

FastRAQ: A Fast Approach to Range-Aggregate
Queries in Big Data Environments
Xiaochun Yun, Member, IEEE, Guangjun Wu, Member, IEEE, Guangyan Zhang,
Keqin Li, and Shupeng Wang
Abstract—Range-aggregate queries are to apply a certain aggregate function on all tuples within given query ranges. Existing
approaches to range-aggregate queries are insufficient to quickly provide accurate results in big data environments. In this paper, we
propose FastRAQ—a fast approach to range-aggregate queries in big data environments. FastRAQ first divides big data into
independent partitions with a balanced partitioning algorithm, and then generates a local estimation sketch for each partition. When a
range-aggregate query request arrives, FastRAQ obtains the result directly by summarizing local estimates from all partitions.
FastRAQ has Oð1Þ time complexity for data updates and Oð
N
PB
Þ time complexity for range-aggregate queries, where N is the number
of distinct tuples for all dimensions, P is the partition number, and B is the bucket number in the histogram. We implement the FastRAQ
approach on the Linux platform, and evaluate its performance with about 10 billions data records. Experimental results demonstrate
that FastRAQ provides range-aggregate query results within a time period two orders of magnitude lower than that of Hive, while the
relative error is less than 3 percent within the given confidence interval.
Index Terms—Balanced partition, big data, multidimensional histogram, range-aggregate query
Ç
1INTRODUCTION
1.1 Motivation
B
IG data analysis can discover trends of various social
aspects and preferences of individual everyday behav-
iours. This provides a new opportunity to explore funda-
mental questions about the complex world [1], [2], [3]. For
example, to build an efficient investment strategy, Preis et al.
[2] analyzed the massive behavioral data sets related to
finance and yielded a profit of even 326 percent higher than
that of a random investment strategy. Choi and Varian [3]
presented estimate sketches to forecast economic indicators,
such as social unemployment, automobile sale, and even
destinations for personal travelling. Currently, it is impor-
tant to provide efficient methods and tools for big data analy-
sis. We give an application example of big data analysis.
Distributed intrusion detection systems (DIDS) monitor and
report anomaly activities or strange patterns on the network
level. A DIDS detects anomalies via statistics information
of summarizing traffic features from diverse sensors to
improve false-alarm rates of detecting coordinated attacks.
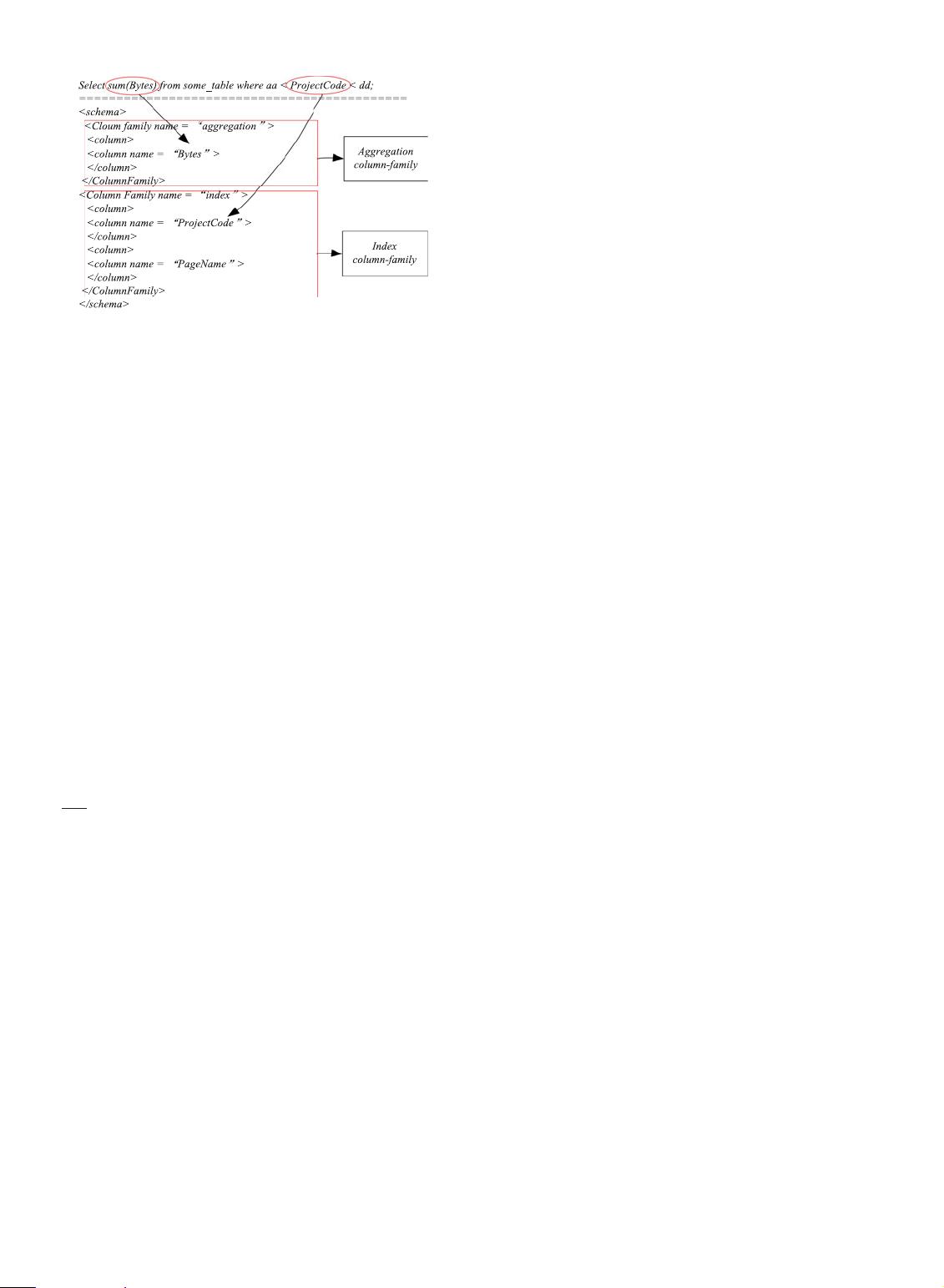
Such a scenario motivates a typical range-aggregate query
problem [4] that summarizes aggregated features from
all tuples within given queried ranges. Range-aggregate
queries are important tools in decision management, online
suggestion, trend estimation, and so on. It is a challenging
