

Building a Bw-Tree Takes More Than Just Buzz Words
Ziqi Wang
Carnegie Mellon University
ziqiw@cs.cmu.edu
Andrew Pavlo
Carnegie Mellon University
pavlo@cs.cmu.edu
Hyeontaek Lim
Carnegie Mellon University
hl@cs.cmu.edu
Viktor Leis
TU München
leis@in.tum.de
Huanchen Zhang
Carnegie Mellon University
huanche1@cs.cmu.edu
Michael Kaminsky
Intel Labs
michael.e.kaminsky@intel.com
David G. Andersen
Carnegie Mellon University
dga@cs.cmu.edu
ABSTRACT
In 2013, Microsoft Research proposed the Bw-Tree (humorously
termed the “Buzz Word Tree”), a lock-free index that provides high
throughput for transactional database workloads in SQL Server’s
Hekaton engine. The Bw-Tree avoids locks by appending delta
record to tree nodes and using an indirection layer that allows it to
atomically update physical pointers using compare-and-swap (CaS).
Correctly implementing this techniques requires careful attention
to detail. Unfortunately, the Bw-Tree papers from Microsoft are
missing important details and the source code has not been released.
This paper has two contributions: First, it is the missing guide
for how to build a lock-free Bw-Tree. We clarify missing points in
Microsoft’s original design documents and then present techniques
to improve the index’s performance. Although our focus here is on
the Bw-Tree, many of our methods apply more broadly to designing
and implementing future lock-free in-memory data structures. Our
experimental evaluation shows that our optimized variant achieves
1.1–2.5
×
better performance than the original Microsoft proposal
for highly concurrent workloads. Second, our evaluation shows
that despite our improvements, the Bw-Tree still does not perform
as well as other concurrent data structures that use locks.
ACM Reference Format:
Ziqi Wang, Andrew Pavlo, Hyeontaek Lim, Viktor Leis, Huanchen Zhang,
Michael Kaminsky, and David G. Andersen. 2018. Building a Bw-Tree Takes
More Than Just Buzz Words. In Proceedings of 2018 International Conference
on Management of Data (SIGMOD’18) . ACM, New York, NY, USA, 16 pages.
https://doi.org/10.1145/3183713.3196895
1 INTRODUCTION
Lock-free data structures are touted as being ideal for today’s multi-
core CPUs. They are, however, notoriously dicult to implement
for several reasons [
10
]. First, writing ecient and robust lock-free
1
code requires the developer to gure out all possible race conditions,
the interactions between which can be complex. Furthermore, The
point that concurrent threads synchronize with each other are
1
In this the paper, we always use the term “lock” when referring to “latch”.
Permission to make digital or hard copies of all or part of this work for personal or
classroom use is granted without fee provided that copies are not made or distributed
for prot or commercial advantage and that copies bear this notice and the full citation
on the rst page. Copyrights for components of this work owned by others than ACM
must be honored. Abstracting with credit is permitted. To copy otherwise, or republish,
to post on servers or to redistribute to lists, requires prior specic permission and/or a
fee. Request permissions from permissions@acm.org.
SIGMOD’18, June 10–15, 2018, Houston, TX, USA
© 2018 Association for Computing Machinery.
ACM ISBN 978-1-4503-4703-7/18/06.. . $15.00
https://doi.org/10.1145/3183713.3196895
