2,……Rn-1)和新的有序区(Rn),且满足R[1,2...n-1]<=R[n]; 3)由于交换后新
的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R1,R2,……Rn-1)调整为新堆,然后再次将R[1]与无序区最后一个元素
交换,得到新的无序区(R1,R2….Rn-2)和新的有序区(Rn-1,Rn)。不断重复此过程直到有序区的元素个数为n-1,则整个排序过
程完成。 操作过程如下: 1)初始化堆:将R[1..n]构造为堆; 2)将当前无序区的堆顶元素R[1]同该区间的最后一个记录交换,
然后将新的无序区调整为新的堆。 因此对于堆排序,最重要的两个操作就是构造初始堆和调整堆,其实构造初始堆事实上也
是调整堆的过程,只不过构造初始堆是对所有的非叶节点都进行调整。
一个图示实例一个图示实例
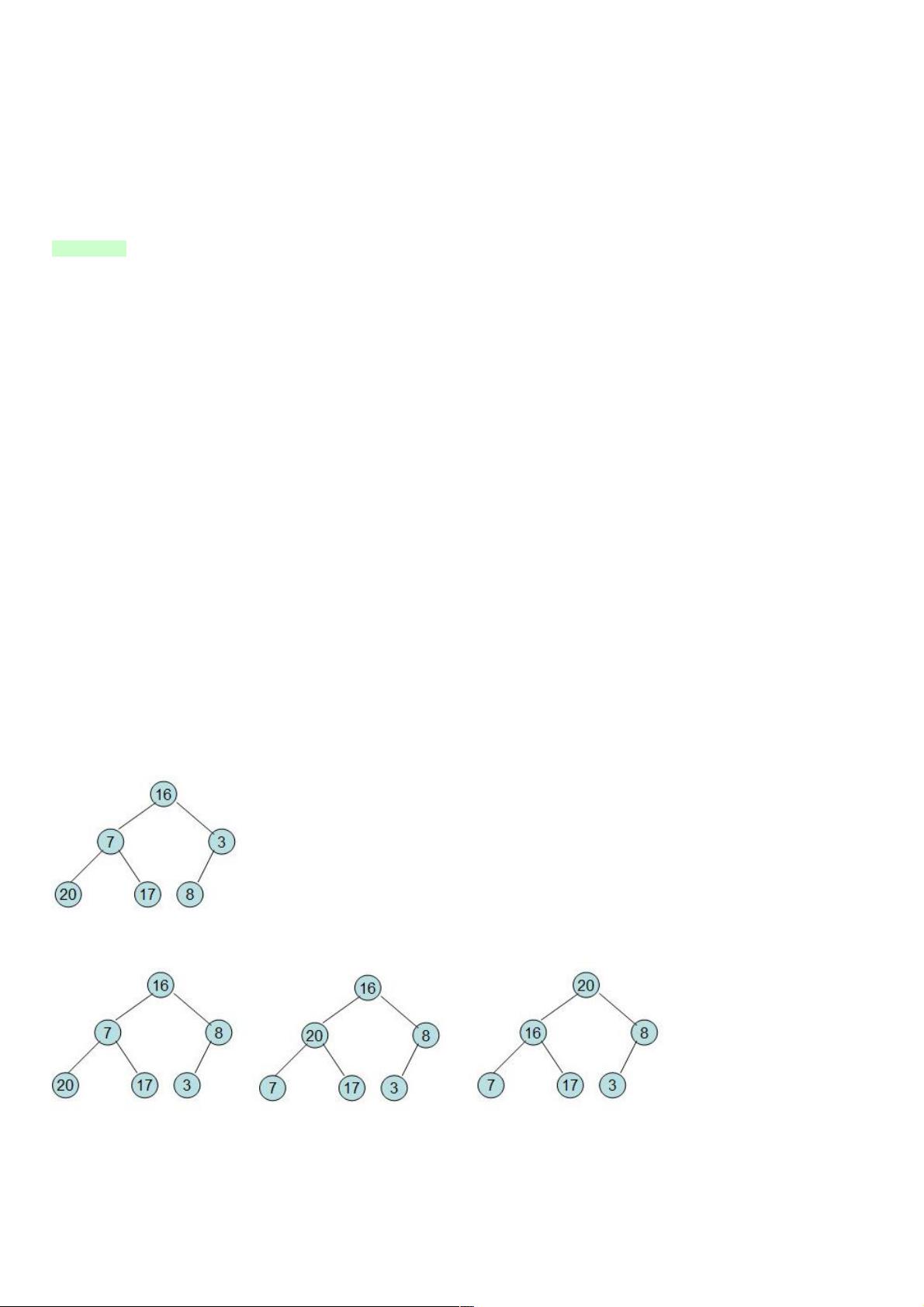
给定一个整形数组a[]={16,7,3,20,17,8},对其进行堆排序。 首先根据该数组元素构建一个完全二叉树,得到
然后需要构造初始堆,则从最后一个非叶节点开始调整,调整过程如下:
20和16交换后导致16不满足堆的性质,因此需重新调整

weixin_38713586
- 粉丝: 3
- 资源: 933









最新资源
- linux学习资料网络服务中继代理
- 锂电池动力极耳成形机(sw17可编辑+工程图)全套技术资料100%好用.zip
- 热门开源java读取Excel项目EasyExcel所需Jar包下载
- 货架031226.fbx
- 使用cuda核函数实现letterbox对比py的letterbox速度差异
- 粒子分料包装系统x_t全套技术资料100%好用.zip
- 使用 C 语言打印简单圣诞树图案的程序示例
- 无功补偿控制器STM32程序 智能电容控制器
- cvi 2013 运行库 恢复体能速腾
- 全球健康统计数据集,供了自2000年以来关于全球健康的综合统计数据,数据集中包含了主要疾病的患病率、发病率和死亡率信息,以及治疗效果和医疗基础设施的有效性
- 可编程加密芯片SMEC80ST SDK开发包
- 迪博内部控制指数及评级数据(2000-2023年).zip
- 电力电子技术中MOS管关断负压尖峰的成因与对策
- C++ 程序示例:控制台打印圣诞树图案
- linux学习资料网络服务FTP
- STM32内部12位ADC智能路灯源程序与Proteus仿真设计
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



- 1
- 2
前往页