problem to quickly obtain range-aggregate queries results in
big data environments. The big data involves a significant
increase in data volumes, and the selected tuples maybe
locate in different files or blocks. On the other hand, real-
time systems aim to provide relevant results within seconds
on massive data analysis [5].
The Prefix-sum Cube (PC) method [4], [6] is first used in
OLAP to boost the performance of range-aggregate queries.
All the numerical attribute values are sorted and any range-
aggregate query on a data cube can be answered in constant
time. However, when a new tuple is written into the cube, it
has to recalculate the prefix sums for all dimensions. Hence,
the update time is even exponential in the number of
cube dimensions. Online Aggregation (OLA) is an important
approximate answering approach to speeding range-aggre-
gate queries [7], which has been widely studied in relational
databases [8] and Cloud systems [9], [10], [11], [12]. The OLA
systems provide early estimated returns while the back-
ground computing processes are still running. The returns
are progressively refined and the accuracy is improved in
subsequent stages. But users cannot obtain an appropriate
answering with satisfied accuracy in the early stages.
The sampling and histogram approaches have been uti-
lized in database environments to support approximate
answering or selectivity estimation. However, it can not
acquire acceptable approximations of the underlying data
sets, when data frequency distributions in different dimen-
sions vary significantly.
1.2 Our Contributions
In this paper, we propose FastRAQ—a new approximate
answering approach that acquires accurate estimations
quickly for range-aggregate queries in big data environments.
X. Yun, G. Wu, and S. Wang are with the Institute of Information Engi-
neering, Chinese Academy of Sciences, Beijing 100029, China.
E-mail: {yunxiaochun, wuguangjun, wangshupeng}@iie.ac.cn.
G. Zhang is with the Department of Computer Science and Technology,
Tsinghua University, Beijing 100084, China.
E-mail: gyzh@tsinghua.edu.cn.
K. Li is with the Department of Computer Science, State University of
New York, New Paltz, NY 12561. E-mail: lik@newpaltz.edu
Manuscript received 24 Feb. 2014; revised 26 June 2014; accepted 27 June
2014. Date of publication 29 July 2014; date of current version 10 June 2015.
Recommended for acceptance by R. Ranjan, L. Wang, A. Zomaya,
D. Georgakopoulos, G. Wang, and X.-H. Sun.
For information on obtaining reprints of this article, please send e-mail to:
reprints@ieee.org, and reference the Digital Object Identifier below.
Digital Object Identifier no. 10.1109/TCC.2014.2338325
206 IEEE TRANSACTIONS ON CLOUD COMPUTING, VOL. 3, NO. 2, APRIL/JUNE 2015
2168-7161 ß 2014 IEEE. Personal use is permitted, but republication/redistribution requires IEEE permission.
See http://www.ieee.org/publications_standards/publications/rights/index.html for more information.
剩余12页未读,继续阅读
资源评论