usually not explicitly stated in the serial version of the algorithm.
Programmers often implement lock-free algorithms incorrectly
and end up with busy-waiting loops. Another challenge is that
lock-free data structures require safe memory reclamation that is
delayed until all readers are nished with the data. Finally, atomic
primitives can be a performance bottleneck themselves if they are
used carelessly.
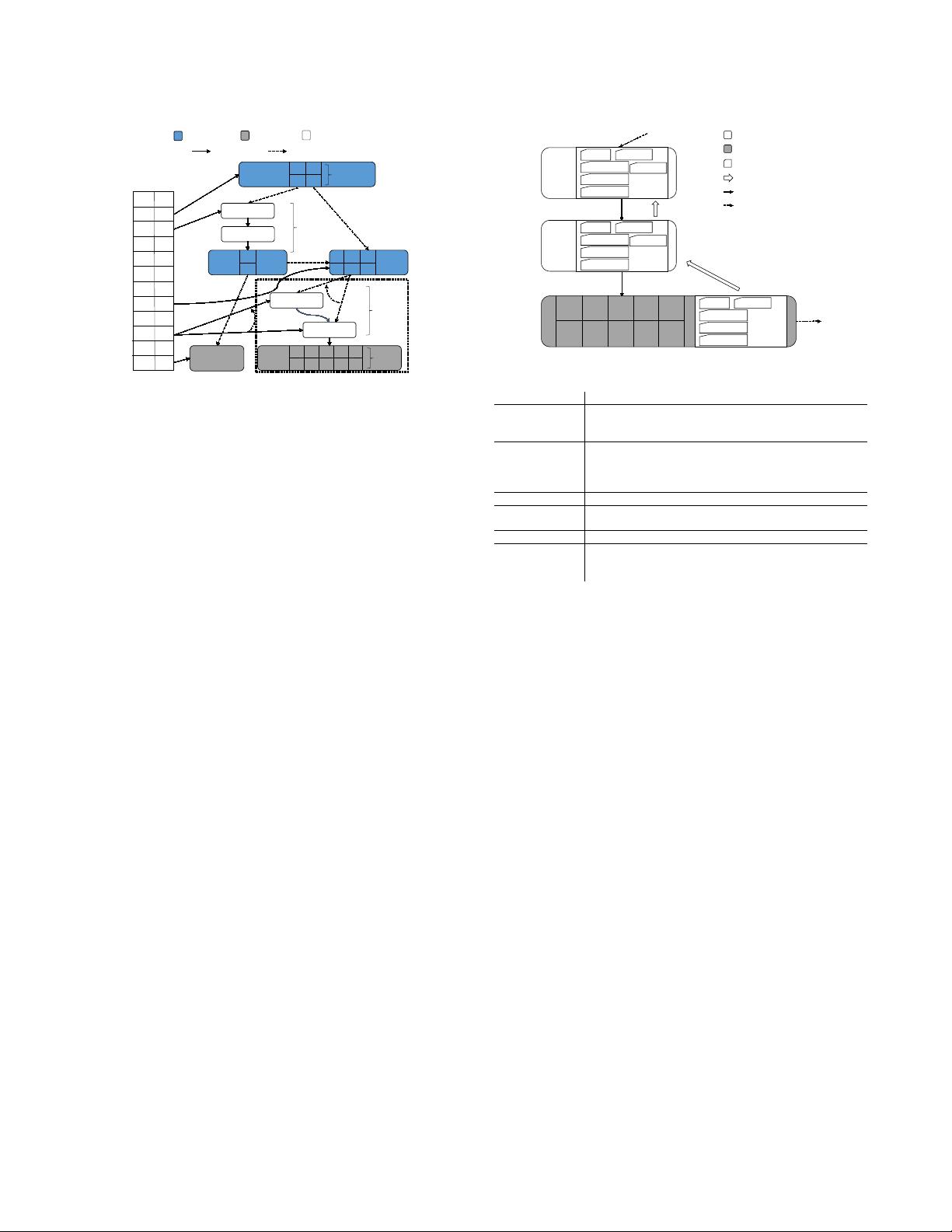
One example of a lock-free data structure is the Bw-Tree from
Microsoft Research [
29
]. The high-level idea of the Bw-Tree is
that it avoids locks by using an indirection layer that maps logical
identiers to physical pointers for the tree’s internal components.
Threads then apply concurrent updates to a tree node by appending
delta records to that node’s modication log. Subsequent operations
on that node must replay these deltas to obtain its current state.
The indirection layer and delta records provide two benets.
First, it avoids coherence trac of locks by decomposing every
global state change into atomic steps. Second, it incurs fewer cache
invalidations on a multi-core CPU because threads append delta
records to make changes to the index instead of overwriting exist-
ing nodes. The original Bw-Tree paper [
29
] claims that this lower
synchronization and cache coherence overhead provides better
scalability than lock-based indexes.
To the best of our knowledge, however, there is no comprehen-
sive evaluation of the Bw-Tree. The original paper lacks detailed
descriptions of critical components and runtime operations. For
example, they do not provide a scalable solution for safe memory
reclamation or ecient iteration. Microsoft’s Bw-Tree may support
these features, but the implementation details are unknown. This
paper aims to be a more thorough investigation of the Bw-Tree: to
supply the missing details, propose improvements, and to provide
a more comprehensive evaluation of the index.
Our rst contribution is a complete design for how to build an
in-memory Bw-Tree. We present the missing features required for a
correct implementation, including important corner cases missing
from the original description of the data structure. We then present
several additional enhancements and optimizations that improve
the index’s performance. The culmination of this eort is our open-
source version called the
OpenBw-Tree
. Our experiments show
that the OpenBw-Tree outperforms what we understand to be the
original Bw-Tree design by 1.1–2.5
×
for insert-heavy workloads
and by 1.1–1.4× for read-heavy workloads.
Our second contribution is to compare the OpenBw-Tree against
four other state-of-the-art in-memory data structures: (1) SkipList [
8
],
(2) Masstree [
31
], (3) a B+Tree with optimistic lock coupling [
22
]
and (4) ART [
20
] with optimistic lock coupling [
22
]. Our results

剩余15页未读,继续阅读
资源评论


weixin_38696458
- 粉丝: 5
- 资源: 919









最新资源
- tomcat6.0配置oracle数据库连接池中文WORD版最新版本
- hibernate连接oracle数据库中文WORD版最新版本
- MyEclipse连接MySQL的方法中文WORD版最新版本
- MyEclipse中配置Hibernate连接Oracle中文WORD版最新版本
- MyEclipseTomcatMySQL的环境搭建中文WORD版3.37MB最新版本
- hggm - 国密算法 SM2 SM3 SM4 SM9 ZUC Python实现完整代码-算法实现资源
- SQLITE操作入门中文WORD版最新版本
- Sqlite操作实例中文WORD版最新版本
- SQLITE特性分析中文WORD版最新版本
- ORACLE创建表空间中文WORD版最新版本
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


