
有赞搜索系统的架构演进有赞搜索系统的架构演进
有赞搜索平台是一个面向公司内部各项搜索应用以及部分 NoSQL 存储应用的 PaaS 产品,帮助应用合理高效的支持检索和多
维过滤功能,有赞搜索平台目前支持了大大小小一百多个检索业务,服务于近百亿数据。
在为传统的搜索应用提供高级检索和大数据交互能力的同时,有赞搜索平台还需要为其他比如商品管理、订单检索、粉丝筛选
等海量数据过滤提供支持,从工程的角度看,如何扩展平台以支持多样的检索需求是一个巨大的挑战。
我是有赞搜索团队的第一位员工,也有幸负责设计开发了有赞搜索平台到目前为止的大部分功能特性,我们搜索团队目前主要
负责平台的性能、可扩展性和可靠性方面的问题,并尽可能降低平台的运维成本以及业务的开发成本。
Elasticsearch
Elasticsearch 是一个高可用分布式搜索引擎,一方面技术相对成熟稳定,另一方面社区也比较活跃,因此我们在搭建搜索系
统过程中也是选择了 Elasticsearch 作为我们的基础引擎。
架构1.0
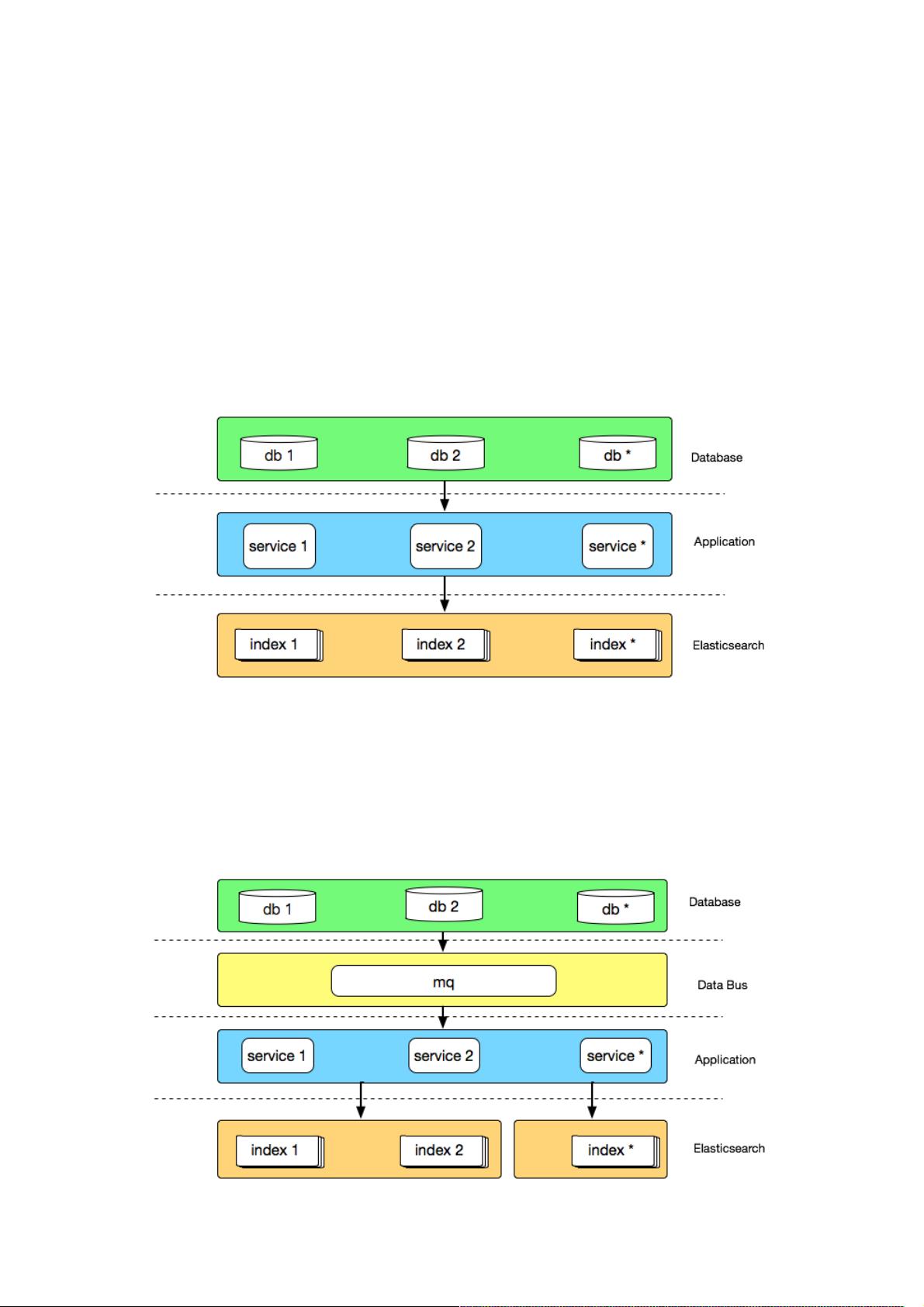
时间回到 2015 年,彼时运行在生产环境的有赞搜索系统是一个由几台高配虚拟机组成的 Elasticsearch 集群,主要运行商品
和粉丝索引,数据通过 Canal 从 DB 同步到 Elasticsearch,大致架构如下:
通过这种方式,在业务量较小时,可以低成本的快速为不同业务索引创建同步应用,适合业务快速发展时期,但相对的每个同
步程序都是单体应用,不仅与业务库地址耦合,需要适应业务库快速的变化,如迁库、分库分表等,而且多个 canal 同时订阅
同一个库,也会造成数据库性能的下降。
另外 Elasticsearch 集群也没有做物理隔离,有一次促销活动就因为粉丝数据量过于庞大导致 Elasticsearch 进程 heap 内存耗
尽而 OOM,使得集群内全部索引都无法正常工作,这给我上了深深的一课。
架构 2.0
我们在解决以上问题的过程中,也自然的沉淀出了有赞搜索的 2.0 版架构,大致架构如下:
首先数据总线将数据变更消息同步到 mq,同步应用通过消费 mq 消息来同步业务库数据,借数据总线实现与业务库的解耦,
引入数据总线也可以避免多个 canal 监听消费同一张表 binlog 的虚耗。
高级搜索(Advanced Search)
资源评论













